3. OAM and SAA
This chapter provides information about the Operations, Administration, and Management (OAM) and Service Assurance Agent (SAA) commands available in the CLI for troubleshooting services.
3.1. OAM overview
Delivery of services requires a number of operations occur correctly and at different levels in the service delivery model. For example, operations such as the association of packets to a service, must be performed correctly in the forwarding plane for the service to function correctly. To verify that a service is operational, a set of in-band, packet-based Operation, Administration, and Maintenance (OAM) tools is required, with the ability to test each of the individual packet operations.
For in-band testing, the OAM packets closely resemble customer packets to effectively test the customer forwarding path, but they are distinguishable from customer packets so they are kept within the service provider network and not forwarded to the customer.
The suite of OAM diagnostics supplement the basic IP ping and traceroute operations with diagnostics specialized for the different levels in the service delivery model. There are diagnostics for services.
| Note: The following OAM features are supported on all 7210 SAS platforms as described in this document, except those operating in access-uplink mode:
|
3.1.1. LSP diagnostics: LSP ping and trace
| Note: P2MP LSP references in this section apply only to the 7210 SAS-Mxp, 7210 SAS-R6, 7210 SAS-R12, 7210 SAS-Sx/S 1/10GE (standalone and standalone-VC mode), and 7210 SAS-T. |
This section provides a generalized description of the LSP diagnostics tools. Users should take into account the following restrictions when reading the information contained in this section:
- The 7210 SAS does not support LDP LER ECMP. Descriptions of LDP ECMP as an LER node in LSP diagnostics: LSP ping and trace do not apply to 7210 SAS platforms.
- LDP LSR ECMP is only supported on 7210 SAS-Mxp, 7210 SAS-Sx/S 1/10GE, 7210 SAS-Sx 10/100GE, 7210 SAS-R6, and 7210 SAS-R12. The description on LDP ECMP as LSR node applies only to these platforms.
- 7210 SAS platforms support LDP and BGP 3107 labeled routes. The 7210 SAS does not support LDP FEC stitching to BGP 3107 labeled route to LDP FEC stitching and vice-versa. The following description about stitching of BGP 3107 labeled routes to LDP FEC is provided to describe the behavior in an end-to-end network solution deployed using 7210 SAS and 7x50 nodes, with 7210 SAS nodes acting as the LER node.
| Note: 7210 SAS platforms do not support the use of ECMP routes for BGP 3107 labeled routes. The feature description is provided in this section for completeness and better understanding of the behavior in the end-to-end network solution deployed using 7210 SAS and 7750 nodes. |
The router LSP diagnostics are implementations of LSP ping and LSP trace based on RFC 4379, Detecting Multi-Protocol Label Switched (MPLS) Data Plane Failures. LSP ping provides a mechanism to detect data plane failures in MPLS LSPs. LSP ping and LSP trace are modeled after the ICMP echo request/reply used by ping and trace to detect and localize faults in IP networks.
For a specific LDP FEC, RSVP P2P LSP, or BGP IPv4 Label Router, LSP ping verifies whether the packet reaches the egress label edge router (LER), while in LSP trace mode, the packet is sent to the control plane of each transit label switched router (LSR) which performs various checks to see if it is actually a transit LSR for the path.
The downstream mapping TLV is used in LSP ping and LSP trace to provide a mechanism for the sender and responder nodes to exchange and validate interface and label stack information for each downstream of an LDP FEC or an RSVP LSP and at each hop in the path of the LDP FEC or RSVP LSP.
Two downstream mapping TLVs are supported: the original Downstream Mapping (DSMAP) TLV defined in RFC 4379 and the new Downstream Detailed Mapping (DDMAP) TLV defined in RFC 6424.
When the responder node has multiple equal cost next-hops for an LDP FEC prefix, the downstream mapping TLV can further be used to exercise a specific path of the ECMP set using the path-destination option. The behavior in this case is described in the following ECMP subsection.
3.1.1.1. LSP ping/trace for an LSP using a BGP IPv4 label route
This feature adds support of the target FEC stack TLV of type BGP Labeled IPv4 /32 Prefix as defined in RFC 4379.
The new TLV is structured as shown in the following figure.
Figure 7: Target FEC stack TLV for a BGP labeled IPv4 prefix

The user issues a LSP ping using the existing CLI command and specifying a new type of prefix:
oam lsp-ping bgp-label prefix ip-prefix/mask [src-ip-address ip-address] [fc fc-name] [size octets] [ttl label-ttl] [send-count send-count] [timeout timeout] [interval interval] [path-destination ip-address [interface if-name | next-hop ip-address]] [detail]
The path-destination option is used for exercising specific ECMP paths in the network when the LSR performs hashing on the MPLS packet.
