6. System Management
This chapter provides information about configuring basic system management parameters.
6.1. System Management Parameters
System management commands allow you to configure basic system management functions such as the system name, the router’s location and coordinates, and Common Language Location Identifier (CLLI) code, as well as time zones, Network Time Protocol (NTP), Simple Network Time Protocol (SNTP) properties, CRON and synchronization properties.
6.1.1. System Information
System information components include the following:
6.1.1.1. System Name
The system name is the MIB II (RFC 1907, Management Information Base for Version 2 of the Simple Network Management Protocol (SNMPv2)) sysName object. By convention, this text string is the fully-qualified domain name of the node. The system name can be any ASCII printable text string up to 32 characters.
6.1.1.2. System Contact
The system contact is the MIB II sysContact object. By convention, this text string is a textual identification of the contact person for this managed node, together with information about how to contact this person.The system contact can be any ASCII printable text string up to 80 characters.
6.1.1.3. System Location
The system location is the MIB II sysLocation object, which is a text string conventionally used to describe the physical location of the node; for example, “Bldg MV-11, 1st Floor, Room 101”. The system location can be any ASCII printable text string up to 80 characters.
6.1.1.4. System Coordinates
The Nokia Chassis MIB tmnxChassisCoordinates object defines the system coordinates. This text string indicates the Global Positioning System (GPS) coordinates of the location of the chassis.
Two-dimensional GPS positioning offers latitude and longitude information as a four dimensional vector:
<direction, hours, minutes, seconds>
where:
direction is one of the four basic values: N, S, W, E
hours ranges from 0 to 180 (for latitude) and 0 to 90 for longitude
minutes and seconds range from 0 to 60.
<W, 122, 56, 89> is an example of longitude and <N, 85, 66, 43> is an example of latitude.
System coordinates can be expressed in different notations; for example:
- N 45 58 23, W 34 56 12
- N37 37' 00 latitude, W122 22' 00 longitude
- N36*39.246' W121*40.121
The system coordinates can be any ASCII printable text string up to 80 characters.
6.1.1.5. Naming Objects
It is discouraged to configure named objects with a name that starts with “tmnx” and with the “_” symbol.
6.1.1.6. CLLI
A CLLI code string for the device is an 11-character standardized geographic identifier that uniquely identifies the geographic location of places and certain functional categories of equipment unique to the telecommunications industry. The CLLI code is stored in the Nokia Chassis MIB tmnxChassisCLLICode object.
The CLLI code can be any ASCII printable text string of up to 11 characters.
6.1.2. System Time
The 7210 SAS routers are equipped with a real-time system clock for time-keeping purposes. When set, the system clock always operates on Coordinated Universal Time (UTC), but the software has options for local time translation and system clock synchronization.
System time parameters include:
6.1.2.1. Time Zones
Setting a time zone allows times to be displayed in the local time rather than in UTC. The supports both user-defined and system-defined time zones.
A user-defined time zone has a user-assigned name of up to four printable ASCII characters that is different from the system-defined time zones. For user-defined time zones, the offset from UTC is configured, as well as any summer time adjustment for the time zone.
The system-defined time zones are listed in Table 28, which includes both time zones with and without summer time correction.
Table 28: System-defined Time Zones
Acronym | Time Zone Name | UTC Offset |
Europe | ||
GMT | Greenwich Mean Time | UTC |
BST | British Summer Time | UTC +1 |
IST | Irish Summer Time | UTC +1* |
WET | Western Europe Time | UTC |
WEST | Western Europe Summer Time | UTC +1 |
CET | Central Europe Time | UTC +1 |
CEST | Central Europe Summer Time | UTC +2 |
EET | Eastern Europe Time | UTC +2 |
EEST | Eastern Europe Summer Time | UTC +3 |
MSK | Moscow Time | UTC +3 |
MSD | Moscow Summer Time | UTC +4 |
US and Canada | ||
AST | Atlantic Standard Time | UTC -4 |
ADT | Atlantic Daylight Time | UTC -3 |
EST | Eastern Standard Time | UTC -5 |
EDT | Eastern Daylight Saving Time | UTC -4 |
ET | Eastern Time | Either as EST or EDT, depending on place and time of year |
CST | Central Standard Time | UTC -6 |
CDT | Central Daylight Saving Time | UTC -5 |
CT | Central Time | Either as CST or CDT, depending on place and time of year |
MST | Mountain Standard Time | UTC -7 |
MDT | Mountain Daylight Saving Time | UTC -6 |
MT | Mountain Time | Either as MST or MDT, depending on place and time of year |
PST | Pacific Standard Time | UTC -8 |
PDT | Pacific Daylight Saving Time | UTC -7 |
PT | Pacific Time | Either as PST or PDT, depending on place and time of year |
HST | Hawaiian Standard Time | UTC -10 |
AKST | Alaska Standard Time | UTC -9 |
AKDT | Alaska Standard Daylight Saving Time | UTC -8 |
Australia | ||
AWST | Western Standard Time (e.g., Perth) | UTC +8 |
ACST | Central Standard Time (e.g., Darwin) | UTC +9.5 |
AEST | Eastern Standard/Summer Time (e.g., Canberra) | UTC +10 |
6.1.2.2. Network Time Protocol
The Network Time Protocol (NTP) is defined in RFC 1305, Network Time Protocol (Version 3) Specification, Implementation and Analysis. It allows participating network nodes to keep time more accurately and maintain time in a more synchronized manner between the participating network nodes.
NTP uses stratum levels to define the number of hops from a reference clock. The reference clock is treated as a stratum-0 device that is assumed to be accurate with little or no delay. Stratum-0 servers cannot be used in a network. However, they can be directly connected to devices that operate as stratum-1 servers. A stratum-1 server is an NTP server with a directly-connected device that provides Coordinated Universal Time (UTC), such as a GPS or atomic clock.
The 7210 SAS devices cannot act as stratum-1 servers but can act as stratum-2 devices because a network connection to an NTP server is required.
The higher stratum levels are separated from the stratum-1 server over a network path, thus a stratum-2 server receives its time over a network link from a stratum-1 server. A stratum-3 server receives its time over a network link from a stratum-2 server.
If the internal PTP process is used as a time source for System Time and OAM, it must be specified as a server for NTP. If PTP is specified, the prefer parameter must also be specified. After PTP has established a UTC traceable time from an external grandmaster source, that clock will always be the time source into NTP, even if PTP goes into time holdover.
| Note: Use of the internal PTP time source for NTP promotes the internal NTP server to stratum 1 level. This may impact the NTP network topology. |
The following NTP elements are supported:
- server modeIn this mode, the node advertises the ability to act as a clock source for other network elements. By default, the node will, by default, transmits NTP packets in NTP version 4 mode.
- authentication keysThese keys implement increased security support in carrier and other networks. Both DES and MD5 authentication are supported, as well as multiple keys.
- symmetric active modeIn this mode, the NTP is synchronized with a specific node that is considered more trustworthy or accurate than other nodes carrying NTP in the system. This mode requires that a specific peer is set.
- broadcastIn this mode, the node receives or sends using a broadcast address.
- alert when NTP server is not availableWhen none of the configured servers are reachable on the node, the system reverts to manual timekeeping and issues a critical alarm. When a server becomes available, a trap is issued indicating that standard operation has resumed.
- NTP and SNTPIf both NTP and SNTP are enabled on the node, SNTP transitions to an operationally down state. If NTP is removed from the configuration or shut down, SNTP resumes an operationally up state.
- gradual clock adjustmentBecause several applications (such as Service Assurance Agent (SAA)) can use the clock, if a major adjustment (128 ms or more) is needed, it is performed by programmatically stepping the clock. If a minor (less than 128 ms) adjustment is needed, it is performed by either speeding up or slowing down the clock.
- rate limit events and trapsTo avoid the generation of excessive events and traps the NTP module rate limits the generation of events and traps to three per second. At that point, a single trap is generated to indicate that event and trap squashing is taking place.
6.1.2.3. SNTP Time Synchronization
To synchronize the system clock with outside time sources, the 7210 SAS devices include a Simple Network Time Protocol (SNTP) client. As defined in RFC 2030, SNTP Version 4 is an adaptation of NTP. SNTP typically provides time accuracy within 100 ms of the time source. SNTP can only receive the time from NTP servers; it cannot be used to provide time services to other systems. SNTP is a compact, client-only version of NTP. SNTP does not authenticate traffic.
In the 7210 SAS software, the SNTP client can be configured in both unicast client modes (point-to-point) and broadcast client modes (point-to-multipoint). SNTP should be used only at the extremities of the synchronization subnet. SNTP clients should operate only at the highest stratum (leaves) of the subnet and in configurations where no NTP or SNTP client is dependent on another SNTP client for synchronization. SNTP time servers should operate only at the root (stratum 1) of the subnet and then only in configurations where no other source of synchronization other than a reliable radio clock is available.
6.1.2.4. CRON
The CRON feature supports the SAA functions and time-based policy scheduling to meet time of day requirements. CRON functionality includes the ability to specify the commands to be run, their scheduling, including one-time only functionality (oneshot), interval and calendar functions, and the storage location for the script output. CRON can also specify the relationship between input, output, and schedule. Scheduled reboots, peer turn ups, service assurance agent tests, and OAM events, such as connectivity checks or troubleshooting runs, can also be scheduled.
CRON features are saved to the configuration file.
CRON features run serially with at least 255 separate schedules and scripts. Each instance can support a schedule where the event is repeatedly executed.
The following CRON elements are supported:
- actionThis configures parameters for a script including the maximum amount of time to keep the results from a script run, the maximum amount of time a script may run, the maximum number of script runs to store and the location to store the results.
- scheduleThe schedule function configures the type of schedule to run, including one-time only (oneshot), periodic, or calendar-based runs. All runs are determined by month, day of month or weekday, hour, minute and interval (seconds).
- scriptThe script command opens a new nodal context that contains information about a script.
- time rangeACLs and QoS policy configurations may be enhanced to support time-based matching. CRON configuration includes time-matching with the schedule sub-command. Schedules are based on events; time-range defines an end-time used as a match criteria.
- time of dayTime of Day (TOD) suites are useful when configuring many types of time-based policies or when a large number of SAPs require the same type of TOD changes. The TOD suite may be configured while using specific ingress or egress ACLs or QoS policies, and is an enhancement of the ingress and egress CLI trees.
6.2. High Availability
This section describes the high availability (HA) routing options and features that service providers can use to reduce vulnerability at the network or service provider edge and alleviate the effect of a lengthy outage on IP networks.
| Note: HA with control plane redundancy is only supported on the 7210 SAS-R6 and 7210 SAS-R12. Control plane redundancy is not supported on the 7210 SAS-M, 7210 SAS-Mxp, 7210 SAS-Sx/S 1/10GE, 7210 SAS-Sx 10/100GE, and 7210 SAS-T. |
HA is an important feature in service provider routing systems. The unprecedented growth of IP services and applications in service provider networks is driven by the demand from the enterprise and residential communities. Downtime can be very costly, and, in addition to lost revenue, customer information and business-critical communications can be lost. HA is the combination of continuous uptime over long periods (Mean Time Between Failures (MTBF)) and the speed at which failover or recovery occurs (Mean Time To Repair (MTTR)).
The advantage of HA routing is evident at the network or service provider edge, where thousands of connections are hosted. Rerouting options around a failed piece of equipment are often limited, or, a single access link exists to a customer because of the additional cost of redundant links. As service providers converge business-critical services, such as real-time voice (VoIP), video, and VPN applications over their IP networks, the requirements for HA become more stringent compared to the requirements for best-effort data.
Network and service availability become critical aspects in advanced IP service offerings, which dictate that the IP routers used to build the foundations of these networks must be resilient to component and software outages.
6.2.1. HA Features
As more and more critical commercial applications move to IP networks, providing HA services becomes increasingly important. This section describes HA features for 7210 SAS devices.
6.2.1.1. Redundancy
Redundancy features enable duplication of data elements to maintain service continuation in case of outages or component failure.
6.2.1.1.1. Software Redundancy on 7210 SAS-R6 and 7210 SAS-R12
Software outages are challenging even when baseline hardware redundancy is in place. A balance should be maintained when providing HA routing, otherwise router problems typically propagate not only throughout the service provider network, but also externally to other connected networks that potentially belong to other service providers. This could affect customers on a broad scale. The 7210 SAS-R6 and 7210 SAS-R12 devices support several software availability features that contribute to the percentage of time that a router is available to process and forward traffic.
All routing protocols specify minimum time intervals in which the peer device must receive an acknowledgment before it disconnects the session.
- OSPF default session timeout is approximately 40 seconds. The timeout intervals are configurable.
- BGP default session timeout is approximately 120 seconds. The timeout intervals are configurable.
Therefore, router software must recover faster than the specified time interval to maintain up time.
6.2.1.1.2. Configuration Redundancy on 7210 SAS-R6 and 7210 SAS-R12
Features configured on the active device CFM or CPM are also saved on the standby CFM or CPM. If the active device CFM or CPM fails, these features are brought up on the standby device that takes over the mastership and becomes the active CFM or CPM.
Even with modern modular and stable software, the failure of route processor hardware or software can cause the router to reboot or cause other service impacting events. In the best circumstances, failure leads to the initialization of a redundant route processor, which hosts the standby software configuration, to become the active processor. The following options are available:
- warm standbyThe router image and configuration is already loaded on the standby route processor. However, the standby could still take a few minutes to become effective because it must first reinitialize connections by bringing up Layer 2 connections and Layer 3 routing protocols, and then rebuild the routing tables.
- hot standbyThe router image, configuration, and network state are already loaded on the standby; it receives continual updates from the active route processor and the swap-over is immediate. Newer generation routers, like the 7210 SAS routers have extra processing built into the system so that router performance is not affected by frequent synchronization, which consumes increased system resources.
6.2.1.1.3. Component Redundancy
7210 SAS component redundancy is critical to reducing MTTR for the routing system.
| Note: This feature is supported on all 7210 SAS platforms as described in this document, including those operating in access-uplink mode. |
Component redundancy consists of the following:
- redundant power supplyThe use of 2 power supplies is supported for redundant power supplies. A power module can be removed without impact on traffic when redundant power supplies are in use. The power supply is hot swappable. The 7210 SAS-S 1/10GE platform supports a single fixed non-removable integrated power supply and a hot-swappable power supply.

Note: - On the 7210 SAS-S 1/10GE platform, if the device is booted with a power entry module and there is a power supply, the system detects the power supply. If the device is booted with a power entry module but there is no power supply, the system does not detect the “power-supply type”. This occurrence is reported as none and the PS LED is OFF.
- On the 7210 SAS-S 1/10GE platform, there is no DC input failure detection that is classified separately. In the case of a failure, the system reports the DC power value as “failed.”
- fan moduleFailure of one or more fans does not impact traffic. Failure of a single fan is detected and notified. The fan tray and fan module is hot-swappable.
- On the 7210 SAS-R6 and 7210 SAS-R12, the fan module/tray contains 6 fans.
- On the 7210 SAS-M, 7210 SAS-Mxp, and 7210 SAS-T, the fan module/tray contains 3 fans.
- On the 7210 SAS-Sx 1/10GE, 7210 SAS-S 1/10GE, and 7210 SAS-Sx 10/100GE, the fan module is not supported. The devices contain a fixed set of 3 fans with filters on both sides of the chassis.
- On the 7210 SAS-R6 and 7210 SAS-R12, 2 x Switch Fabric/Control Processor Module (SF/CPM) can be used to provide control plane redundancy with non-stop routing and non-stop services. The SF/CPM is hot-swappable.
6.2.1.1.4. Remote Power Supply on 7210 SAS-Sx 1/10GE Platforms
You can use an external remote power supply (RPS) as the third power supply for the 7210 SAS-Sx 1/10GE copper variants. With an RPS, a common external power supply is used as the redundant power supply for a stack of 7210 SAS-Sx 1/10GE nodes. This provides a cost-effective option to supply power to a stack of units.
Additional configuration is not required to use an RPS on the node. The presence of an RPS is detected automatically, and the show>chassis>power-supply command displays information about the RPS and its status.
For information about installing RPS, refer to the 7210 SAS-Sx/SAS-S RPS Chassis Installation Guide.
6.2.1.1.5. Service Redundancy on 7210 SAS-R6 and 7210 SAS-R12
All service-related statistics are kept during a switchover. Services, SDPs, and SAPs will remain up with a minimum loss of forwarded traffic during a CFM/CPM switchover.
6.2.1.1.6. Accounting Configuration Redundancy on 7210 SAS-R6 and 7210 SAS-R12
When there is a switchover and the standby CFM/CPM becomes active, the accounting servers are checked and if they are administratively up and capable of coming online (media present, and others), the standby is brought online; new accounting files are created at this point. Users must manually copy the accounting records from the failed CFM/CPM.
6.2.1.2. Nonstop Forwarding and Routing on 7210 SAS-R6 and 7210 SAS-R12
In a control plane failure or a forced switchover event, the router continues to forward packets using the existing stale forwarding information. Nonstop forwarding requires clean control plane and data plane separation. Usually the forwarding information is distributed to the IMMs.
6.2.1.2.1. Nonstop Forwarding on 7210 SAS-R6 and 7210 SAS-R12
In a control plane failure or a forced switchover event, the router continues to forward packets using the existing stale forwarding information.
Nonstop forwarding is used to notify peer routers to continue forwarding and receiving packets, even if the route processor (control plane) is not working or is in a switch-over state. Nonstop forwarding requires clean control plane and data plane separation and usually the forwarding information is distributed to the line cards.
This method of availability has both advantages and disadvantages. Nonstop forwarding continues to forward packets using the existing stale forwarding information during a failure. This may cause routing loops and black holes; surrounding routers must adhere to separate extension standards for each protocol. Each vendor must support protocol extensions for router interoperability.
6.2.1.2.2. Nonstop Routing on 7210 SAS-R6 and 7210 SAS-R12
The Nonstop Routing (NSR) feature on 7210 SAS devices ensures that routing neighbors are unaware of a routing process fault. If a fault occurs, a reliable and deterministic activity switch to the inactive control complex occurs; the routing topology and reachability are not affected, even during routing updates. NSR achieves HA through parallelization by maintaining up-to-date routing state information, at all times, on the standby route processor. This is achieved independent of protocols or protocol extensions and provides a more robust solution than graceful restart protocols between network routers.
The NSR implementation on the 7210 SAS routers supports all routing protocols. It allows existing sessions (BGP, LDP, OSPF, and others) to be retained during a CFM or CPM switchover, including the support for MPLS signaling protocols. No change is visible to the peers.
Protocol extensions are not required. There are no interoperability issues and defining protocol extensions for each protocol is not required. Unlike nonstop forwarding and graceful restart, the forwarding information in NSR is always up to date, which eliminates possible black holes or forwarding loops.
Traditionally, addressing HA issues has been patched through nonstop forwarding solutions. The NSR implementation overcomes these limitations by delivering an intelligent, hitless failover solution. This enables a carrier-class foundation for transparent networks that is required to support business IP services backed by stringent SLAs. This level of HA support poses a major issue for conventional routers whose architectural design limits or prevents them from implementing NSR.
6.2.1.3. CPM Switchover on 7210 SAS-R6 and 7210 SAS-R12
During a switchover, system control and routing protocol execution are transferred from the active to the standby CPM.
An automatic switchover may occur under the following conditions:
- a fault condition that causes the active CPM to crash or reboot
- the active CPM is declared down (not responding)
- online removal of the active CPM
A manual switchover may occur under the following conditions:
- To force a switchover from an active CPM to a standby, use the admin redundancy force-switchover command. You can also use the config system switchover-exec and admin redundancy force-switchover now CLI commands to configure a batch file that runs after a failover.
6.3. Temperature Threshold Alarm and Fan Speed
Table 29 lists the over-temperature thresholds for 7210 SAS devices.
Table 29: Over-Temperature Threshold for 7210 SAS Devices
Device Variants | Minimum Temperature (in degrees centigrade) | Maximum Temperature (in degrees centigrade) |
7210 SAS-M | 0 | 58 |
7210 SAS-M 24F 2XFP ETR | -21 | 68 |
7210 SAS-T | 0 | 58 |
7210 SAS-T ETR | -21 | 68 |
7210 SAS-R6 | -1 | 74 |
7210 SAS-R12 | 0 | 96 |
7210 SAS-Mxp | 0 | 76 |
7210 SAS-Mxp ETR | -10 | 80 |
7210 SAS-Sx/S 1/10GE and 7210 SAS-Sx 10/100GE | 0 | 85 |
The 7210 SAS system software controls the fans by monitoring the internal temperature of the chassis. The software manages the fan speed to maintain the internal temperature within operational limits.
6.3.1. Synchronization
This section describes the synchronization between the CPMs or CFMs.
6.3.1.1. Configuration and boot-env Synchronization
Configuration and boot-env synchronization are supported in the admin>redundancy>synchronize and config>redundancy>synchronize contexts.
6.3.1.2. State Database Synchronization
If a new standby CPM or CFM is inserted into the system, it synchronizes with the active CPM or CFM upon a successful boot process.
If the standby CPM or CFM is rebooted, it synchronizes with the active CPM or CFM after a successful boot process.
When configuration or state changes occur, an incremental synchronization is conducted from the active CPM or CFM to the standby CPM or CFM.
If the synchronization fails, the standby CPM or CFM does not reboot automatically. Use the show redundancy synchronization command to display synchronization output information.
If the active and standby CPMs or CFMs are not synchronized for any reason, you can manually synchronize the standby CPM or CFM by rebooting the standby by issuing the admin reboot standby command on the active or the standby CPM or CFM.
6.4. Synchronization and Redundancy
The 7210 SAS-R6 and 7210 SAS-R12, and the 7210 SAS-Sx/S 1/10GE configured in the standalone-VC mode support CPM redundancy. Redundancy methods facilitate system synchronization between the active and standby CPMs so they maintain identical operational parameters, which prevents inconsistencies in the event of a CPM failure.
When automatic system synchronization is enabled for an entity, save or delete file operations that are configured on the primary, secondary or tertiary choices on the active CPM file system are mirrored in the standby CPM file system.
Although software configurations and images can be copied or downloaded from remote locations, synchronization can only occur locally between compact flash drives (cf1: and cf2:).
Synchronization can occur:
- automaticallyAutomatic synchronization is disabled by default. To enable automatic synchronization, run the config>redundancy>synchronize command with the boot-env parameter or the config parameter.When the boot-env parameter is specified, the BOF, boot.ldr, configuration, and image files are automatically synchronized. When the config parameter is specified, only the configuration files are automatically synchronized.Automatic synchronization also occurs whenever the BOF is modified and when an admin>save command is entered with no filename specified.
- manuallyTo execute synchronization manually, run the admin>redundancy> synchronize command with the boot-env parameter or the config parameter.When the boot-env parameter is specified, the BOF, boot.ldr, configuartion, and image files are synchronized. When the config parameter is specified, only the configuration files are synchronized.The following output is an example of information displayed during a manual synchronization of configuration files.A:ALA-12>admin>redundancy# synchronize configSyncing configuration......Syncing configuration.....Completed.A:ALA-12#
6.4.1. Active and Standby Designations on 7210 SAS-R6 and 7210 SAS-R12
Typically, the first Switch Fabric (SF) or CPM card installed in a redundant 7210 SAS-R6 and 7210 SAS-R12 chassis assumes the active CPM role, regardless of whether it is inserted in slot A or B. The next CPM installed in the same chassis then assumes the standby CPM role. If two CPMs are inserted simultaneously (or almost simultaneously) and boot at the same time, preference is given to the CPM installed in slot A.
If only one CPM is installed in a redundant 7210 SAS-R6 and 7210 SAS-R12, it becomes the active CPM regardless of the slot it is installed in.
To visually determine the active and standby designations, the Status LED on the faceplate is lit green (steady) to indicate the active designation. The Status LED on the second CPM faceplate is lit amber to indicate the standby designation.
The following output sample shows that the CPM installed in slot A is acting as the active CPM and the CPM installed in slot B is acting as the standby.
The following console message is displayed if a CPM boots, detects an active CPM, and assumes the role of the standby CPM.
This CPM (slot B) is the standby CPM.
6.4.2. Active and Standby Designations on 7210 SAS-Sx/S 1/10GE in Standalone-VC Mode
On the 7210 SAS-Sx/S 1/10GE configured in the standalone-VC mode, the user must designate and configure two nodes as CPM-IMM nodes. During boot up, one of the configured nodes assumes the active CPM role and the other assumes the standby CPM role. Typically, the configured CPMA-IMM node is favored to be the active CPM and the CPMB-IMM is favored to be the standby CPM. If only one CPM-IMM node is configured, it becomes the active CPM.
To visually determine the active and standby designations, the Master LED on the faceplate is lit (steady) to indicate the active designation. The Master LED on the standby CPM faceplate blinks to indicate the standby designation.
The following output sample shows two nodes configured as CPM-IMM nodes with one becoming the active node and the other becoming the standby node.
When CPM B boots, it waits 60 seconds to detect an active CPM A. If CPM A does not respond after 60 seconds, CPM B assumes the role of the active node.
6.4.3. When the Active CPM Goes Offline
When an active CPM goes offline (due to reboot, removal, or failure), the standby CPM takes control without rebooting or initializing itself. It is assumed that the CPMs are synchronized, therefore, there is no delay in operability. When the CPM that went offline boots and comes back online, it becomes the standby CPM.
The following console message is displayed when the active CPM goes offline and the standby CPM assumes the active role:
6.4.4. Configuration Guidelines for Synchronization of Active and Standby CPM on 7210 SAS-R6 and 7210 SAS-R12
The following configuration guidelines apply when synchronizing the active and standby CPMs on the 7210 SAS-R6 and 7210 SAS-R12 systems.
- The active and standby CPM should boot from same boot drives (cf1:\, cf2:\, or uf:\). For example, if the active CPM is booted from cf1:\, the standby CPM must use cf1:\ to bootup. Although it is possible to make the CPMs operational by booting them using any drive on active and standby, Nokia recommends that the same drives should be used to boot the system.
- The user should ensure that a valid bootstrap image (boot.tim) and BOF (bof.cfg) exist in the cf1:\, cf2:\, or uf1:\ drive of both active and stand-by CPM cards. The user must verify that bof.cfg resides on the same drive as the boot.tim.
- The TiMOS application images (cpm.tim and iom.tim) and the configuration file can reside in any location (local or remote), but the locations in the BOF should be configured identically on both active and standby CPM for primary, secondary, and tertiary locations.
- Boot-env synchronization must be performed before config synchronization. To do so, run the admin redundancy synchronize boot-env command, followed by the admin redundancy synchronize config command.
- Synchronization can only occur locally between compact flash drives cf1:Active to cf1:Standby, cf2:Active to cf2:Standby, and uf1:Active to uf1:Standby. Synchronization across different drives is not supported.
- If the active and standby CPM are not synchronized for some reason, users can manually synchronize the standby CPM by running the admin redundancy synchronize boot-env CLI command, and rebooting the standby CPM by running the admin reboot standby command.
6.5. Network Synchronization
| Note: See the information in this section and refer to the 7210 SAS OS Software Release Notes 11.0Rx for information about network synchronization options supported on each 7210 SAS platform. |
This section describes the network synchronization capabilities available on7210 SAS platforms. These capabilities involve multiple approaches to network timing, including Synchronous Ethernet, PTP/1588v2, adaptive timing, and others. These features address barriers to entry as follows:
- provide synchronization quality required by mobile networks, such as radio operations and circuit emulation services (CES) transport
- augment and potentially replace the existing (SONET/SDH) timing infrastructure and deliver high quality network timing for time-sensitive wireline applications
| Note: Synchronous Ethernet and IEEE1588v2 PTP are not supported on virtual chassis (VCs). |
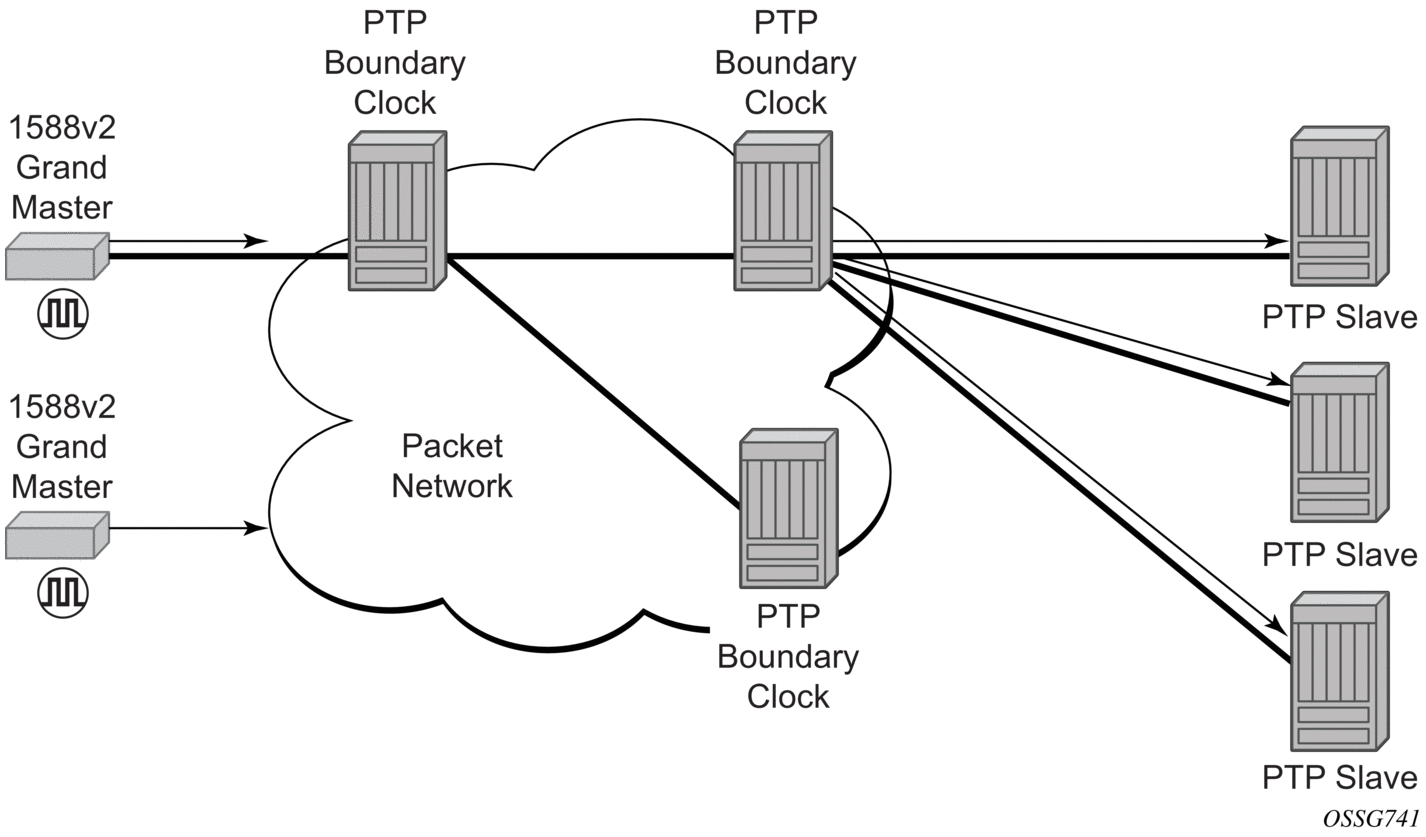
Network synchronization is commonly distributed in a hierarchical master-slave topology at the physical layer, as shown in Figure 23.