Similarly, the user issues a LSP trace using the following command:
oam lsp-trace bgp-label prefix ip-prefix/mask [src-ip-address ip-address] [fc fc-name] [max-fail no-response-count] [probe-count probes-per-hop] [size octets] [min-ttl min-label-ttl] [max-ttl max-label-ttl] [timeout timeout] [interval interval] [path-destination ip-address [interface if-name | next-hop ip-address]] [detail]
The following are the procedures for sending and responding to an LSP ping or LSP trace packet. These procedures are valid when the downstream mapping is set to the DSMAP TLV. The detailed procedures with the DDMAP TLV are presented in Using DDMAP TLV in LSP stitching and LSP hierarchy:
- The next-hop of a BGP label route for a core IPv4 /32 prefix is always resolved to an LDP FEC or an RSVP LSP. Therefore, the sender node encapsulates the packet of the echo request message with a label stack which consists of the LDP/RSVP outer label and the BGP inner label.If the packet expires on an RSVP or LDP LSR node which does not have context for the BGP label IPv4 /32 prefix, it validates the outer label in the stack and if the validation is successful it replies the same way as it does today when it receives an echo request message for an LDP FEC which is stitched to a BGP IPv4 label route. That is, it replies with return code 8 “Label switched at stack-depth <RSC>.”
- The LSR node that is the next-hop for the BGP label IPv4 /32 prefix as well as the LER node that originated the BGP label IPv4 prefix both have full context for the BGP IPv4 target FEC stack and, as a result, can perform full validation of it.
- If the BGP IPv4 label route is stitched to an LDP FEC, the egress LER for the resulting LDP FEC will not have context for the BGP IPv4 target FEC stack in the echo request message and replies with return code 4 “Replying router has no mapping for the FEC at stack- depth <RSC>.” This is the same behavior as that of an LDP FEC which is stitched to a BGP IPv4 label route when the echo request message reaches the egress LER for the BGP prefix.
| Note: Only BGP label IPv4 /32 prefixes are supported because these are usable as tunnels on nodes. BGP label IPv6 /128 prefixes are not currently usable as tunnels on a node and are not supported in LSP ping or trace. |
3.1.1.2. ECMP considerations
| Note: BGP 3107 labelled route ECMP is not supported on 7210 SAS platforms. References to BGP 3107 labelled route ECMP are included in this section only for completeness of the feature description. |
When the responder node has multiple equal cost next-hops for an LDP FEC or a BGP label IPv4 prefix, it replies in the DSMAP TLV with the downstream information of the outgoing interface that is part of the ECMP next-hop set for the prefix.
However, when a BGP label route is resolved to an LDP FEC (of the BGP next-hop of the BGP label route), ECMP can exist at both the BGP and LDP levels. The following next-hop selection is performed in this case:
- For each BGP ECMP next hop of the label route, a single LDP next hop is selected even if multiple LDP ECMP next hops exist. Therefore, the number of ECMP next hops for the BGP IPv4 label route is equal to the number of BGP next-hops.
- ECMP for a BGP IPv4 label route is only supported at the provider edge (PE) router (BGP label push operation) and not at ABR and ASBR (BGP label swap operation). Therefore, at an LSR, a BGP IPv4 label route is resolved to a single BGP next hop, which is resolved to a single LDP next hop.
- LSP trace will return one downstream mapping TLV for each next-hop of the BGP IPv4 label route. It will also return the exact LDP next-hop that the datapath programmed for each BGP next-hop.
In the following description of LSP ping and LSP trace behavior, generic references are made to specific terms as follows: FEC can represent either an LDP FEC or a BGP IPv4 label router, and a Downstream Mapping TLV can represent either the DSMAP TLV or the DDMAP TLV:
- If the user initiates an LSP trace of the FEC without the path-destination option specified, the sender node does not include multi-path information in the Downstream Mapping TLV in the echo request message (multipath type=0). In this case, the responder node replies with a Downstream Mapping TLV for each outgoing interface that is part of the ECMP next-hop set for the FEC. The sender node will select the first Downstream Mapping TLV only for the subsequent echo request message with incrementing TTL.
- If the user initiates an LSP ping of the FEC with the path-destination option specified, the sender does not include the Downstream Mapping TLV. However, the user can configure the interface option, part of the same path-destination option, to direct the echo request message at the sender node to be sent from a specific outgoing interface that is part of an ECMP path set for the FEC.
- If the user initiates an LSP trace of the FEC with the path-destination option specified but configured to exclude a Downstream Mapping TLV in the MPLS echo request message using the CLI command downstream-map-tlv {none}, the sender node does not include the Downstream Mapping TLV. However, the user can configure the interface option, part of the same path-destination option, to direct the echo request message at the sender node to be sent out a specific outgoing interface that is part of an ECMP path set for the FEC.
- If the user initiates an LSP trace of the FEC with the path-destination option specified, the sender node includes the multipath information in the Downstream Mapping TLV in the echo request message (multipath type=8). The path-destination option allows the user to exercise a specific path of a FEC in the presence of ECMP. The user enters a specific address from the 127/8 range, which is then inserted in the multipath type 8 information field of the Downstream Mapping TLV. The CPM code at each LSR in the path of the target FEC runs the same hash routine as the datapath and replies in the Downstream Mapping TLV with the specific outgoing interface the packet would have been forwarded to if it had not expired at this node and if the DEST IP field in the packet’s header was set to the 127/8 address value inserted in the multipath type 8 information.
- The ldp-treetrace tool always uses the multipath type=8 value and inserts a range of 127/8 addresses instead of a single address to exercise multiple ECMP paths of an LDP FEC. The behavior is the same as the lsp-trace command with the path-destination option enabled.
- The path-destination option can also be used to exercise a specific ECMP path of an LDP FEC tunneled over an RSVP LSP or ECMP path of an LDP FEC stitched to a BGP FEC in the presence of BGP ECMP paths. The user must enable the use of the DDMAP TLV either globally (config>test-oam>mpls-echo-request-downstream-map ddmap) or within the specific ldp-treetrace or LSP trace test (downstream-map-tlv ddmap option).
3.1.1.3. LSP ping and LSP trace over unnumbered IP interface
LSP ping and P2MP LSP ping operate over a network using unnumbered links without any changes. LSP trace, P2MP LSP trace and LDP treetrace are modified such that the unnumbered interface is correctly encoded in the downstream mapping (DSMAP/DDMAP) TLV.
In a RSVP P2P or P2MP LSP, the upstream LSR encodes the downstream router ID in the Downstream IP Address field and the local unnumbered interface index value in the Downstream Interface Address field of the DSMAP/DDMAP TLV as per RFC 4379. Both values are taken from the TE database.
In a LDP unicast FEC or mLDP P2MP FEC, the interface index assigned by the peer LSR is not readily available to the LDP control plane. In this case, the alternative method described in RFC 4379 is used. The upstream LSR sets the Address Type to IPv4 Unnumbered, the Downstream IP Address to a value of 127.0.0.1, and the interface index is set to 0. If an LSR receives an echo-request packet with this encoding in the DSMAP/DDMAP TLV, it will bypass interface verification but continue with label validation.
3.1.1.4. Downstream Detailed Mapping (DDMAP) TLV
The DDMAP TLV provides with exactly the same features as the existing DSMAP TLV, plus the enhancements to trace the details of LSP stitching and LSP hierarchy. The latter is achieved using a new sub-TLV of the DDMAP TLV called the FEC stack change sub-TLV. Figure 8 and Figure 9 show the structures of these two objects as defined in RFC 6424.
Figure 8: DDMAP TLV

The DDMAP TLV format is derived from the DSMAP TLV format. The key change is that variable length and optional fields have been converted into sub-TLVs. The fields have the same use and meaning as in RFC 4379.
Figure 9: FEC stack change sub-TLV

The operation type specifies the action associated with the FEC stack change. The following operation types are defined.
More details on the processing of the fields of the FEC stack change sub-TLV are provided later in this section.
The user can configure which downstream mapping TLV to use globally on a system by using the following command:
configure test-oam mpls-echo-request-downstream-map {dsmap | ddmap}
This command specifies which format of the downstream mapping TLV to use in all LSP trace packets and LDP tree trace packets originated on this node. The Downstream Mapping (DSMAP) TLV is the original format in RFC 4379 and is the default value. The Downstream Detailed Mapping (DDMAP) TLV is the new enhanced format specified in RFC 6424.
This command applies to LSP trace of an RSVP P2P LSP, a MPLS-TP LSP, a BGP IPv4 Label Route, or LDP unicast FEC, and to LDP tree trace of a unicast LDP FEC. It does not apply to LSP trace of an RSVP P2MP LSP which always uses the DDMAP TLV.
The global DSMAP/DDMAP setting impacts the behavior of both OAM LSP trace packets and SAA test packets of type lsp-trace and is used by the sender node when one of the following events occurs:
- An SAA test of type lsp-trace is created (not modified) and no value is specified for the per-test downstream-map-tlv {dsmap | ddmap | none} option. In this case the SAA test downstream-map-tlv value defaults to the global mpls-echo-request-downstream-map value.
- An OAM test of type lsp-trace test is executed and no value is specified for the per-test downstream-map-tlv {dsmap | ddmap | none} option. In this case, the OAM test downstream-map-tlv value defaults to the global mpls-echo-request-downstream-map value.
A consequence of the preceding rules is that a change to the value of mpls-echo-request-downstream-map option does not affect the value inserted in the downstream mapping TLV of existing tests.
The following are the details of the processing of the new DDMAP TLV:
- When either the DSMAP TLV or the DDMAP TLV is received in an echo request message, the responder node will include the same type of TLV in the echo reply message with the correct downstream interface information and label stack information.
- If an echo request message without a Downstream Mapping TLV (DSMAP or DDMAP) expires at a node which is not the egress for the target FEC stack, the responder node always includes the DSMAP TLV in the echo reply message. This can occur in the following cases:
- The user issues a LSP trace from a sender node with a min-ttl value higher than 1 and a max-ttl value lower than the number of hops to reach the egress of the target FEC stack. This is the sender node behavior when the global configuration or the per-test setting of the DSMAP/DDMAP is set to DSMAP.
- The user issues a LSP ping from a sender node with a ttl value lower than the number of hops to reach the egress of the target FEC stack. This is the sender node behavior when the global configuration of the DSMAP/DDMAP is set to DSMAP.