Figure 23: Conventional Network Timing Architecture (North American Nomenclature)
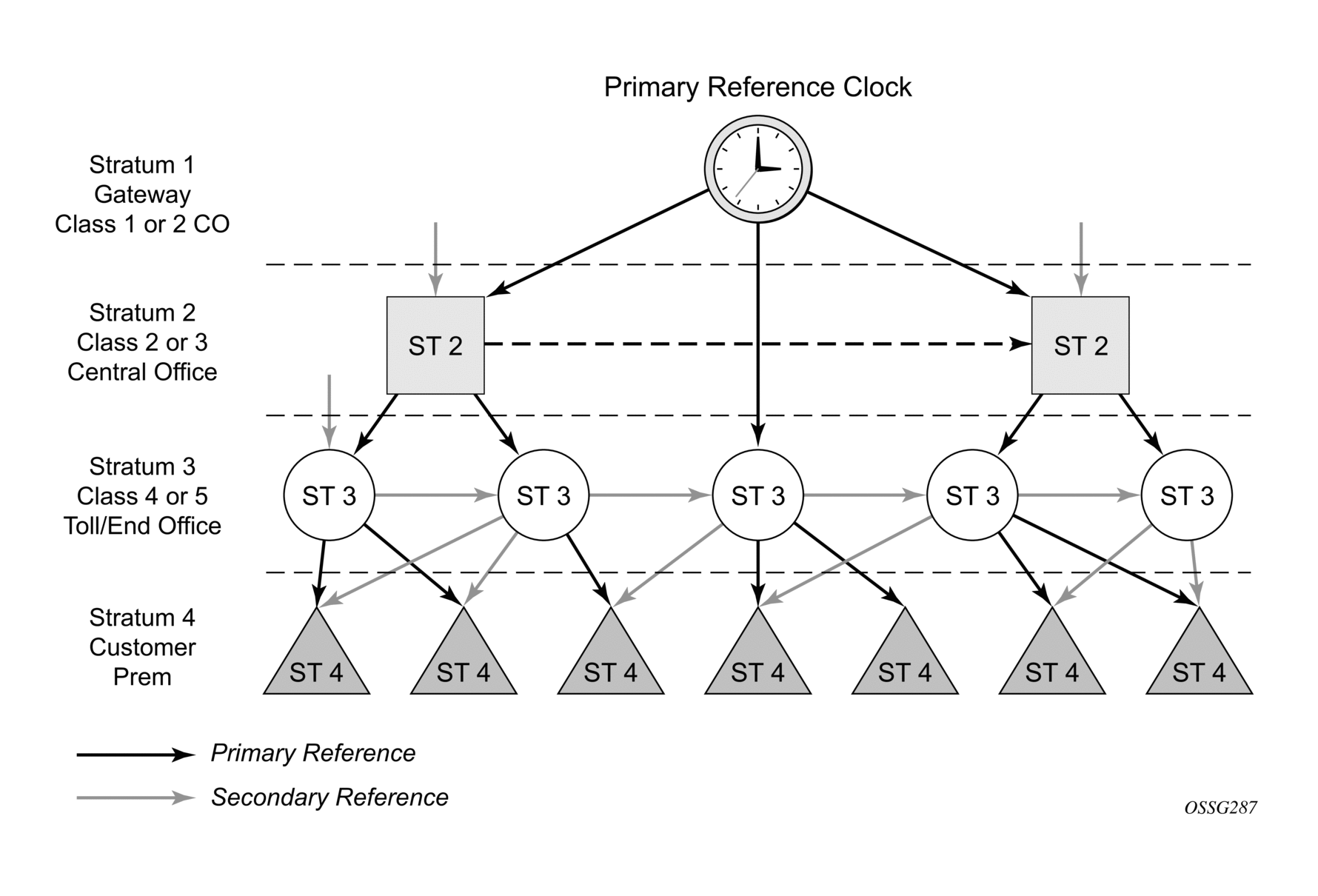
The architecture shown in Figure 23 provides the following benefits.
- It limits the need for high quality clocks at each network element and only requires that they reliably replicate input to remain traceable to its reference.
- It uses reliable physical media to provide transport of the timing signal. It does not consume any bandwidth and requires limited additional processing.
The synchronization network is designed so a clock always receives timing from a clock of equal or higher stratum or quality level. This ensures that if an upstream clock has a fault condition (for example, loses its reference and enters a holdover or free-run state) and begins to drift in frequency, the downstream clock will be able to follow it. For greater reliability and robustness, most offices and nodes have at least two synchronization references that can be selected in priority order (such as primary and secondary).
Further levels of resiliency can be provided by designing a capability in the node clock that will operate within prescribed network performance specifications without any reference for a specified timeframe. A clock operating in this mode is said to hold the last known state over (or holdover) until the reference lock is once again achieved. Each level in the timing hierarchy is associated with minimum levels of network performance.
Each synchronization capable port can be independently configured to transmit data using the node reference timing. In addition, some TDM channels can use adaptive timing or loop timing.
Transmission of a reference clock through a chain of Ethernet equipment requires that all equipment supports Synchronous Ethernet. A single piece of equipment that is not capable of performing Synchronous Ethernet breaks the chain. Ethernet frames will still get through but downstream devices should not use the recovered line timing because it will not be traceable to an acceptable stratum source.
6.5.1. Central Synchronization Subsystem
The timing subsystem has a central clock located on the CPM. The timing subsystem performs several functions of the network element clock as defined by Telcordia (GR-1244-CORE) and ITU-T G.781 standards.
The central clock uses the available timing inputs to train its local oscillator. The number of timing inputs available to train the local oscillator varies per platform. The priority order of these references must be specified. This is a simple ordered list of inputs: (ref1, ref2, BITS (if available)).
The CPM clock output can drive the clocking for all line cards in the system. The routers support selection of the node reference using Quality Level (QL) indications. The recovered clock can derive its timing from one of the references available on that platform.
The recovered clock can derive the timing from any of the following references (also shown in Figure 24):
- synchronous Ethernet portsOn the 7210 SAS-M (includes all variants), 7210 SAS-T (includes all variants), 7210 SAS-R6, 7210 SAS-R12, 7210 SAS-Sx 1/10GE (all variants), 7210 SAS-S 1/10GE (all variants), and 7210 SAS-Sx 10/100GE
- 1588v2/PTP slave portOn the 7210 SAS-M (includes all variants), 7210 SAS-T (includes all variants), 7210 SAS-R6, 7210 SAS-R12, 7210 SAS-Sx 1/10GE(all variants)
Figure 24 shows a logical model of synchronization reference selection for the platforms, and Table 31 provides a list of supported interfaces for each platform.
Figure 24: Logical Model of Synchronization Reference Selection on 7210 SAS
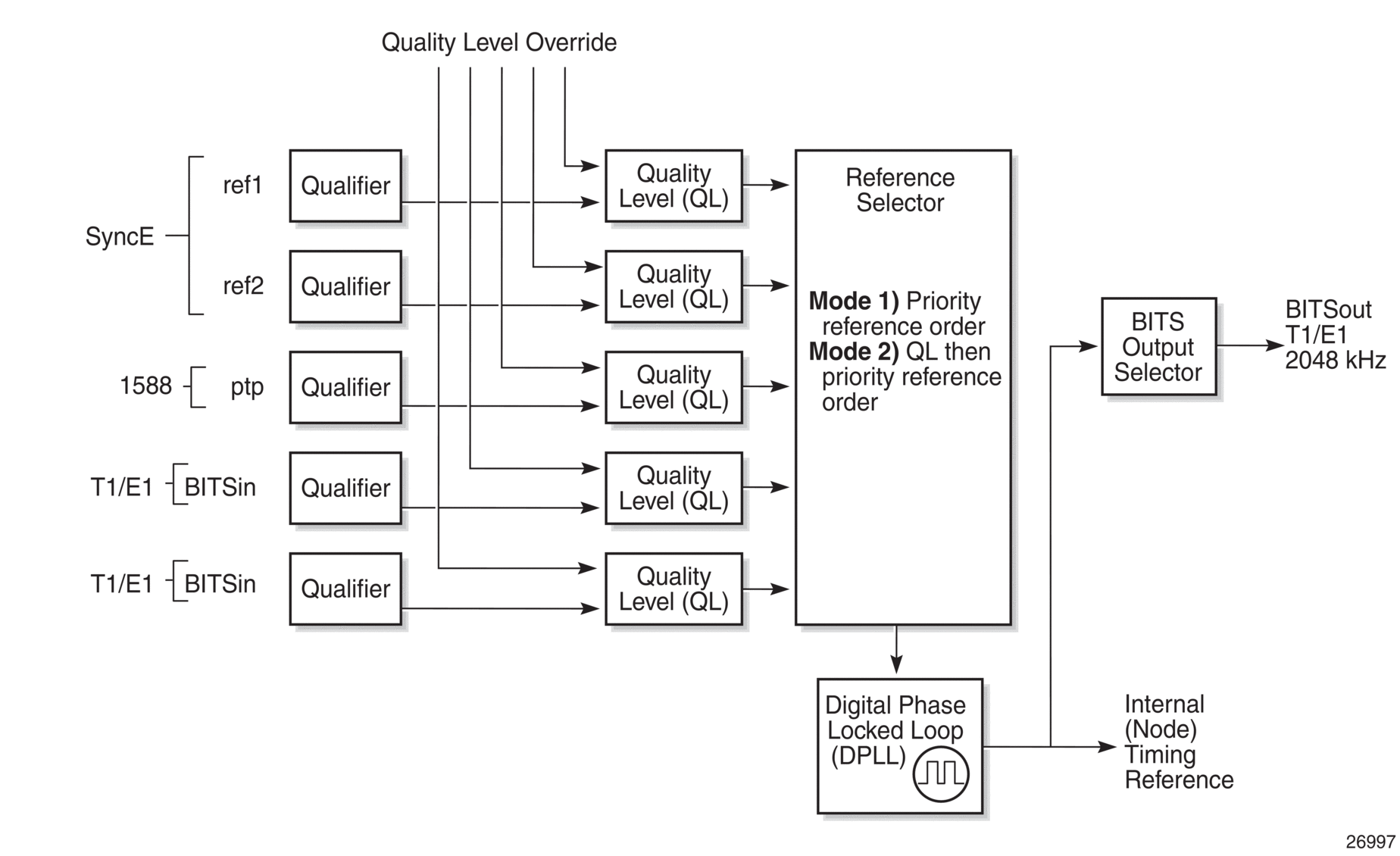
When the CES MDA is used on the 7210 SAS-M (all variants), in addition to the preceding references, the recovered clock derives the timing from either of the following references:
- T1/E1 CES channel (not available for node reference)
- T1/E1 port (for loop-timing; not available for node reference)
On the 7210 SAS-Mxp, 7210 SAS-R6, 7210 SAS-R12, and 7210 SAS-T, in addition to PTP and SyncE references, the recovered clock can be configured to derive the timing (frequency reference) from the BITS interface.
When quality Level (QL) selection mode is disabled, the reversion setting controls when the central clock can reselect a previously failed reference.
Table 30 lists the selection followed for two references in both revertive and non-revertive modes.
Table 30: Revertive, non-Revertive Timing Reference Switching Operation
Status of Reference A | Status of Reference B | Active Reference Non-revertive Case | Active Reference Revertive Case |
OK | OK | A | A |
Failed | OK | B | B |
OK | OK | B | A |
OK | Failed | A | A |
OK | OK | A | A |
Failed | Failed | holdover | holdover |
OK | Failed | A | A |
Failed | Failed | holdover | holdover |
Failed | OK | B | B |
Failed | Failed | holdover | holdover |
OK | OK | A or B | A |
6.5.2. Synchronization Options Available on 7210 SAS Platforms
Table 31 lists the synchronization options supported on 7210 SAS platforms. The 7210 SAS-Mxp, 7210 SAS-Sx 1/10GE, and 7210 SAS-Sx 10/100GE support these synchronization options only when operating in the standalone mode.
Table 31: Synchronization Options for 7210 SAS Platforms
Synchronization Options | 7210 SAS Platforms | |||||||
7210 SAS-M | 7210 SAS-T | 7210 SAS-S 1/10GE | 7210 SAS-R6 | 7210 SAS-R12 | 7210 SAS-Mxp 1 | 7210 SAS-Sx 1/10GE 1 | 7210 SAS-Sx 10/100GE 1 | |
SyncE with SSM (1GE and 10G/E fiber ports) | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
SyncE with fixed copper ports (Master and Slave support) | ✓ 2 | ✓ 3 | ✓ | ✓ | ✓ 4 | ✓ 5 | ||
Adaptive Clock Recovery (ACR) | ✓ 6 | |||||||
1588v2/PTP with port-based timestamps (both for frequency and time – also called PTP pure mode) | ✓ 7 | ✓ | ✓ | ✓ | ✓ | ✓ | ||
1588v2/PTP with port-based timestamps (time only with SyncE or BITS (if supported) used for frequency recovery – also called PTP hybrid mode) | ✓ 7 | ✓ | ✓ | ✓ | ✓ | ✓ | ||
PTP end-to-end (E2E) transparent clock | ✓ | ✓ | ||||||
BITS | ✓ 8 | ✓ 9 | ✓ 9 | ✓ | ||||
1pps and 10MHz interfaces | ✓ 10 | ✓ 10 | ✓ 10 | ✓ 10 | ||||
- Operating in standalone mode
- Supported only on fixed copper port
- Supported only on copper variants
- Supported only on combo ports with connection-type copper port
- Supported on fixed copper port (either combo port configured for copper operation or copper port)
- Supported only when T1/E1 CES MDA is used in network mode. Available only for distributing recovered clock to T1/E1 ports. Cannot be used for system clock reference.
- PTP hybrid mode recommended for use
- Supports two BITS ports configured as input or output
- Supports one BITS port (that is, BITS1), configured as input or output
- 1pps and 10MHz output available only when PTP is used as a reference for the system clock
Notes:
6.5.3. Synchronization Status Messages
Synchronization Status Messages (SSM) are supported on devices that support Synchronous Ethernet. SSM allows the synchronization distribution network to determine the quality level of the clock sourcing a specific synchronization trail and also allows a network element to select the best of multiple input synchronization trails. SSMs are defined for various transport protocols (including SONET/SDH, T1/E1, and Synchronous Ethernet), for interaction with office clocks (such as BITS or SSUs) and embedded network element clocks.
SSM allows equipment to autonomously provision and reconfigure (by reference switching) their synchronization references, while helping to avoid the creation of timing loops. These messages are particularly useful for synchronization re-configurations when timing is distributed in both directions around a ring.
6.5.4. DS1 Signals
DS1 signals can carry the quality level value of the timing source information using the SSM that is transported within the 1544 kb/s signal Extended Super Frame (ESF) Data Link (DL), as described in ITU-T Recommendation G.704. No such provision is extended to SF formatted DS1 signals.
The format of the ESF DL messages is 0xxx xxx0 1111 1111, with the rightmost bit transmitted first. The 6 bits denoted by xxx xxx contain the message; some of these messages are reserved for synchronization messaging. It takes 32 frames (4 ms) to transmit all 16 bits of a complete DL.
6.5.5. E1 Signals
E1 signals can carry the quality level value of the timing source information using the SSM, as described in ITU-T Recommendation G.704.
One of the Sa4 to Sa8 bits is allocated for SSMs; choosing the Sa bit that carries the SSM is user-configurable. To prevent ambiguities in pattern recognition, it is necessary to align the first bit (San1) with frame 1 of a G.704 E1 multiframe.
The San bits are numbered (n = 4, 5, 6, 7, 8). A San bit is organized as a 4-bit nibble San1 to San4. San1 is the most significant bit, and San4 is the least significant bit.
The message set in San1 to San4 is a copy of the set defined in SDH bits 5 to 8 of byte S1.
6.5.6. Synchronous Ethernet
Traditionally, Ethernet-based networks employ a physical layer transmitter clock derived from an inexpensive +/-100ppm crystal oscillator and the receiver locks onto it. Because data is packetized and can be buffered, there is no need for long-term frequency stability or for consistency between frequencies of different links.
Synchronous Ethernet is a variant of the line timing that derives the physical layer transmitter clock from a high-quality frequency reference, replacing the crystal oscillator with a frequency source traceable to a primary reference clock. This change is transparent to the other Ethernet layers and does not affect their operation. The receiver at the far end of the link is locked to the physical layer clock of the received signal, and ensures access to a highly accurate and stable frequency reference. In a manner analogous to conventional hierarchical master-slave network synchronization, this receiver can lock the transmission clock of other ports to this frequency reference, and establish a fully time-synchronous network.
Unlike methods that rely on sending timing information in packets over an unclocked physical layer, Synchronous Ethernet is not affected by impairments introduced by higher levels of networking technology (packet loss, packet delay variation). The frequency accuracy and stability in Synchronous Ethernet typically exceeds networks with unsynchronized physical layers.
Synchronous Ethernet allows operators to gracefully integrate existing systems and future deployments into a conventional industry-standard synchronization hierarchy. The concept is analogous to SONET/SDH system timing capabilities. The operator can select any (optical) Ethernet port as a candidate timing reference. The recovered timing from this port is used to time the system (for example, the CPM will lock to this provisioned reference selection). The operator then can ensure that all system output is locked to a stable traceable frequency source.
Note:
|
Synchronous Ethernet using fixed copper ports is supported only on the 7210 SAS-T, 7210 SAS-R6, 7210 SAS-R12, 7210 SAS-Sx 1/10GE, 7210 SAS-S 1/10GE and 7210 SAS-Mxp. The fixed copper ports can be used as a candidate reference (Master) or for distribution of recovered reference (Slave). If the port is a fixed copper Ethernet port and in 1000BASE-T mode of operation, there is a dependency on the 802.3 link timing for the Synchronous Ethernet functionality (refer to ITU-T G.8262). The 802.3 standard link Master-Slave timing states must align with the desired direction of Synchronous Ethernet timing flow. When a fixed copper Ethernet port is specified as an input reference for the node or when it is removed as an input reference for the node, an 802.3 link auto-negotiation is triggered to ensure the link timing aligns properly.