- The behavior in (a) is changed when the global configuration or the per-test setting of the Downstream Mapping TLV is set to DDMAP. The sender node will include in this case the DDMAP TLV with the Downstream IP address field set to the all-routers multicast address as per Section 3.3 of RFC 4379. The responder node then bypasses the interface and label stack validation and replies with a DDMAP TLV with the correct downstream information for the target FEC stack.
- A sender node never includes the DSMAP or DDMAP TLV in an LSP ping message.
3.1.1.5. Using DDMAP TLV in LSP stitching and LSP hierarchy
In addition to performing the same features as the DSMAP TLV, the new DDMAP TLV addresses the following scenarios:
- Full validation of an LDP FEC stitched to a BGP IPv4 label route. In this case, the LSP trace message is inserted from the LDP LSP segment or from the stitching point.
- Full validation of a BGP IPv4 label route stitched to an LDP FEC. The LSP trace message is inserted from the BGP LSP segment or from the stitching point.
- Full validation of an LDP FEC which is stitched to a BGP LSP and stitched back into an LDP FEC. In this case, the LSP trace message is inserted from the LDP segments or from the stitching points.
- Full validation of an LDP FEC tunneled over an RSVP LSP using LSP trace.
- Full validation of a BGP IPv4 label route tunneled over an RSVP LSP or an LDP FEC.
To correctly check a target FEC which is stitched to another FEC (stitching FEC) of the same or a different type, or which is tunneled over another FEC (tunneling FEC), it is necessary for the responding nodes to provide details about the FEC manipulation back to the sender node. This is achieved via the use of the new FEC stack change sub-TLV in the Downstream Detailed Mapping TLV (DDMAP) defined in RFC 6424.
When the user configures the use of the DDMAP TLV on a trace for an LSP that does not undergo stitching or tunneling operation in the network, the procedures at the sender and responder nodes are the same as in the case of the existing DSMAP TLV.
This feature however introduces changes to the target FEC stack validation procedures at the sender and responder nodes in the case of LSP stitching and LSP hierarchy. These changes pertain to the processing of the new FEC stack change sub-TLV in the new DDMAP TLV and the new return code 15 Label switched with FEC change. The following is a description of the main changes which are a superset of the rules described in Section 4 of RFC 6424 to allow greater scope of interoperability with other vendor implementations.
3.1.1.5.1. Responder node procedures
The following are responder node procedures:
- As a responder node, the node will always insert a global return code return code of either3 Replying router is an egress for the FEC at stack-depth <RSC> or14 See DDMAP TLV for Return Code and Return Subcode.
- When the responder node inserts a global return code of 3, it will not include a DDMAP TLV.
- When the responder node includes the DDMAP TLV, it inserts a global return code 14 See DDMAP TLV for Return Code and Return Subcode and:
- On a success response, include a return code of 15 in the DDMAP TLV for each downstream which has a FEC stack change TLV.
- On a success response, include a return code 8 Label switched at stack-depth <RSC> in the DDMAP TLV for each downstream if no FEC stack change sub-TLV is present.
- On a failure response, include an appropriate error return code in the DDMAP TLV for each downstream.
- A tunneling node indicates that it is pushing a FEC (the tunneling FEC) on top of the target FEC stack TLV by including a FEC stack change sub-TLV in the DDMAP TLV with a FEC operation type value of PUSH. It also includes a return code 15 Label switched with FEC change. The downstream interface address and downstream IP address fields of the DDMAP TLV are populated for the pushed FEC. The remote peer address field in the FEC stack change sub-TLV is populated with the address of the control plane peer for the pushed FEC. The Label stack sub-TLV provides the full label stack over the downstream interface.
- A node that is stitching a FEC indicates that it is performing a POP operation for the stitched FEC followed by a PUSH operation for the stitching FEC and potentially one PUSH operation for the transport tunnel FEC. It will therefore include two or more FEC stack change sub-TLVs in the DDMAP TLV in the echo reply message. It also includes and a return code 15 Label switched with FEC change. The downstream interface address and downstream address fields of the DDMAP TLV are populated for the stitching FEC. The remote peer address field in the FEC stack change sub-TLV of type POP is populated with a null value (0.0.0.0). The remote peer address field in the FEC stack change sub-TLV of type PUSH is populated with the address of the control plane peer for the tunneling FEC. The Label stack sub-TLV provides the full label stack over the downstream interface.
- If the responder node is the egress for one or more FECs in the target FEC Stack, then it must reply with no DDMAP TLV and with a return code 3 Replying router is an egress for the FEC at stack-depth <RSC>. RSC must be set to the depth of the topmost FEC.This operation is iterative in a sense that at the receipt of the echo reply message the sender node will pop the topmost FEC from the target stack FEC TLV and resend the echo request message with the same TTL value as described in (5) as follows. The responder node will therefore perform exactly the same operation as described in this step until all FECs are popped or until the topmost FEC in the target FEC stack TLV matches the tunneled or stitched FEC. In the latter case, processing of the target FEC stack TLV follows again steps (1) or (2).