The SSM of Synchronous Ethernet uses an Ethernet OAM PDU that uses the slow protocol subtype. For a complete description of the format and processing, refer to ITU-T G.8264.
6.5.6.1. Using Synchronous Ethernet Timing for T1/E1 MDA
Only on 7210 SAS-M and all its variants, the timing recovered from Synchronous Ethernet is available for use with the T1/E1 MDA. Operators can use a stable frequency for timing the T1/E1 ports in applications where ACR is not suitable for use. Refer to the 7210 SAS OS R11.0Rx Software Release Notes for more information about specific software releases in which this feature is supported.
6.5.6.2. Clock Source Quality Level Definitions
This section describes the clock source quality levels identified for tracking network timing flow in accordance with the network deployment options defined in Recommendation G.803 and G.781. The Option I network is developed on the original European SDH model; Option II network is a network developed on the North American SONET model.
In addition to the QL values received over SSM of an interface, the standards define the following additional codes for internal use.
- QL INVx is generated internally by the system if and when an unallocated SSM value is received, where x represents the binary value of this SSM. Within the SR OS, these independent values are assigned as the single value QL-INVALID.
- QL FAILED is generated internally by the system if and when the terminated network synchronization distribution trail is in the signal fail state.
The internal quality level of QL-UNKNOWN is used to differentiate from a received QL-STU code, but is equivalent for the purposes of QL selection.
Table 32 lists the synchronization message coding and source priorities for SSM values received on port.
Table 32: Synchronization Message Coding and Source Priorities
SSM value received on port | ||||
SDH interface SyncE interface in SDH mode | SONET Interface SyncE interface in SONET mode | E1 interface | T1 interface (ESF) | Internal Relative Quality Level |
0010 (prc) | 0001 (prs) | 0010 (prc) | 00000100 11111111 (prs) | 1. Best quality |
0000 (stu) | 00001000 11111111 (stu) | 2. | ||
0111 (st2) | 00001100 11111111 (ST2) | 3. | ||
0100 (ssua) | 0100 (tnc) | 0100 (ssua) | 01111000 11111111 (TNC) | 4. |
1101 (st3e) | 01111100 11111111 (ST3E) | 5. | ||
1000 (ssub) | 1000 (ssub) | 6. | ||
1010 (st3/eec2) | 00010000 11111111 (ST3) | 7. | ||
1011 (sec/eec1) | 1011 (sec) | 8. Lowest quality qualified in QL-enabled mode | ||
1100 (smc) | 00100010 11111111 (smc) | 9. | ||
00101000 11111111 (st4) | 10. | |||
1110 (pno) | 01000000 11111111 (pno) | 11. | ||
1111 (dnu) | 1111 (dus) | 1111 (dnu) | 00110000 11111111 (dus) | 12. |
Any other | Any other | Any other | N/A | 13. QL_INVALID |
14. QL_FAILED | ||||
15. QL_UNC | ||||
Table 33 lists the synchronization message coding and source priorities for SSM values transmitted by interface type.
Table 33: Synchronization Message Coding and Source Priorities
SSM values to be transmitted by interface of type | ||||
Internal Relative Quality Level | SDH Interface SyncE interface in SDH mode | SONET Interface SyncE interface in SONET mode | E1 Interface | T1 Interface (ESF) |
1. Best quality | 0010 (prc) | 0001 (PRS) | 0010 (prc) | 00000100 11111111 (PRS) |
2. | 0100 (ssua) | 0000 (stu) | 0100 (ssua) | 00001000 11111111 (stu) |
3. | 0100 (ssua) | 0111 (st2) | 0100 (ssua) | 00001100 11111111 (st2) |
4. | 0100 (ssua) | 0100 (tnc) | 0100 (ssua) | 01111000 11111111 (tnc) |
5. | 1000 (ssub) | 1101 (st3e) | 1000 (ssub) | 01111100 11111111 (st3e) |
6. | 1000 (ssub) | 1010 (st3/eec2) | 1000 (ssub) | 00010000 11111111 (st3) |
7. | 1011 (sec/eec1) | 1010 (st3/eec2) | 1011 (sec) | 00010000 11111111 (st3) |
8. Lowest quality qualified in QL-enabled mode | 1011 (sec/ eec1) | 1100 (smc) | 1011 (sec) | 00100010 11111111 (smc) |
9. | 1111 (dnu) | 1100 (smc) | 1111 (dnu) | 00100010 11111111 (smc) |
10. | 1111 (dnu) | 1111 (dus) | 1111 dnu | 00101000 11111111 (st4) |
11. | 1111 (dnu) | 1110 (pno) | 1111 (dnu) | 01000000 11111111 (pno) |
12. | 1111 (dnu) | 1111 (dus) | 1111 (dnu) | 00110000 11111111 (dus) |
13. | 1111 (dnu) | 1111 (dus) | 1111 (dnu) | 00110000 11111111 (dus) |
14. | 1111 (dnu) | 1111 (dus) | 1111 (dnu) | 00110000 11111111 (dus) |
15. | 1011 (sec/eec1) | 1010 (st3/eec2) | 1011 (sec) | 00010000 11111111 (st3) |
6.5.7. Adaptive Clock Recovery
Note:
|
ACR is a timing-over-packet technology that transports timing information via periodic packet delivery over a pseudowire. ACR is used when there is no other Stratum 1 traceable clock available.
There is no extra equipment cost to implement ACR in a network because ACR uses the packet arrival rate of a TDM pseudowire to regenerate a clock signal. The nodes in the network that are traversed between endpoints do not need special ACR capabilities. However, because the TDM pseudowire is transported over Layer 2 links, the packet flow is susceptible to PDV.
Use the following recommendations to achieve the best ACR performance.
- A packet rate of 1000 pps to 4000 pps is recommended. Lower packet rates cause ACR to be more susceptible to PDV in the network.
- Limit the number of nodes traversed between the source-end and the ACR-end of the TDM pseudowire.
- Enable QoS in the network with the TDM pseudowire enabled for ACR classified as NC (network control).
- Maintain a constant temperature; temperature variations affect the natural frequency on the internal oscillators in the 7210 SAS.
- Ensure that the network does not contain a timing loop when it is designed.
There are five potential ACR states:
- normal
- phase tracking
- frequency tracking
- holdover
- free-run
When a port’s ACR state is normal, phase tracking, or frequency tracking, the recovered ACR clock is treated as a qualified reference source for the SSU. If this reference source is used, transitions between any of these three states will not affect SSU operation.
When a port’s ACR state is free-run or holdover, the recovered ACR clock is disqualified as a reference source for the SSU. If this reference source is used, transitions to either of these two states will cause the SSU to drop the reference and switch to the next highest prioritized reference source. This can potentially be SSU holdover.
6.5.8. IEEE 1588v2 PTP
The Precision Time Protocol (PTP) is a timing-over-packet protocol defined in the IEEE 1588v2 standard 1588 PTP 2008.
PTP may be deployed as an alternative timing-over-packet option to ACR. PTP provides the capability to synchronize network elements to a Stratum-1 clock or primary reference clock (PRC) traceable source over a network that may or may not be PTP-aware. PTP has several advantages over ACR. It is a standards-based protocol, has lower bandwidth requirements, can transport both frequency and time, and can potentially provide better performance.
The basic types of PTP devices are the following:
- ordinary clock
- boundary clock
- end-to-end transparent clock
- peer-to-peer transparent clock
Table 31 lists the 7210 SAS platform support for the different types of PTP devices.
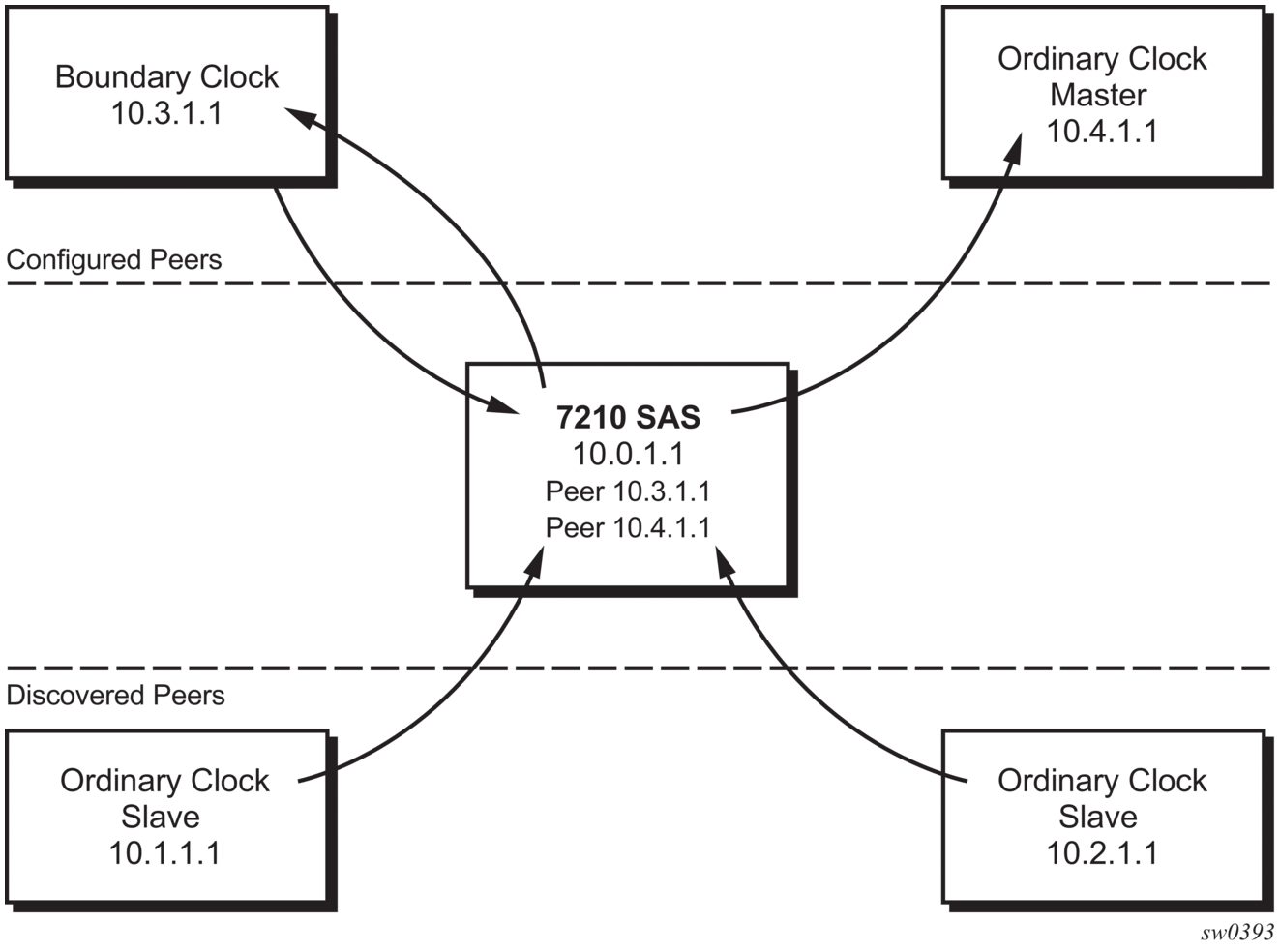
The 7210 SAS communicates with peer 1588v2 clocks, as shown in Figure 25. These peers can be ordinary clock slaves or boundary clocks. The communication can be based on either unicast IPv4 sessions transported through IP interfaces or Ethernet multicast PTP packets transported through an Ethernet port.
Figure 25: Peer Clocks
IP/UDP unicast and Ethernet multicast support for the 7210 SAS platforms is listed in Table 34.
| Note: PTP is supported on all 7210 SAS platforms as described in this document, except the 7210 SAS-Sx 10/100GE and 7210 SAS-Sx/S 1/10GE operating in standalone-VC mode. See section 6.5.11 for a list of PTP profiles, and the configuration guidelines and restrictions. |
Table 34: IP/UDP Unicast and Ethernet Multicast Support
Platform | IP/UDP Unicast | Ethernet Multicast |
7210 SAS-M | Yes | Yes |
7210 SAS-T | Yes | No |
7210 SAS-Mxp | Yes | Yes |
7210 SAS-Sx 1/10GE | Yes | No |
7210 SAS-S 1/10GE | No | No |
7210 SAS-Sx 10/100GE | No | No |
7210 SAS-R6 | Yes | Yes (IMM (a.k.a. IMMv1) and IMM-b card only) |
7210 SAS-R12 | Yes | Yes (IMM-b card only) |
For unicast IP sessions, there are two types of peers: configured and discovered. The 7210 SAS operating as an ordinary clock slave or as a boundary clock must have configured peers for each PTP neighbor clock from which it might accept synchronization information. The 7210 SAS initiates unicast sessions with all configured peers. A 7210 SAS operating as a boundary clock will accept unicast session requests from external peers. If the peer is not a configured peer, it is considered a discovered peer. The 7210 SAS can deliver synchronization information toward discovered peers (that is, slaves).
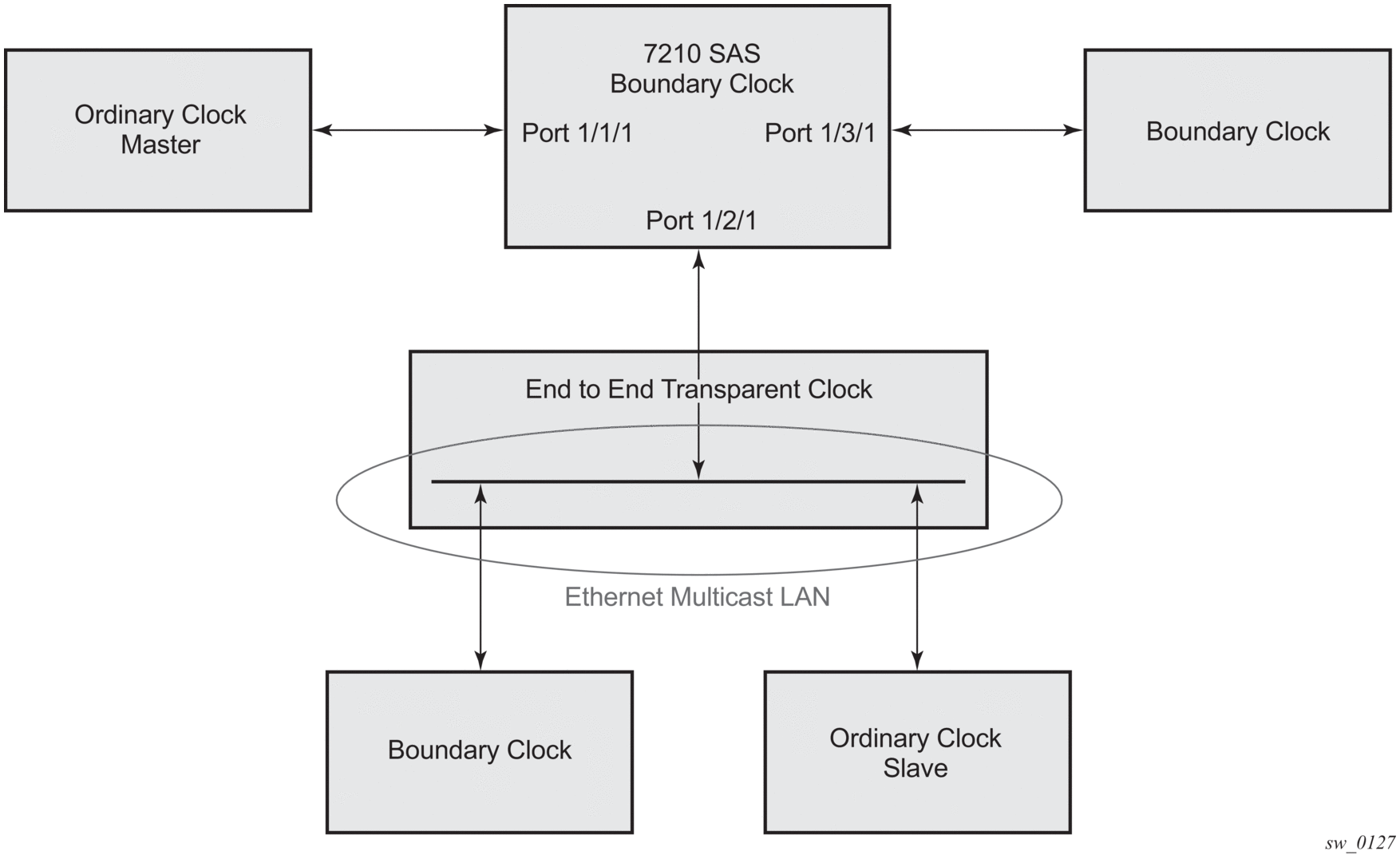
For Ethernet multicast operation, the node listens for and transmits PTP messages using the configured multicast MAC address. Neighbor clocks are discovered via the reception of messages through an enabled Ethernet port. The 7210 SAS supports only one neighbor PTP clock connecting into a single port (see Figure 26); multiple PTP clocks connecting through a single port are not supported. This might be encountered with the deployment of an Ethernet multicast LAN segment between the 7210 SAS and the neighbor PTP ports using an end-to-end transparent clock or an Ethernet switch. The use of an Ethernet switch is not recommended because of PDV and the potential degradation of performance, but it can be used if appropriate for the application.