3.1.1.5.2. Sender node procedures
The following are sender node procedures:
- If the echo reply message contains the return code 14 See DDMAP TLV for Return Code and Return Subcode and the DDMAP TLV has a return code 15 Label switched with FEC change, the sender node adjusts the target FEC Stack TLV in the echo request message for the next value of the TTL to reflect the operation on the current target FEC stack as indicated in the FEC stack change sub-TLV received in the DDMAP TLV of the last echo reply message. That is, one FEC is popped at most and one or more FECs are pushed as indicated.
- If the echo reply message contains the return code 3 Replying router is an egress for the FEC at stack-depth <RSC>, then:
- If the value for the label stack depth specified in the Return Sub-Code (RSC) field is the same as the depth of current target FEC Stack TLV, then the sender node considers the trace operation complete and terminates it. A responder node will cause this case to occur as per step (6) of the responder node procedures.
- If the value for the label stack depth specified in the Return Sub-Code (RSC) field is different from the depth of the current target FEC Stack TLV, the sender node must continue the LSP trace with the same TTL value after adjusting the target FEC stack TLV by removing the top FEC. Note this step will continue iteratively until the value for the label stack depth specified in the Return Sub-Code (RSC) field is the same as the depth of current target FEC Stack TLV and in which case step (a) is performed. A responder node will cause this case to occur as per step (6) of the responder node procedures.
- If a DDMAP TLV with or without a FEC stack change sub-TLV is included, then the sender node must ignore it and processing is performed as per steps (a) or (b) preceding. A responder node will not cause this case to occur but a third party implementation may do.
- As a sender node, the can accept an echo-reply message with the global return code of either 14 (with DDMAP TLV return code of 15 or 8), or15 and process correctly the FEC stack change TLV as per step (1) of the sender node procedures.
- If an LSP ping is performed directly to the egress LER of the stitched FEC, there is no DDMAP TLV included in the echo request message and therefore the responder node, which is the egress node, will still reply with return code 4 Replying router has no mapping for the FEC at stack- depth <RSC>. This case cannot be resolved with this feature.
| Note: The following limitation applies when a BGP IPv4 label route is resolved to an LDP FEC which is resolved to an RSVP LSP all on the same node. This 2-level LSP hierarchy is not supported as a feature on SR OS but the user is not prevented from configuring it. In that case, user and OAM packets are forwarded by the sender node using two labels (T-LDP and BGP). The LSP trace will fail on the downstream node with return code 1 Malformed echo request received because there is no label entry for the RSVP label. |
3.1.2. MPLS OAM support in segment routing
| Note: This feature is supported only on the 7210 SAS-Mxp, 7210 SAS-R6 (IMM-b and IMM-c only), 7210 SAS-R12 (IMM-b and IMM-c only), and 7210 SAS-Sx/S 1/10GE (standalone mode). |
MPLS OAM supports segment routing extensions to lsp-ping and lsp-trace as defined in draft-ietf-mpls-spring-lsp-ping.
When the data plane uses MPLS encapsulation, MPLS OAM tools such as lsp-ping and lsp-trace can be used to check connectivity and trace the path to any midpoint or endpoint of an SR-ISIS or SR-OSPF shortest path tunnel.
The CLI options for lsp-ping and lsp-trace are under OAM and SAA for SR-ISIS and SR-OSPF node SID tunnels.
3.1.2.1. SR extensions for LSP-PING and LSP-TRACE
This section describes how MPLS OAM models the SR tunnel types.
An SR shortest path tunnel, SR-ISIS or SR-OSPF tunnel, uses a single FEC element in the target FEC stack TLV. The FEC corresponds to the prefix of the node SID in a specific IGP instance.
The following figure shows the format of the IPv4 IGP-prefix segment ID.
Figure 10: IPv4 IGP-prefix SID format

In this format, the fields are as follows:
- IPv4 prefixThe IPv4 Prefix field carries the IPv4 prefix to which the segment ID is assigned. For an anycast segment ID, this field carries the IPv4 anycast address. If the prefix is shorter than 32 bits, trailing bits must be set to zero.
- Prefix lengthThe Prefix Length field is one octet. It gives the length of the prefix in bits; allowed values are 1 to 32.
- ProtocolThe Protocol field is set to 1 if the IGP protocol is OSPF and 2 if the IGP protocol is IS-IS.
Both lsp-ping and lsp-trace apply to the following contexts:
- SR-ISIS or SR-OSPF shortest path IPv4 tunnel
- SR-ISIS IPv4 tunnel stitched to an LDP IPv4 FEC
- BGP IPv4 LSP resolved over an SR-ISIS IPv4 tunnel or an SR-OSPF IPv4 tunnel; including support for BGP LSP across AS boundaries and for ECMP next-hops at the transport tunnel level
3.1.2.2. Operating guidelines on SR-ISIS or SR-OSPF tunnels
The following operating guidelines apply to lsp-ping and lsp-trace:
- The sender node builds the target FEC stack TLV with a single FEC element corresponding to the destination node SID of the SR-ISIS or SR-OSPF tunnel.
- A node SID label swapped at the LSR results in return code 8, “Label switched at stack-depth <RSC>” in accordance with RFC 4379.
- A node SID label that is popped at the LSR results in return code 3, “Replying router is an egress for the FEC at stack-depth <RSC>”.