The 7210 SAS does not allow simultaneous PTP operations using both unicast IPv4 and Ethernet multicast. A change of profile to G.8275.1 or from G.8275.1 to another profile requires a reboot of the node.
Figure 26 shows one neighbor PTP clock connecting into a single port.
Figure 26: Ethernet Multicast Ports
| Note: 7210 SAS platforms do not support ordinary clock master configuration. |
The IEEE 1588v2 standard includes the concept of PTP profiles. These profiles are defined by industry groups or standards bodies that define the use of IEEE 1588v2 for specific applications.
The following profiles are supported for 7210 SAS platforms (as described in Table 34):
- IEEE 1588v2 (default profile)
- ITU-T Telecom profile (G.8265.1)
- ITU-T Telecom profile for time with full timing support (G.8275.1)
| Note: The following caveats apply to G.8275.1 support. See section 6.5.11 for configuration guidelines and restrictions.
|
When a 7210 SAS receives Announce messages from one or more configured peers or multicast neighbors, it executes a Best Master Clock Algorithm (BMCA) to determine the state of communication between itself and the peers. The system uses the BMCA to create a hierarchical topology, allowing the flow of synchronization information from the best source (the grandmaster clock) out through the network to all boundary and slave clocks. Each profile has a dedicated BMCA.
If the profile setting for the clock is ieee1588-2008, the precedence order for the best master selection algorithm is as follows:
- priority1
- clock class
- clock accuracy
- PTP variance (offsetScaledLogVariance)
- priority2
- clock identity
- steps removed from the grandmaster
The 7210 SAS sets its local parameters as described in Table 35.
Table 35: Local Clock Parameters When Profile is Set to ieee1588-2008
Parameter | Value |
clockClass | 248 – the 7210 SAS is configured as a boundary clock 255 – the 7210 SAS is configured as an ordinary clock slave |
clockAccuracy | FE - unknown |
offsetScaledLogVariance | FFFF – not computed |
clockIdentity | Chassis MAC address following the guidelines of section 7.5.2.2.2 of IEEE 1588-2008 |
If the profile setting for the clock is itu-telecom-freq (ITU G.8265.1 profile), the precedence order for the best master selection algorithm is:
- clock class
- PTSF (Packet Timing Signal Fail) - Announce Loss (miss 3 Announce messages or do not get an Announce message for 6 seconds)
- priority
The 7210 SAS sets its local parameters as described in Table 36.
Table 36: Local Clock Parameters When Profile is Set to itu-telecom-freq
Parameter | Value |
clockClass | 80-110 – value corresponding to the QL out of the central clock of the 7210 SAS as per Table 1/G.8265.1 255 – the 7210 SAS is configured as an ordinary clock slave |
The ITU-T profile is for use in environments with only ordinary clock masters and slaves for frequency distribution. The default profile should be used for all other cases.
If the profile setting for the clock is g8275dot1-2014, the precedence order for the best master selection algorithm is very similar to that used with the default profile. It ignores the priority1 parameter, includes a localPriority parameter, and includes the ability to force a port to never enter the slave state (master-only). The precedence is as follows:
- clock class
- clock accuracy
- PTP variance (offsetScaledLogVariance)
- priority2
- localPriority
- clock identity
- steps removed from the grandmaster
The 7210 SAS sets its local parameters as described in Table 37.
Table 37: Local Clock Parameters When Profile is Set to g8275dot1-2014
Parameter | Value |
clockClass | 165 – the 7210 SAS is configured as a boundary clock and the boundary clock was previously locked to a grandmaster with clock class of 6 248 – the 7210 SAS is configured as a boundary clock 255 – the 7210 SAS is configured as an ordinary clock slave |
clockAccuracy | FE – unknown |
offsetScaledLogVariance | FFFF – not computed |
clockIdentity | Chassis MAC address following the guidelines of section 7.5.2.2.2 of IEEE 1588-2008 |
The 7210 SAS can support a limited number of configured peers (possible master or neighbor boundary clocks) and a limited number of discovered peers (slaves).These peers use the unicast negotiation procedures to request service from the 7210 SAS clock. A neighbor boundary clock counts for two peers (both a configured and a discovered peer) toward the maximum limit.
The number of configured Ethernet ports is not restricted.
On the 7210 SAS-M, 7210 SAS-Mxp, 7210 SAS-R6, 7210 SAS-R12, 7210 SAS-Sx 1/10GE, and 7210 SAS-T, there are limits on the number of slaves enforced in the implementation for unicast and multicast slaves. Refer to the scaling guide for the appropriate release for the specific unicast message limits related to PTP.
On the 7210 SAS-M, when multicast messaging on Ethernet ports is enabled, the PTP load must be monitored to ensure that the load does not exceed the capabilities (configured values). There are several commands that can be used for this monitoring, including:
- show system cpu identifies the load of the PTP software process. If the “capacity usage” reaches 100%, the PTP software process on the 7210 SAS is at its limit of transmitting and/or receiving PTP packets.
Because the user cannot control the number of PTP messages received by the 7210 SAS over its Ethernet ports, the following statistics commands can be used to identify the source of the message load:
- show system ptp statistics displays aggregate packet rates
- show system ptp port and show system ptp port port-id [detail] display received packet rates
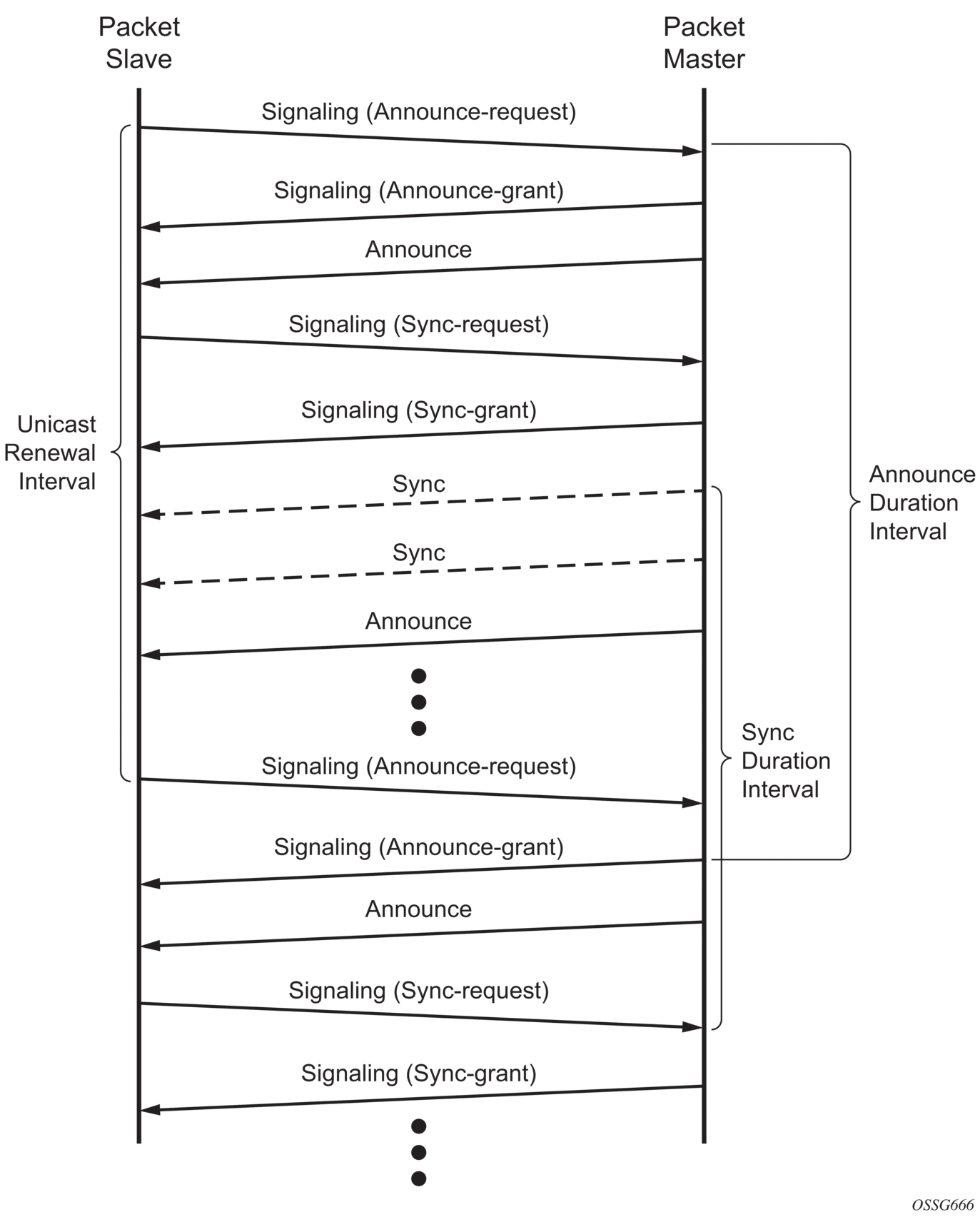
Figure 27 shows the unicast negotiation procedure performed between a slave and a peer clock that is selected to be the master clock. The slave clock will request Announce messages from all peer clocks but only request Sync and Delay_Resp messages from the clock selected to be the master clock.
Figure 27: Messaging Sequence Between the PTP Slave Clock and PTP Master Clocks
6.5.8.1. PTP Clock Synchronization
The IEEE 1588v2 standard synchronizes the frequency and time from a master clock to one or more slave clocks over a packet stream. This packet-based synchronization can be over unicast IP/UDP unicast or Ethernet multicast.
As part of the basic synchronization timing computation, event messages are defined for synchronization messaging between the PTP slave clock and PTP master clock. A one-step or two-step synchronization operation can be used; the two-step operation requires a follow-up message after each synchronization message.
| Note:
|
During startup, the PTP slave clock receives synchronization messages from the PTP master clock before a network delay calculation is made. Prior to any delay calculation, the delay is assumed to be zero. A drift compensation is activated after a number of synchronization message intervals occur. The expected interval between the reception of synchronization messages is user-configurable.
Figure 28 shows the basic synchronization timing computation between the PTP slave clock and PTP best master; the offset of the slave clock is shown referenced to the best master signal during startup.
Figure 28: PTP Slave Clock and Master Clock Synchronization Timing Computation
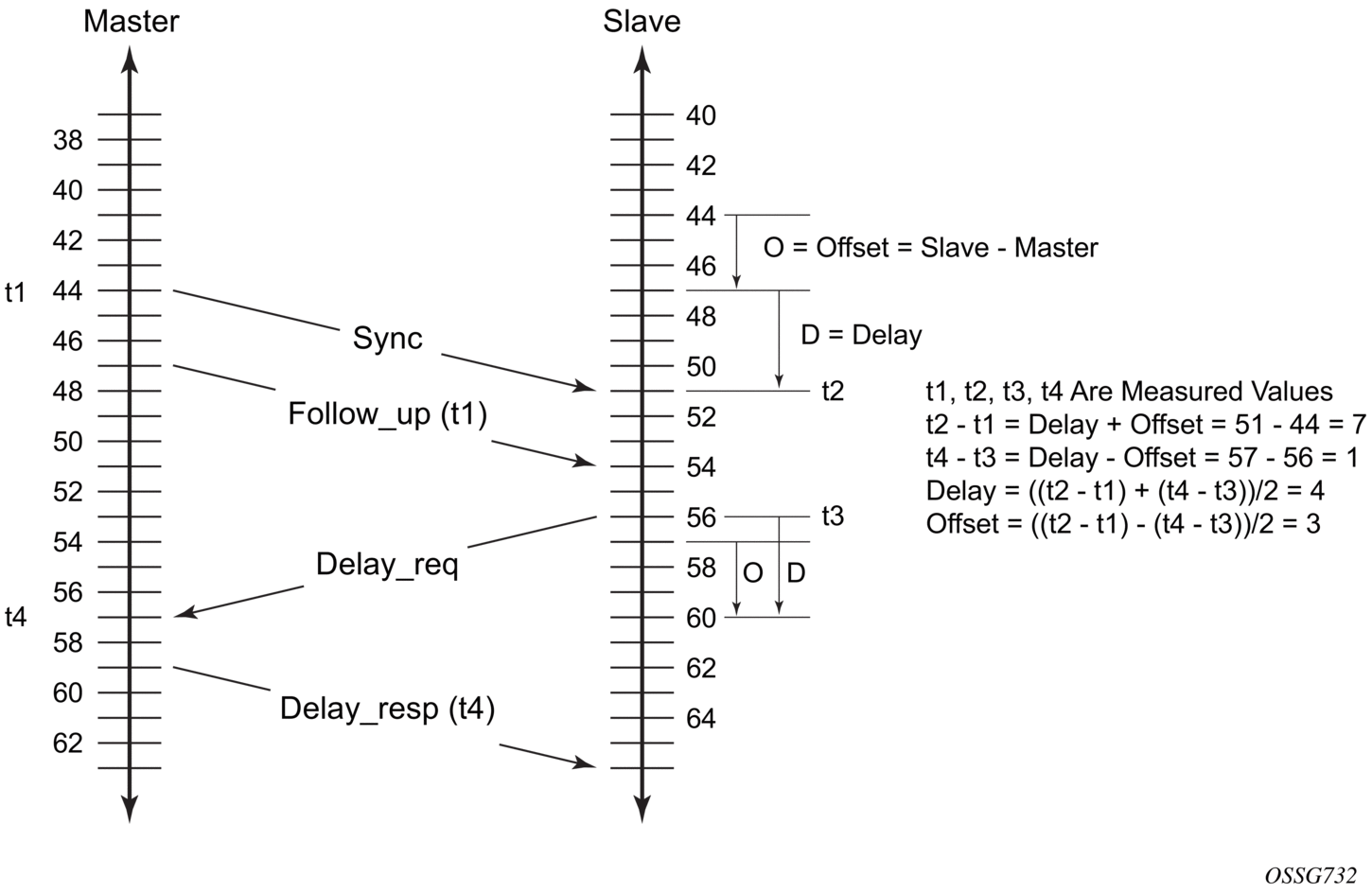
When the IEEE 1588v2 standard is used for distribution of a frequency reference, the slave calculates a message delay from the master to the slave based on the timestamps exchanged. A sequence of these calculated delays contains information about the relative frequencies of the master clock and slave clock, but also includes a noise component related to the PDV experienced across the network. The slave must filter the PDV effects to extract the relative frequency data and then adjust the slave frequency to align with the master frequency.
When the IEEE 1588v2 standard is used for distribution of time, the 7210 SAS calculates the offset between the 7210 SAS time base and the external master clock time base based on the four timestamps exchanged. The 7210 SAS determines the offset adjustment, and between these adjustments, it maintains the progression of time using the frequency from the central clock of the node. This allows time to be maintained using a Synchronous Ethernet input source even if the IEEE 1588v2 communications fail. When using IEEE 1588v2 for time distribution, the central clock should, at a minimum, have the PTP input reference enabled.