- The lsp-trace command is supported with the inclusion of the DSMAP TLV, the DDMAP TLV, or none. If none is configured, no map TLV is sent. The downstream interface information is returned, along with the egress label for the node SID tunnel and the protocol that resolved the node SID at the responder node.
The following figure shows a sample topology for an lsp-ping and lsp-trace for SR-ISIS node SID tunnels.
Figure 11: Testing MPLS OAM with SR tunnels
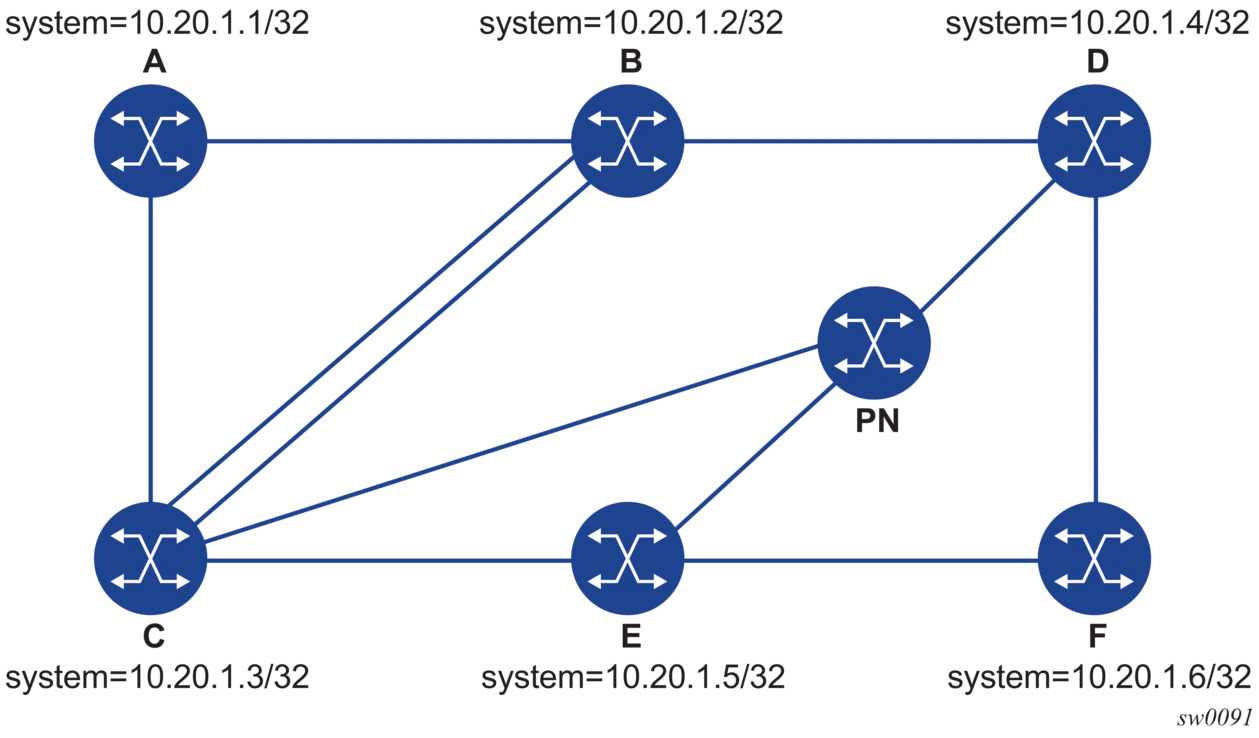
Given this topology, the following output is an example of LSP-PING on DUT-A for target node SID on DUT-F.
The following output is an example of LSP-TRACE on DUT-A for target node SID on DUT-F (DSMAP TLV):
The following output is an example of LSP-TRACE on DUT-A for target node SID onDUT-F (DDMAP TLV).
3.1.2.3. Operating guidelines on SR-ISIS tunnel stitched to LDP FEC
The following operating guidelines apply to lsp-ping and lsp-trace:
- The responder and sender nodes must be in the same domain (SR or LDP) for lsp-ping tool operation.
- The lsp-trace tool can operate in both LDP and SR domains. When used with the DDMAP TLV, lsp-trace provides the details of the SR-LDP stitching operation at the boundary node. The boundary node as a responder node replies with the FEC stack change TLV, which contains the following operations:
- a PUSH operation of the SR (LDP) FEC in the LDP-to-SR (SR-to-LDP) direction
- a POP operation of the LDP (SR) FEC in the LDP-to-SR (SR-to-LDP) direction
The following is an output example of the lsp-trace command of the DDMAP TLV for LDP-to-SR direction (symmetric topology LDP-SR-LDP).
The following output is an example of the lsp-trace command of the DDMAP TLV for SR-to-LDP direction (symmetric topology LDP-SR-LDP).
3.1.2.4. Operation on a BGP IPv4 LSP resolved over an SR-ISIS IPv4 tunnel or an SR-OSPF IPv4 tunnel
The 7210 SAS enhances lsp-ping and lsp-trace of a BGP IPv4 LSP resolved over an SR-ISIS IPv4 tunnel or an SR-OSPF IPv4 tunnel. The 7210 SAS enhancement reports the full set of ECMP next-hops for the transport tunnel at both ingress PE and at the ABR or ASBR. The list of downstream next-hops is reported in the DSMAP or DDMAP TLV.