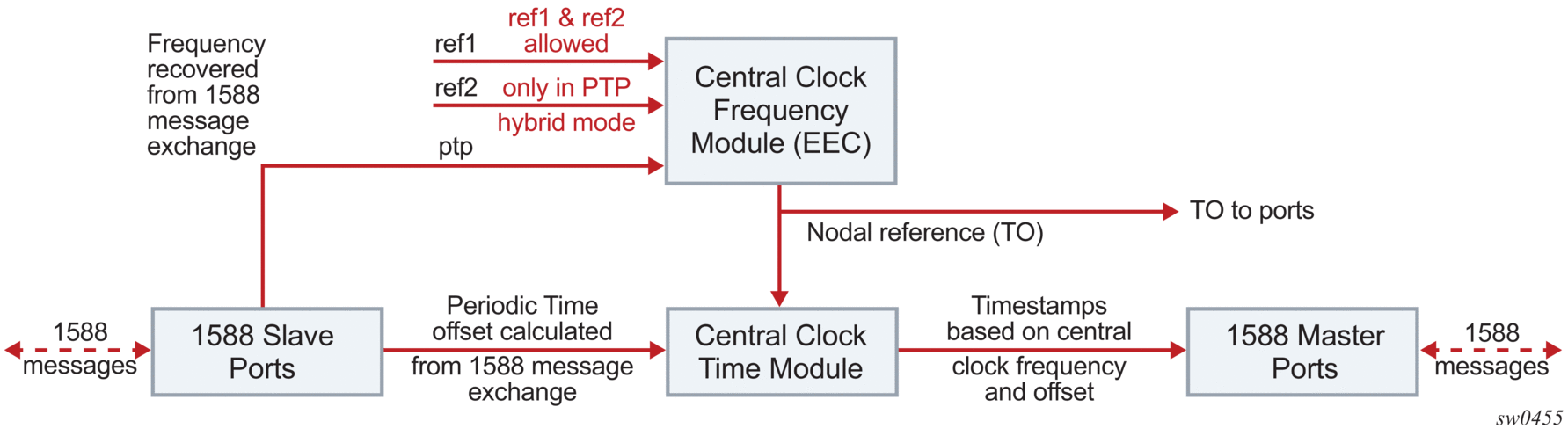
Figure 29 shows the logical model for using PTP/1588 for network synchronization.
Figure 29: Logical Model for Using PTP/1588 for Network Synchronization on 7210 SAS Platforms
6.5.8.2. Performance Considerations
Although IEEE 1588v2 can be used on a network that is not PTP-aware, the use of PTP-aware network elements (boundary clocks) within the packet switched network improves synchronization performance by reducing the impact of PDV between the grand master clock and the slave clock. In particular, when IEEE 1588v2 is used to distribute high-accuracy time, such as for mobile base station phase requirements, the network architecture requires the deployment of PTP awareness in every device between the grandmaster and the mobile base station slave.
In addition, performance is also improved by the removal of any PDV caused by internal queuing within the boundary clock or slave clock. This is accomplished with hardware that is capable of port-based timestamping, which detects and timestamps the IEEE 1588v2 packets at the Ethernet interface.
6.5.8.3. PTP End-to-End Transparent Clock
| Note: This feature is supported only on the 7210 SAS-Sx 1/10GE and 7210 SAS-Sx 10/100GE. |
The 7210 SAS devices support PTP end-to-end (E2E) Transparent Clock (TC) functionality, which allows the node to update the PTP correction fields (CFs) for the residence time of the PTP message. See Table 31 for a list of platforms that support this functionality.
A CLI option is provided to enable the PTP port-based hardware timestamp on ports that receive and forward PTP messages. To enable the TC function, PTP must not be enabled on the node. When the timestamp option is enabled, the node identifies standards-based messages and updates the CF for PTP IP/UDP multicast and unicast messages, and for the PTP Ethernet multicast and unicast messages. The CF is updated for the residence time of the PTP message. Downstream PTP slaves that receive the PTP message use the updated CF to measure the delay between the master and themselves.
You can enable the TC option by running the configure>port>ethernet>ptp-hw-timestamp command on ports (both ingress and egress) on which residence time in the PTP message must be updated when the message is in transit through the node. You can disable the residence time update by running the no form of the command on both ingress and egress ports, as required. No additional CLI commands are required to enable the PTP TC option.
Nokia recommends the following operational guidelines and examples for enabling and using the PTP TC feature.
- Assume port 1/1/10 is connected to a PTP master clock (using a port, a SAP, or an IES IP interface) and 1/1/15 is connected to a PTP slave clock (using a port, a SAP, or an IES IP interface).To enable PTP TC in this scenario, you must enable the ptp-hw-timestamp command on both ports. To disable PTP TC, run the no form of the command on both ports.
- Assume port 1/1/10 is connected to a PTP master clock (using a port, a SAP, or an IES IP interface) and ports 1/1/15 and 1/1/16 have PTP slaves (using a port, a SAP, or an IES IP interface), with a PTP session to the PTP master clock that is connected on port 1/1/10.To enable PTP TC, the ptp-hw-timestamp command must be enabled on all three ports.In this scenario, it is not possible to disable PTP TC only towards the slave connected on port 1/1/15. The functionality must be disabled on all three ports.Additionally, note that the PTP messages coming in on port 1/1/10 are not forwarded out of any ports other than 1/1/15 and 1/1/16, when the ptp-hw-timestamp command is enabled on port 1/1/10. Nokia recommends that when a set of PTP ports are enabled for ptp-hw-timestamp, the operator must ensure that PTP messages are forwarded to only the specific set of ports where the TC option is enabled, and not to other ports. Forwarding PTP messages to other ports that do not belong to the specific set may result in incorrect updates.
- You can enable PTP TC for a set of SAPs and also transparently forward PTP packets on other SAPs, while both SAPs share a common uplink to forward PTP messages. To implement this scenario, use MPLS tunnels with network ports as the uplinks. Nokia recommends the following configuration.
- PTP hardware port-based timestamping must be disabled on the access ports where SAPs are configured. These access ports are typically used to connect to either PTP master or PTP slaves that need to establish and exchange PTP messages transparently.
- PTP hardware port-based timestamping must be enabled on the access ports where SAPs are configured and the TC function is required. These access ports are typically used to connect to either the PTP master or PTP slaves.
- PTP hardware port-based timestamping must be enabled on the network ports where the MPLS tunnels originate and terminate. In this case, the PTP TC function updates only the PTP messages that are not MPLS encapsulated.
- See PTP Message Transparent Forwarding for additional support information.
6.5.8.4. PTP Message Transparent Forwarding
| Note: When PTP is enabled on the 7210 SAS-M (operating in both network mode and access-uplink mode) for node synchronization, port-based hardware timestamping is enabled on all ports by default, and only locally-destined PTP packets are processed by the node. PTP IP/UDP messages that are not addressed to the node are forwarded transparently without additional configuration. |
On bootup, port-based hardware timestamping is enabled by default on all ports on the 7210 SAS-Mxp, 7210 SAS-R6, 7210 SAS-R12, 7210 SAS-Sx 1/10GE, and 7210 SAS-T, and the node processes both transit packets and locally destined PTP packets. Use the ptp-hw-timestamp command to disable port-based hardware timestamping in the following cases:
- to allow the node to transparently forward PTP packets when MPLS uplinks are used
- when PTP is enabled and used to synchronize and time the node (that is, PTP messages are originated and terminated by the node acting as a PTP OC-slave or BC)
- on ports that receive PTP packets that will be forwarded transparently
When PTP port-based hardware timestamp is disabled, the node does not update the correction field in PTP messages. Refer to the 7210 SAS-M, T, R6, R12, Mxp, Sx, S Interface Configuration Guide for more information about the ptp-hw-timestamping command.
For example, to enable transparent forwarding of PTP packets over MPLS tunnels, when access ports with configured SAPs are used to connect the PTP master or PTP slaves, the ptp-hw-timestamp command can be used to disable PTP port-based hardware timestamping on these access ports.
| Note: The ptp-hw-timestamp command is only supported on the 7210 SAS-T, 7210 SAS-Mxp, 7210 SAS-R6, 7210 SAS-R12, 7210 SAS-Sx 1/10GE, and 7210 SAS-Sx 10/100GE. Port-based hardware timestamping can be used for transparent PTP packet forwarding if PTP is enabled and used to time the node (that is, PTP messages are originated and terminated by the node acting as a PTP OC-slave or BC). |
The following guidelines must be considered for transparent PTP packet forwarding.
- By default, PTP port-based hardware timestamping is enabled on all ports at bootup. To allow transparent PTP packet forwarding, the feature must be disabled using the configure>port>no ptp-hw-timestamp command.
- On 7210 SAS-Mxp, 7210 SAS-T, 7210 SAS-R6, 7210 SAS-R12, 7210 SAS-Sx 10/100GE, and 7210 SAS-Sx 1/10GE, if the ptp-hw-timestamp command is enabled by executing the command on a set of ports, the node processes PTP packets that transit those ports to update the correction field for the packet residence time in the node. This allows for accurate computation by PTP time and frequency recovery algorithms on PTP slave clocks that are connected to those ports.
- The command to enable PTP hardware timestamps for packets transiting the node should be configured on both the ingress and egress port where PTP packets are expected to be received and sent from (and where they need to be processed to update correction time). Configuring the PTP hardware timestamp command on only the ingress port or egress port is not recommended because this will result in incorrect updates to the correction field.
- For 7210 SAS-R6 and 7210 SAS-R12 platforms with IMM-b (IMMv2) and IMM-c cards, and for the 7210 SAS-Mxp and 7210 SAS-Sx 1/10GE, to enable transparent forwarding of PTP packets over MPLS tunnels, PTP hardware port-based timestamping must be disabled on the access ports where SAPs are configured. These access ports are used to connect to either PTP master or PTP slaves that need to establish and exchange PTP messages transparently. PTP hardware port-based timestamping does not need to be disabled on the network ports where the MPLS tunnels originate and terminate. This means that these network ports can be used for PTP packet exchange when the node is a PTP boundary clock or ordinary clock slave. If the requirement is to forward PTP packets transparently when MPLS uplinks are not used or when a hybrid port with a SAP is used, PTP hardware port-based timestamping must be disabled on the access port and hybrid port.
- On the 7210 SAS-Mxp and 7210 SAS-Sx 1/10GE, PTP messages for the G.8265.1 and IEEE 1588v2 profiles are transparently forwarded only for a VPRN service on which hardware timestamping is enabled on the access port. This restriction only applies to PTP packets that are using IP/UDP unicast encapsulation.
- To enable transparent forwarding of PTP packets over MPLS tunnels on the 7210 SAS-T and 7210 SAS-R6 platforms installed with IMMv1 cards, you must disable hardware timestamping on access ports where SAPs are configured, and on the MPLS tunnel originating and terminating network ports. Consequently, these network ports cannot be used for PTP packet exchange when the node is a PTP boundary clock or ordinary clock slave.To use the node as a PTP boundary clock or ordinary clock slave, you must use separate ports. In other words, a different access port, network port, or hybrid port must be used for PTP message exchange when this node is configured to be a PTP boundary clock or ordinary clock slave, and it cannot be any of the ports (either ingress or egress ports) on which PTP packets are forwarded transparently.
- If MPLS LSR traffic is configured on a 7210 SAS-R6 platform installed with IMMv1 cards, port-based timestamping on network ports is supported for PTP packets with Ethernet encapsulation, but not for packets in an MPLS tunnel.
6.5.8.5. PTP Capabilities
PTP messages are supported through IPv4 unicast with a fixed IP header size. Table 38 describes the supported message rates for slave and master states. The ordinary clock can only be used in the slave state. The boundary clock can be in both of these states.
Table 38: Support Message Rates for Slave and Master Clock States
Support Message | Slave Clock | Master Clock | |
Request Rate 1 | Grant Rate 1 | ||
Min | Max | ||
Announce | 1 packet every 2 seconds | 1 packet every 2 seconds | 1 packet every 2 seconds |
Sync | User-configurable with an option to configure 8/16/32/64 packets/second | 8 packets/second | 64 packets/second |
Delay_Resp | User-configurable with an option to configure 8/16/32/64 packets/second | 8 packets/second | 64 packets/second |
Duration | 300 seconds | 1 second | 1000 seconds |
- For more information, see 1PPS and 10MHz Output Interface
Note:
State and statistics data for each master clock are available to assist in the detection of failures or unusual situations.
6.5.8.6. PTP Ordinary Slave Clock for Frequency
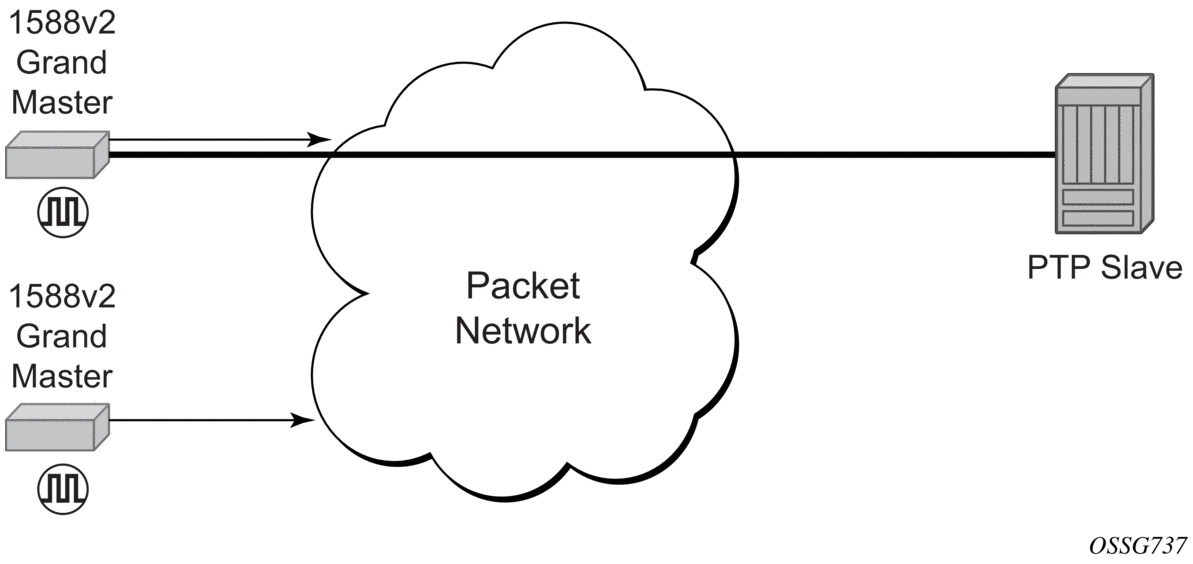
Traditionally, only clock frequency is required to ensure smooth transmission in a synchronous network. The PTP ordinary clock with slave capability on the 7210 SAS provides another option to reference a Stratum-1 traceable clock across a packet switched network. The recovered clock can be referenced by the internal SSU and distributed to all slots and ports.
Figure 30 shows a PTP ordinary slave clock network configuration.
Figure 30: Slave Clock
6.5.9. PTP Boundary Clock for Frequency and Time
Although IEEE 1588v2 can function across a packet network that is not PTP-aware, performance may be unsatisfactory and unpredictable. PDV across the packet network varies with the number of hops, link speeds, utilization rates, and the inherent behavior of routers. By using routers with boundary clock functionality in the path between the grandmaster clock and the slave clock, one long path over many hops is split into multiple shorter segments, allowing better PDV control and improved slave performance. This allows PTP to function as a valid timing option in more network deployments and allows for better scalability and increased robustness in certain topologies, such as rings.
Boundary clocks can simultaneously function as a PTP slave of an upstream grandmaster (ordinary clock) or boundary clock, and as a PTP master of downstream slaves (ordinary clock) and boundary clocks. The time scale recovered in the slave side of the boundary clock is used by the master side of the boundary clock. This allows time distribution across the boundary clock.
Figure 31 shows routers with boundary clock functionality in the path between grandmaster clock and the slave clock.
Figure 31: Boundary Clock
6.5.10. 1PPS and 10MHz Output Interface
The 7210 SAS-T, 7210 SAS-Mxp, 7210 SAS-R6, and 7210 SAS-R12 support 1PPS and 10 MHz output interfaces. These interfaces output the recovered signal from the system clock when PTP is enabled.
| Note: 1pps and 10MHz signals are available only when PTP is enabled. |
6.5.11. Configuration Guidelines and Restrictions for PTP
The following guidelines and restrictions apply for PTP configuration.
- On 7210 SAS devices, only a single profile (IEEE 1588v2, G.8265.1, or G.8275.1) can be enabled for all PTP communications (both towards its master and slave connections) at any point in time.
- The PTP G.8275.1 profile is supported only on the 7210 SAS-M, 7210 SAS-Mxp,7210 SAS-R6, and 7210 SAS-R12 devices.On the 7210 SAS-R6, the G.8275.1 profile is supported only for IMMv1 and IMMv2 cards.On the 7210 SAS-R12, the G.8275.1 profile is supported only for IMMv2 cards.When using the profile, the following restrictions apply.
- The delay and sync requests are set to 16 pps by default and are not configurable.
- The announce rate is set to 8 pps by default and is not configurable.
- A change of profile to G.8275.1 or from G.8275 to another profile requires a reboot of the node.
- Only a single multicast slave is supported per port.
- PTP with Ethernet encapsulation is only supported with the G.8275.1 profile.
- PTP over IP encapsulation is not supported with the G.8275.1 profile. It is supported only with the IEEE 1588v2 and G.8265.1 profiles.
- PTP slave capability is available on all the ports on the 7210 SAS-M, 7210 SAS-Mxp, 7210 SAS-R6, 7210 SAS-R12, 7210 SAS-Sx 1/10GE, and 7210 SAS-T.
- When changing the clock-type to or from a boundary clock on the 77210 SAS-Mxp, 7210 SAS-R6, 7210 SAS-R12, 7210 SAS-Sx 1/10GE, and 7210 SAS-T platforms, the node must be rebooted for the change to take effect. Nokia recommends taking appropriate measures to minimize service disruption during the reboot process.
- On the 7210 SAS-M, use of PTP and SyncE as a reference simultaneously is not allowed. Either SyncE or PTP can be configured as a reference, but not both together.
- The 7210 SAS-Mxp, 7210 SAS-R6, 7210 SAS-R12, 7210 SAS-Sx 1/10GE, and 7210 SAS-T support the use of PTP and SyncE as a reference simultaneously; that is, on these platforms, the ref-order can be set to config>system>sync-if-timing>ref-order ref1 ref2 ptp.
- The 7210 SAS-M, 7210 SAS-Mxp, 7210 SAS-R6, 7210 SAS-R12, 7210 SAS-Sx 1/10GE, and 7210 SAS-T support the PTP hybrid mode of operation. Frequency recovery is provided by the central clock through either SyncE or BITS, depending on which reference is configured. PTP is used for time recovery only. In this mode, the node can recover very stable frequency using a reduced PTP packet rate.
- The 7210 SAS-M uses CPU processing cycles for frequency and time recovery. Use of PTP hybrid mode reduces the amount of CPU processing cycles needed, helping customers scale better.
- To enable PTP hybrid mode on the 7210 SAS-Mxp, 7210 SAS-R6, 7210 SAS-R12, 7210 SAS-Sx 1/10GE, and 7210 SAS-T, run the config>system>ptp>clock>freq-source ssu CLI command. To enable pure PTP mode, the user must execute the command config>system>ptp>clock>freq-source ptp.For a change of value from ssu to ptp (or vice-versa) to take effect, the operator must save the configuration changes and reboot the node.
- On the 7210 SAS-R6 and 7210 SAS-R12, only the BITS1 port can be used to provide a reference to the system clock or to distribute the reference. The use of the BITS2 port is not supported.
- On the 7210 SAS-T and 7210 SAS-Mxp, both the BITS1 and BITS2 ports can be used to provide a reference to the system clock or to distribute the reference.
- On the 7210 SAS-M, Nokia strongly recommends using PTP in hybrid mode only. Hybrid mode facilitates reduced PTP packet rates and improved scalability.
- On the 7210 SAS-Mxp, 7210 SAS-R6, 7210 SAS-R12, 7210 SAS-Sx 1/10GE, and 7210 SAS-T, an IP address must be configured under config>system>security>source-address>application ptp, before PTP can be enabled for use. The use of the system IPv4 interface address or other loopback IPv4 interface address is recommended for PTP applications. The IPv4 address of an IPv4 interface over a port can also be used. The PTP software uses the configured IP address as the source IP address for both configured peers and discovered peers.
- On the 7210 SAS-Mxp, 7210 SAS-R6, 7210 SAS-R12, and 7210 SAS-T, 1 pps and 10 MHz interface signals should only be used when PTP is enabled. Use these signals only after determining that the system is configured to use PTP as a reference and is locked to PTP.
- The 7210 SAS-S 1/10GE does not support IEEE 1588v2 PTP.
- On the 7210 SAS-Mxp, 7210 SAS-R6, 7210 SAS-R12, 7210 SAS-Sx 1/10GE, and 7210 SAS-T, PTP port-based timestamping is enabled by default on all ports for all PTP packets at system bootup.
- When this feature is enabled, PTP packets are not forwarded transparently through the node, regardless of the service used and whether PTP is configured as a system clock reference. To enable transparent forwarding, refer to PTP Message Transparent Forwarding.
- Regardless of whether PTP is enabled (configure>sync-if-timing>ptp>no shutdown) or disabled (configure>sync-if-timing>ptp>shutdown), the timestamp value stored in the correction-field (CF) is updated for all PTP packets that are in transit through the node. This affects all PTP packets that are not originated or terminated on the node.To prevent this occurrence, disable PTP port-based hardware timestamps on specific (all or select) ports by configuring the configure>port>no ptp-hw-timestamp CLI command on ports where PTP packets are in transit. When the feature is disabled, PTP packets in transit are transparently forwarded without changing the timestamp value.
6.5.12. Configuration to Change Reference from SyncE to PTP on 7210 SAS-M
On 7210 SAS-M, use of PTP and SyncE as a reference simultaneously is not allowed. The user can configure either SyncE or PTP as a reference, but not both at the same time.
Perform the following configuration steps to change the reference from SyncE to PTP.
| Note: This procedure is required only on 7210 SAS-M nodes. |
- To configure standalone PTP as a reference, run the following commands:configure >system >ptp >no shutdownconfig> system> sync-if-timing> beginptpno shutdownexitref-order ptp [Must be configured]config> system> sync-if-timing> commitAfter the preceding commands are run, the frequency and time are provided by PTP only.
- To change the reference to syncE, run the following commands:config> system> sync-if-timing> beginptpshutdownexitconfig> system> sync-if-timing> commitconfig> system> sync-if-timing> beginref1source-port 1/1/10no shutdownexitref2source-port 1/1/11no shutdownexitref-order ref1 ref2 --------> Or, the ref-order you want [But Must be configured]revert ---------------------> If you want ref-order you have setup to take effectql-selection -------------------> Optional, if we need Quality to be considered.config> system> sync-if-timing> commitAfter the preceding commands are run, the frequency is provided by SyncE and TOD is provided by PTP [configure>system>ptp>no shutdown]. This is called PTP Hybrid mode.
- To revert to standalone PTP from SyncE, run the following commands:config> system> sync-if-timing> beginref1source-port 1/1/10 --------------------> Not Required if port is already configured, but in admin down stateshutdownexitref2source-port 1/1/11 --------------------> Not Required if port is already configured, but in admin down stateshutdownexitconfig> system> sync-if-timing> commitconfig> system> sync-if-timing> beginptpno shutdownexitref-order ptp [Must be configured]config> system> sync-if-timing> commitAfter the preceding commands are run, the frequency and time are provided by PTP [configure>system>ptp>no shutdown] only. This is a standalone PTP mode.
6.5.13. Configuration Example to Use PTP and SyncE References on 7210 SAS-Mxp, 7210 SAS-R6, 7210 SAS-R12, 7210 SAS-Sx 1/10GE, and 7210 SAS-T
The 7210 SAS-Mxp, 7210 SAS-R6, 7210 SAS-R12, 7210 SAS-Sx 1/10GE, and 7210 SAS-T support the configuration of PTP and SyncE references at the same time. On these platforms, ref-order can be set to config>system>sync-if-timing>ref-order ref1 ref2 ptp.
The following configuration example shows the use of PTP and syncE references simultaneously:
6.6. Management of 1830 VWM
| Note: This feature is only supported on the 7210 SAS-M, 7210 SAS-T, 7210 SAS-Mxp, 7210 SAS-R6, and 7210 SAS-R12. |
The 7210 SAS supports the use and management of the 1830 VWM CWDM and 1830 VWM DWDM clip-on device. 1830 VWM is a family of cost-optimized managed WDM passive devices, which is add-on shelf/NE and provides CWDM/DWDM extension to devices that do not have in-built CWDM/DWDM capabilities. The 1830 VWM can act as a Fixed Channel Optical Add-Drop Multiplexer (FOADM) or multiplexer/demultiplexer unit. It allows operators to use the existing fiber (or use less fiber) and increase the bandwidth capacity available for carrying service traffic.
For more information about 1830 VWM, see 1830 VWM product user guides.
To manage the device, the operator should plug in the 1830 VWM shelf to the USB port on the 7210 SAS-M. The 7210 SAS-T, 7210 SAS-Mxp, 7210 SAS-R6, and 7210 SAS-R12 manage the 1830 VWM device using the Optical Management Console (OMC) port.
6.6.1. Introduction
The 1830 VWM device can be used in point-to-point or ring deployments to multiplex multiple CWDM/DWDM channels over a single fiber. Either the existing fiber is reused or a single fiber is used to meet the increasing demand for service bandwidth. Up to 8 fixed CWDM channels are multiplexed over a single fiber using this unit.
Figure 32 shows 5 CWDM channels that are multiplexed over a single fiber.
Figure 32: Optical Ring with 7210 SAS and 1830 VWM Passive Optical unit
There are two types of ring locations. One is a channel termination location, with the 1830 PSS-32 that optically terminates all the channels using either the 4-channel or the 8-channel termination module. The second location is the intermediate OADM sites with 7210 SAS-M. These sites use the CWDM passive units to add or drop a channel in both directions (east and west), for the node to process traffic. Additionally, these sites provide express lanes for all other channels (that is, those not processed locally by the node). The 1830 VWM provides an option to add or drop up to 1, 2, 4 channels of fixed wavelength for local processing by the node.
6.6.2. Feature Description
The 1830 VWM clip-on device can be connected to the 7210 SAS node (the master shelf) using the USB interface or the OMC interface, depending on the interface supported by the 7210 SAS platform. Each of these clip-on devices is identified using the shelf ID, which is set on the rotary dial provided on the device.
To assist inventory management, the operator must use the configure>system>vwm-shelf vwm-shelf-id vwm-type vwm-type create CLI command to configure the vwm-shelf-id of the clip-on device attached to the 7210 SAS node. The vwm-shelf-id must match the shelf ID that is set on the rotary dial of the clip-on device. 7210 SAS devices use the configured vwm-shelf-id to communicate with the clip-on device. If the shelf IDs do not match, the 7210 SAS cannot communicate with the device and does not provide any information about the device. The 7210 SAS cannot detect a mismatch between the configured vwm-shelf-id and the shelf ID set on the rotary dial.
Depending on the type of supported interface, USB or OMC, the 7210 SAS node can manage only a fixed number of 1830 VWM devices. The software prevents attempts to configure more 1830 VWM devices than can be supported by the interface in use. Use the show command supported by the 7210 SAS devices to display the shelf inventory and alarm status information provided by the clip-on device.
In addition to inventory management, 7210 SAS supports provisioning of cards inserted into the slots available on the 1830 VWM devices. Before the card can be managed by the 7210 SAS, the user must provision the card and card type (also known as module type). The 7210 SAS detects and reports provisioning mismatches for the card. It also detects and reports insertion and removal of the card/module from the slot on the 1830 VWM device.
The 1830 DWDM supports active and passive units. The first 1830 DWDM device that is connected to a 7210 SAS node using the OMC port or the USB port must be equipped with active DWDM controllers; passive DWDM controllers can be used in the other chassis connected to the first device in a stacked configuration. In other words, the first 1830 DWDM device that is connected to the OMC port or the USB port of the 7210 SAS node must not be a passive 1830 DWDM device, but subsequent chassis in the stacked configuration can be equipped with passive DWDM controllers. Refer to the 1830 VWM User Guide for information about making the decision to equip active or passive DWDM controllers on the other chassis in the stacked configuration.
| Note: The 7210 SAS also auto detects the device type when any supported device is connected to the USB interface. Only approved USB mass storage devices and optical clip-on devices plugged in to the USB port are recognized as valid devices. Use of unsupported devices results in the generation of an error log. A shelf created by the user will be operationally down when an unrecognized device is plugged into the USB port. The user can interchange the device connected to the USB port without requiring a reboot. For example, when the 7210 SAS is operating with a clip-on device you can pull out the clip-on device and plug-in a USB mass-storage device to copy image files or other files, and then plug back a clip-on device. |
6.6.2.1. 1830 CWDM Shelf Layout and Description
| Note: The 1830 CWDM shelf shown in Figure 33 is an example. For definitive information about the 1830 CWDM device and support, refer to the 1830 CWDM product manuals. |
Figure 33 shows an example of the 1830 CWDM passive device.
Figure 33: 1830 CWDM Shelf Layout

In Figure 33, Slot 1 is dedicated to the controller card. The controller card, which is named using the acronym EC-CW for the 1830 CWDM device, does not require explicit provisioning. The card type is automatically provisioned when the user configures the 1830 VWM shelf type.
If the controller card is not present in Slot 1 of the shelf, the 1830 CWDM device operates as a passive filter and is not managed by the 7210 SAS. The 7210 SAS provides inventory and equipment management capability only when the controller card is present in the shelf and connected to the 7210 SAS.
Slot 2 and Slot 3 shown in Figure 33 can be equipped with supported CWDM filter cards. The user must provision the cards that populate the slots. The 7210 SAS software checks to ensure a match between the equipped and provisioned card type; an event is logged if a mismatch is detected.
6.6.2.2. 1830 DWDM Shelf Layout and Description
Figure 34 shows the 1830 DWDM shelf and the entities that can be managed by 7210 SAS.
Figure 34: 1830 DWDM Shelf Layout
The following information applies to the management of the 1830 DWDM shown in Figure 34.
- Slot 1 and Slot 2 host the DWDM Power and Controller modules (either EC-DW or EC-DWA). These slots host the Equipment Controller; power is provided by the Service NE (using EC-DW unit) or the TRU (using EC-DWA unit) in accordance with the system configuration and the Equipment Controller used. A rotary switch located on the top side of the Equipment Controller is used to set the SHELF_ID. In a stacked configuration, each Shelf_ID must be uniquely set. The Shelf_ID must be identical for the active and standby controllers in a shelf.
- Slot 1 and Slot 2 are not directly provisioned by the user in the 7210 SAS. The user must provision and configure the vwm-type managed by the 7210 SAS. The vwm-type can be provisioned as ec-cw, ec-dw, or ec-dwa, indicating that the shelf is a CWDM passive shelf or a DWDM passive shelf or a DWDM active shelf.
- The first 1830 DWDM device that is connected to the OMC port or the USB port of the 7210 SAS node must be equipped with the active DWDM controllers; it must not be a passive 1830 DWDM device. However, subsequent chassis connected to the first 1830 DWDM device in a stacked configuration can be equipped with passive DWDM controllers.
- Slot 3 and Slot 4 are capable of hosting DWDM filters (MUX/Demux), optical amplifiers, and Bulk Power Management (BPM) module. These slots must be explicitly provisioned on the 7210 SAS to allow management by the 7210 SAS. The 7210 SAS can manage the following cards:
- all DWDM filter (remote and manual filter and all of 2-channel, 4-channel and 8-channel)
- fan module
- BPM module (which allows for the aggregation of 44 DWDM channels using SFD44 unit) is not supported
- The 7210 SAS host tracks the following events related to the modules in Slot 3 and Slot 4:
- line card/module removal and insertion
- provisioning mismatch, if the provisioned line card does not match the equipped line card
- LoS alarm reported by the card/module for remote filter. The LoS alarm is cleared by the ec-dw/ec-dwa based on the threshold configured VOA.
- monitoring power levels for remote filter is not supported and configuration of power thresholds for automatic power monitoring feature supported by the remote filter units is not allowed
- 1830 DWDM fan module insertion and removal
- Slot 5 hosts the fans or the Inventory Extension Module (IN/MOD). If the 7210 SAS is managing the 1830 device, provisioning Slot 5 is not supported. As a result, only the fan module can be equipped in the slot; IN/MOD is not supported.
6.6.3. 1830 VWM Configuration Guidelines and Restrictions
The 7210 SAS manages the 1830 VWM CWDM/DWDM clip-on device, and inventory, and displays information about the clip-on device including part numbers, clip-on type, manufacturing dates, firmware revision, and status of alarms. The 7210 SAS also supports provisioning of modules that can be inserted into the available slots on the 1830 device. The following are the configuration guidelines and restrictions that apply to the 1830 VWM.
- The shelf-ID on the rotary dial must be set to a numeric value between 1 to 7. Digits higher than 7 are not supported by 7210 SAS devices.
- The 1830 VWM clip-on device is connected to a master-shelf (for example, a 7210 SAS device). Each clip-on device is identified using the shelf ID set on the rotary dial provided on the device. To aid inventory management, the user must configure the vwm-shelf-id of the clip-on device attached to the USB interface or the OMC interface. The vwm-shelf-id must match the shelf ID that is set using the rotary dial on the clip-on device. The 7210 SAS uses the configured vwm-shelf-id to communicate with the clip-on device. If the two shelf IDs do not match, the 7210 SAS cannot interact with other devices and is unable to provide information about the device. The 7210 SAS cannot detect a mismatch between the configured vwm-shelf-id and the shelf ID set on the rotary dial.
- The 7210 SAS provides a show command to display the alarm status information communicated by the clip-on device.
- The 7210 SAS only recognizes approved USB mass storage and optical clip-on devices need as valid devices when plugged in the USB port. All other devices are treated as unsupported and cause the 7210 SAS to generate an error log. A shelf created by the user is operationally down when an unrecognized device is plugged into the USB port.