If an lsp-trace of the BGP IPv4 LSP is initiated with the path-destination option specified, the CPM hash code at the responder node selects the outgoing interface to return in the DSMAP or DDMAP TLV. The decision is based on the modulo operation of the hash value on the label stack or the IP headers (where the DST IP is replaced by the specific 127/8 prefix address in the multipath type 8 field of the DSMAP or DDMAP) of the echo request message and the number of outgoing interfaces in the ECMP set.
The following figure shows a sample topology used in the subsequent BGP over SR-OSPF and BGP over SR-ISIS examples.
Figure 12: Sample topology for BGP over SR-OSPF and SR-ISIS
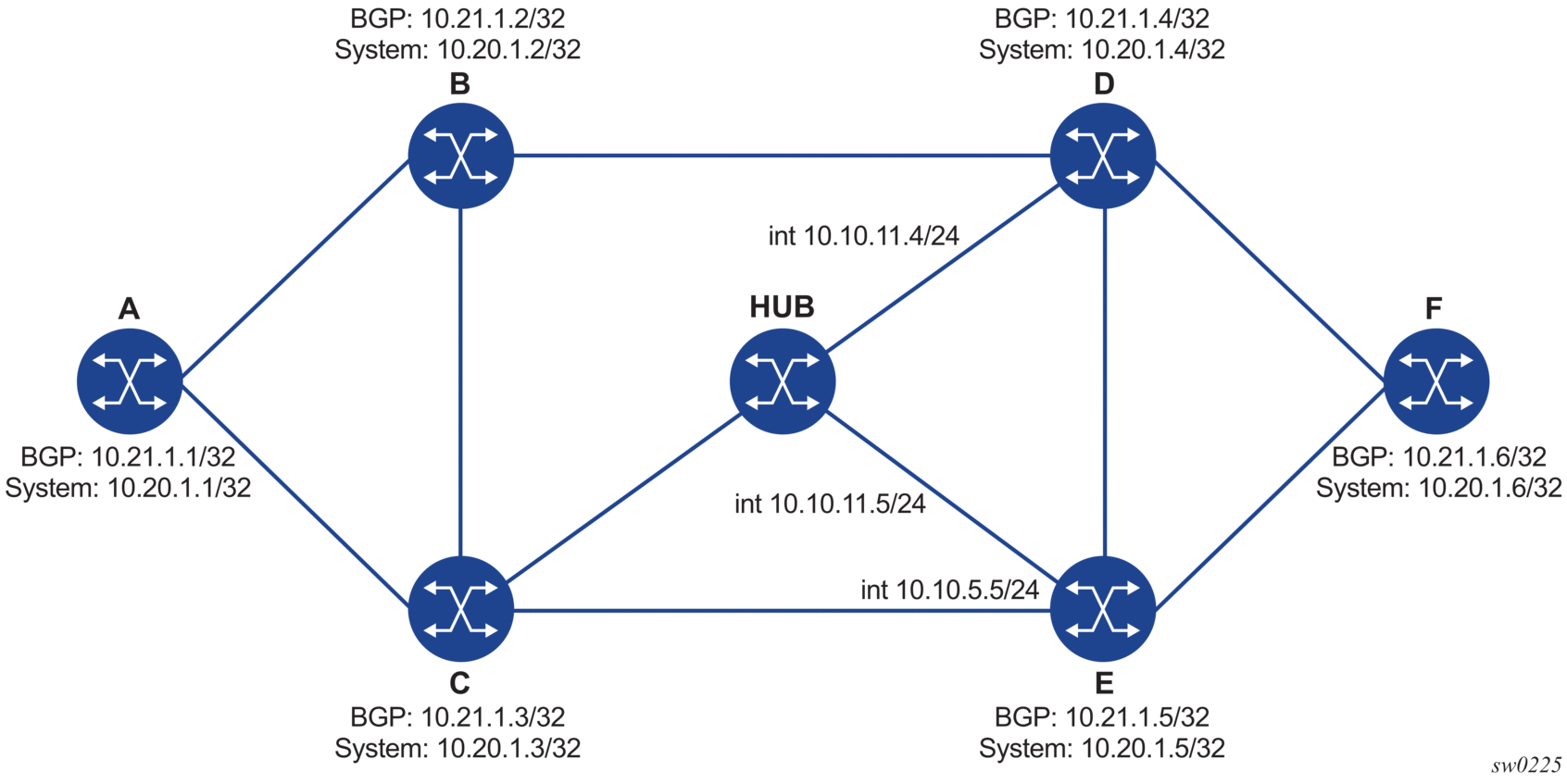
The following outputs are examples of the lsp-trace command for a hierarchical tunnel consisting of a BGP IPv4 LSP resolved over an SR-ISIS IPv4 tunnel or an SR-OSPF IPv4 tunnel.
The following output is an example of BGP over SR-OSPF.
The following output is an example of BGP over SR-ISIS.