- OMC ports must be used for 1830 DWDM device management on 7210 SAS-T and 7210 SAS-Mxp. USB ports are not supported on these platforms.
- Management of the 1830 DWDM device is not supported on the 7210 SAS-R6 and 7210 SAS-R12.
- Only a single 1830 CWDM or DWDM device can be managed using the USB interface.
- The management capabilities available through USB and OMC port are similar.
- The first 1830 DWDM device that is connected to the OMC port or the USB port of the 7210 SAS node must be equipped with active DWDM controllers; it must not be a passive 1830 DWDM device. However, subsequent chassis connected to the first 1830 DWDM device in a stacked configuration are allowed to be equipped with passive DWDM controllers. For more information about stacking configuration, refer to the 1830 VWM product manuals.
- The number of DWDM or CWDM devices that are supported in a stacked configuration managed by the 7210 SAS is limited. Please contact your Nokia representative for information about the number of units supported.
- In a stacked or cascaded configuration, all 1830 VWM units connected to the 7210 SAS must be of a similar type, either ec-cw or ec-dw/ec-dwa. A mix of CWDM and DWDM types is not supported.
| Note: The 1830 VWM allows for a mix of passive DWDM and active DWDM devices in a stacked configuration; the configuration is supported on all 7210 SAS platforms. |
6.6.3.1. 1830 VWM LED Functionality
Table 39 and Table 40 describe the LED functionality of the device.
Table 39: LED Functionality for 7210 SAS and 1830 VWM (CWDM)
Events | 7210 SAS major alarm LED | Optical shelf controller LED | Optical shelf line card LED |
Shelf admin up and shelf is physically connected to 7210 SAS The shelf becomes operational up by default | No color | Green | Amber/green based on whether line card provisioned correctly or not |
Shelf is operationally up | No color | Green | Amber/green based on whether card-type provisioned correctly or not |
Line card admin up and operational down when card-type not provisioned correctly (that is, mismatch between provisioned and equipped type) | Red | Green | Amber for that line card LED |
Line card admin up and operational up when card-type correctly provisioned | No color | Green | Green for that line card LED |
Line card removed | Amber LED glows | Green | No LED glows (line card is removed) |
Line card inserted back | No color | Green | LED turns to green |
Table 40: LED Functionality for 7210 SAS and 1830 VWM (DWDM)
Events | 7210 SAS major alarm LED | Optical shelf controller LED | Optical shelf line card LED |
Shelf admin up and shelf is physically connected to 7210 SAS. The shelf becomes operational up by default | No color | Green | Amber/green based on whether line card provisioned correctly or not |
Shelf is operationally up | No color | Green | Amber/green based on whether card-type provisioned correctly or not |
Line card admin up and operational down when card-type not provisioned correctly (that is, mismatch between provisioned and equipped type) | Amber | Green | Amber for that line card LED |
Line card admin up and operational up when card-type correctly provisioned | No color | Green | Green for that line card LED |
Line card removed | Amber LED glows | Green | No LED glows (line card is removed) |
Line card inserted back | No color | Green | LED turns to green |
6.7. Link Layer Discovery Protocol (LLDP)
The IEEE 802.1ab Link Layer Discovery Protocol (LLDP) is a unidirectional protocol that uses the MAC layer to transmit specific information about the capabilities and status of the local device. The LLDP can send as well as receive information from a remote device stored in the related MIB (or MIBs).
The LLDP does not contain a mechanism to solicit information received from other LLDP agents or to confirm the receipt of information. However, LLDP provides the flexibility to enable a transmitter and receiver separately, and the following LLDP agent configurations are allowed:
- only transmit information
- only receive information
- transmit and receive information
The information fields in each LLDP frame are contained in an LLDP Data Unit (LLDPDU) as a sequence of variable length information elements. Each information element includes Type, Length, and Value fields (TLVs).
- Type indicates the nature of information being transmitted.
- Length indicates the length of the information string in octets.
- Value is the actual information that is transmitted. (For example, a binary bit map or an alphanumeric string that can contain one or more fields).
Each LLDPDU contains four mandatory TLVs and optional TLVs selected by the Network Management. The following is the format of an LLDPDU:
- Chassis ID TLV
- Port ID TLV
- Time To Live (TTL) TLV
- zero or more optional TLVs, depending on the maximum size of the LLDPDU allowed
- End of LLDPDU TLV
A concatenated string formed by the Chassis ID TLV and the Port ID TLV is used by a recipient to identify an LLDP port or agent. The combination of the Port ID and Chassis ID TLVs remains unchanged until the port or agent is operational.
The TTL field of a Time-To-Live TLV can be a zero or non-zero value. A zero TTL field value notifies the receiving LLDP agent to immediately discard all information related to sending LLDP agent. A non-zero TTL field value indicates the time duration for which the receiving LLDP agent should retain the information of the sending LLDP agent. The receiving LLDP agent discards all information related to the sending LLDP agent after the time interval indicated in the TTL field is complete.
| Note: A TTL zero value is used to signal that the sending LLDP port has initiated a port shutdown procedure. |
The End Of LLDPDU TLV indicates the end of the LLDPDU.
The following information is included in the protocol as defined by the IEEE 802.1ab standard.
- Connectivity and management information about the local station to adjacent stations on the same IEEE 802 LAN is advertised.
- Network management information from adjacent stations on the same IEEE 802 LAN is received.
- It operates with all IEEE 802 access protocols and network media.
- Network management information schema and object definitions suitable for storing connection information about adjacent stations is established.
- It supports compatibility with a number of MIBs.
6.8. System Resource Allocation
This section describes system resource allocation including the allocation of TCAM resources, configuration guidelines and examples.
6.8.1. Allocation of Ingress Internal TCAM Resources
In previous releases, the system statically allocated ingress TCAM resources for use by SAP ingress QoS classification, SAP ingress access control list (ACLs), identifying and sending CFM OAM packets to CPU for local processing, and so on. The resource allocation is not user-configurable. With the introduction of new capabilities including IPv6 classification, UP MEP support, and G8032-fast-flood, the static allocation of resources by software does not meet requirements of customers who typically want to use different features.
The user can allocate a fixed amount of resources per system (or per card on 7210 SAS-R6 and 7210 SAS-R12 devices) for QoS, ACLs, CFM/Y.1731 MEPs and other features. Of these, some parameters are boot-time parameters and others are run-time. A change in the current value of a boot-time parameter needs a node reboot or, on 7210 SAS-R6 and 7210 SAS-R12 devices, a card reset using the reset command, before the new value takes effect. Change in the current value of a parameter that is designated run-time takes effect immediately if the software determines that resources are available for use to accommodate the change.
On the 7210 SAS-M, 7210 SAS-T, 7210 SAS-Sx/S 1/10GE, 7210 SAS-Sx 10/100GE, and 7210 SAS-Mxp, the system resource profile parameters are available using the config>system>resource-profile CLI context and the defined parameters are applicable to the entire node. On the 7210 SAS-R6 and 7210 SAS-R12, the parameters are defined as a system resource profile policy that the user must configure and associate with the IMM. The software reads the configured policy and allocates resources appropriately per IMM, allowing users to allocate resources to different features per IMM. On the 7210 SAS-R6 and 7210 SAS-R12, some system resource profile parameters apply to the entire node and not just the IMM. For more information, see System Resource-Profile Router Commands for 7210 SAS-M, 7210 SAS-T, 7210 SAS-Mxp, 7210 SAS-Sx 1/10GE, and 7210 SAS-Sx 10/100GE.
During bootup, the system reads the resource profile parameters and allocates resources to features in the order they appear in the configuration file.
| Note: The order in which the command appears in the configuration file is important. |
Because resources are shared, the user must ensure that the sum total of such resources does not exceed the limit supported by the IMM or node. If the system determines that it cannot allocate the requested resources, the feature is disabled. For example, if the system determines that it cannot allocate resources for g8032-fast-flood, it disables the feature from use and G8032 eth-rings will not be able to use fast-flood mechanisms). Another example is the case where the system determines that it cannot allocate resources for IPv4-based SAP Ingress ACL classification, the system will not allow users to use IPv4-based SAP ingress ACL classification feature and fails the configuration when it comes upon the first SAP in the configuration file that uses an IPv4-based SAP ingress ACL policy.
For boot-time parameters, such as g8032-fast-flood-enable, the user must ensure that the configured services match the resources allocated. If the system determines that it cannot allocate resources to services, it fails the configuration file at the first instance where it encounters a command to which resources cannot be allocated. The available resources can be allocated to different features.
For ACL and QoS resources, the user has the option to allocate resources to limit usage per feature, regardless of the match criteria used. The sum of all resources used for different SAP ingress classification match-criteria is limited by the amount of resources allocated for SAP ingress classification. The user can also allocate resources by specific match criteria. The user can enable any supported match criteria and associate a fixed amount of resources with each match criteria in fixed sizes; the chunk size is dependent on the platform.
The system allocates resources based on the order of appearance in the configuration file, and fails any match criteria if the system does not have any more resources to allocate. In addition, the max keyword can be used to indicate that the system needs to allocate resources when they are first required, as long as the maximum amount of resources allocated for that feature is not exceeded or the maximum amount of resources available in the system is not exceeded. The 7210 SAS platforms allocate resources to each feature and match-criteria in fixed-size chunks.
The no form of the resource-profile command disables the use of the corresponding match criteria or feature by deallocating all the resources allocated to the criteria or feature. For example:
- Configuring the system resource-profile internal-ingress-tcam qos-sap-ingress-resource no mac-match-enable command deallocates all the resources allocated to SAP ingress QoS classification MAC match criteria. After this command is run, users cannot associate a SAP ingress policy with MAC match criteria defined to a SAP. Resources allocated to other criteria are unaffected and can continue to be used.
- Configuring the system resource-profile internal-ingress-tcam eth-cfm no up-mep command deallocates all the resources allocated to CFM UP MEP. After this command is run, user cannot configure UP MEP.
If the system successfully runs the no command, it frees up resources used by the chunk or slice and make the resources, or the entire chunk/slice, available for use by other features. Before deallocating resources, the software checks if a service object is using the resource and fails the command if the object is in use. If resources are in use, they can be freed up by deleting a SAP, removing a policy association with a SAP, deleting a MEP, and so on. Some commands under the system resource-profile context do not take effect immediately and require a system reboot before the change occurs and resources are freed. The following is the handling of freed resources.
- If some entries in a slice are freed, they are made available for use by other SAPs using the same feature to which the chunk is allocated.
- If an entire chunk is freed, it is returned to the system free pool for possible use by other features.
For more information about specific CLI commands and features that use system resource allocation, refer to the CLI command and feature descriptions in the appropriate 7210 SAS software user manual.
6.8.2. Allocation of Egress Internal TCAM Resources
Before the introduction of new capabilities, such as IPv6 match criteria, the system allocated egress TCAM resources on bootup for use by different criteria in SAP egress access control lists (ACLs) and other purposes; the resource allocation was not user configurable. With the introduction of new capabilities, such as IPv6 match criteria in egress, the static allocation of resources by software may not meet customer requirements if they want to use different features. Therefore, to facilitate user configuration and resource allocation in accordance with user needs, the ingress internal TCAM resource allocation capabilities have been extended to include the egress internal TCAM resources.
For information about specific CLI commands and features that use system resource allocation, refer to the CLI command and feature descriptions in the appropriate 7210 SAS software user manuals.
| Note: The commands in the config>system>resource-profile context, which require a reboot to take effect, are read and implemented by the system only during bootup. These commands do not take effect if the exec command is used to run the configuration file. |
6.8.3. System Resource Allocation Examples
This section provides system resource allocation examples.
Example 1:
In the preceding CLI example, the system performs the following actions.
- 3 chunks are allocated for use by the SAP ingress ACL entries.
- 1 chunk is allocated for use by SAP ingress ACL entries that use ipv4-criteria. The system fails the configuration when the number of ACL entries that use ipv4-criteria exceeds the configured limit (that is, the system does not allocate in excess of the configured limit of 1 chunk).
- A chunk is allocated for use by SAP ingress ACL entries that use mac-criteria. After the max keyword is specified, the system allocates 1 chunk for use when an ingress ACL policy (with mac-criteria entries defined) is associated with a SAP. The system can allocate up to 2 chunks because the max keyword is used. More chunks are allocated when the user configures a SAP that uses mac-criteria and all entries in the allocated chunks are used up. The system fails the configuration if the number of ACL entries with mac-criteria exceeds the limit of 2 chunks allocated to SAP ingress ACL match (that is, the system does not allocate in excess of the configured limit of 3 chunks; up to 2 chunks of the configured 3 chunk limit are allocated to mac-criteria and 1 chunk is allocated to ipv4-criteria).
- The system fails a user attempt to use SAP ingress ACLs with IPv6 match criteria (and other combinations listed in the preceding list items), because the user has disabled these criteria.
Example 2:
In the preceding CLI example, the system performs the following actions.
- 3 chunks are allocated for use by the SAP ingress ACL entries. These resources are available for use with mac-criteria, ipv4-criteria and ipv6-64-bit match criteria.
- 1 chunk is allocated for use by SAP ingress ACL entries that use ipv4-criteria. The system fails the configuration if the number of ACL entries using ipv4-criteria exceeds the configured limit (that is, the system does not allocate more than the configured limit of 1 chunk).
- 1 chunk is allocated for use by SAP ingress ACL entries that use mac-criteria when the user associates an ingress ACL policy (with mac-criteria entries defined) with a SAP. Because the max keyword is used, the system can allocate more chunks, if a chunk is available for use.In this example, (assuming a SAP with an ingress ACL policy that uses ipv6-64-bit criteria is configured), as no additional chunks are available, mac-criteria cannot allocate more than 1 chunk (even if the max keyword is specified). The system fails the configuration if the number of ACL entries with mac-criteria exceeds the limit of 1 chunk allocated to SAP ingress ACL mac-criteria (that is, the system does not allocate more than the configured limit of 3 chunks = 1 for mac-criteria + for ipv4-criteria + 1 for ipv6-criteria).
- A chunk is allocated for use by SAP ingress ACL entries that use ipv6-64-bit criteria when the user associates an ingress ACL policy (with ipv6-64-bit-criteria entries defined) with a SAP. Because the max keyword is specified, the system can allocate more chunks, if a chunk is available for use.In this example, as there are no more chunks available, ipv6-64-bit criteria cannot allocate more than 1 chunk (even if the max keyword is specified). The system fails the configuration when the number of ACL entries with ipv6-64-bit criteria exceeds the limit of one chunk allocated to SAP ingress ACL match (that is, the system does not allocate more than the configured limit of 3 chunks = 1 for mac-criteria + 1 for ipv4-criteria + 1 for ipv6-64-bit criteria).
- The system fails any attempt to use SAP ingress ACLs with ipv6-128 bit match criteria (and the other combinations listed above), because the user has disabled these criteria.
In Example 2, the user can run no ipv4-match-enable command to disable the use of ipv4-criteria. The system checks for SAPs that use ipv4-criteria and if found, fails the command; otherwise, the chunk freed for use with either mac-criteria or ipv6-64-bit criteria. The entire chunk is allocated to mac-criteria if the first SAP that needs resources requests for mac-criteria and no entries in the chunk are already allocated to mac-criteria, which leaves no resources for use by ipv6-64-bit criteria. In the same way, the entire chunk is allocated to ipv6-64-bit criteria, if the first SAP that needs resources requests for ipv6-64-bit criteria and no entries in the chunk are already allocated to ipv6-64-bit criteria, which leaves no resources for use by mac-criteria.
6.8.4. 7210 SAS-R6 and 7210 SAS-R12 Configuration Guidelines for System Resource Profile
The following configuration guidelines apply to 7210 SAS-R6 and 7210 SAS-R12.
- The user can change the system-resource policy attached to a card/IMM in the following cases:
- when the card/IMM state is unprovisioned
- when the card/IMM is provisioned but not equipped
- when the card/IMM is provisioned and equipped, but there is a mismatch between the two
- Upon provisioning the card, subsequent to attaching a new system-resource policy, the parameters specified in the policy are used (including any boot-time parameters).
- If the card is provisioned and equipped, and any boot-time parameter is changed in the system-resource policy, the user must issue the card reset command for all cards that are using the policy or reboot the chassis, for the policy change to take effect.
6.9. System Configuration Process Overview
Figure 35 shows the process to provision basic system parameters.
Figure 35: System Configuration and Implementation Flow
6.10. Configuration Notes
This section describes system configuration caveats.
To access the CLI, ensure that the 7210 SAS device is properly initialized and the boot loader and BOFs have successfully executed.