Assuming the topology in the following figure includes an eBGP peering between nodes B and C, the BGP IPv4 LSP spans the AS boundary and resolves to an SR-ISIS tunnel within each AS.
Figure 13: Sample topology for BGP over SR-ISIS in inter-AS option C
The following output is an example of BGP over SR-ISIS using inter-AS option C.
3.1.3. LSP ping for RSVP P2MP LSP
Note:
|
Enter the following OAM command to generate an LSP ping:
oam p2mp-lsp-ping lsp-name [p2mp-instance instance-name [s2l-dest-addr ip-address [...up to 5 max]]] [fc fc-name] [size octets] [ttl label-ttl] [timeout timeout] [detail]
An echo request message is sent on the active P2MP instance and replicated in the datapath over all branches of the P2MP LSP instance. By default, all egress LER nodes that are leaves of the P2MP LSP instance reply to the echo request message.
To reduce the scope of the echo reply message, explicitly enter a list of addresses specifying the egress LER nodes that must reply. A maximum of five addresses can be specified in a single execution of the p2mp-lsp-ping command. If all five egress LER nodes are router nodes, they will parse the list of egress LER addresses and reply. In accordance with RFC 6425, only the top address in the P2MP egress identifier TLV is inspected by an egress LER. When interoperating with other implementations, the egress LER router node responds if its address is in the list. Also, if another vendor implementation is the egress LER, only the egress LER matching the top address in the TLV responds.
If the user enters the same egress LER address more than once in a single p2mp-lsp-ping command, the head-end node displays a response to a single address and displays a single error warning message for the duplicates. When queried over SNMP, the head-end node issues a single response trap and issues no trap for the duplicates.
Set the value of the timeout parameter to the time it would take to get a response from all probed leaves under no failure conditions. For that purpose, the parameter range extends to 120 seconds for a p2mp-lsp-ping from a 10-second lsp-ping for P2P LSP. The default value is 10 seconds.
If the user explicitly lists the address of the egress LER for a specific S2L in the ping command, the router head-end node displays a “Send_Fail” error when a specific S2L path is down.
Similarly, if the user explicitly lists the address of the egress LER for a specific S2L in the ping command, the router head-end node displays the timeout error when no response is received for an S2L after the expiry of the timeout timer.
Configure a specific value of the ttl parameter to force the echo request message to expire on a router branch node or a bud LSR node. The bud LSR node replies with a downstream mapping TLV for each branch of the P2MP LSP in the echo reply message. A maximum of 16 downstream mapping TLVs can be included in a single echo reply message. The multipath type is set to zero in each downstream mapping TLV and, consequently, does not include egress address information for the reachable egress LER nodes for this P2MP LSP.
If the router ingress LER node receives the new multipath type field with the list of egress LER addresses in an echo reply message from another vendor implementation, the router ignores the message, but this does not cause a processing error for the downstream mapping TLV.
If the ping command expires at an LSR node that is performing a remerge or crossover operation in the datapath between two or more ILMs of the same P2MP LSP, an echo reply message is generated for each copy of the echo request message received by this node.
If the detail parameter is omitted, the command output provides a high-level summary of error and success codes received.
If the detail parameter is specified, the command output displays a line for each replying node, similar to the output of the LSP ping for a P2P LSP.
The display is delayed until all responses are received or the timer configured in the timeout parameter expires. Entering other CLI commands while waiting for the display is not allowed. Use control-C (^C) to stop the ping operation.
3.1.4. LSP trace for RSVP P2MP LSP
Note:
|
Generate an LSP trace by entering the following OAM command:
oam p2mp-lsp-trace lsp-name p2mp-instance instance-name s2l-dest-addr ip-address [fc fc-name] [size octets] [max-fail no-response-count] [probe-count probes-per-hop] [min-ttl min-label-ttl]] [max-ttl max-label-ttl] [timeout timeout] [interval interval] [detail]
The LSP trace capability allows the user to trace the path of a single S2L path of a P2MP LSP. Its operation is similar to that of the p2mp-lsp-ping command but the sender of the echo reply request message includes the downstream mapping TLV to request the downstream branch information from a branch LSR or bud LSR. The branch LSR or bud LSR will then also include the downstream mapping TLV to report the information about the downstream branches of the P2MP LSP. An egress LER does not include this TLV in the echo response message.
The operation of the probe-count parameter is modeled after the LSP trace on a P2P LSP. It represents the maximum number of probes sent per TTL value before the device gives up on receiving the echo reply message. If a response is received from the traced node before reaching the maximum number of probes, no additional probes are sent for that TTL. The sender of the echo request increments the TTL and uses the information received in the downstream mapping TLV to send probes to the node downstream of the last node that replied. This continues until the egress LER for the traced S2L path replies.
Because the command traces a single S2L path, the timeout and interval parameters keep the same value range as the LSP trace for a P2P LSP.
The following supported options in lsp-trace for P2P LSP are not applicable: path, prefix, path-destination, and [interface | next-hop].
The P2MP LSP trace uses the Downstream Detailed Mapping (DDMAP) TLV defined in RFC 6424. The following figure shows the format of the new DDMAP TLV entered in the path-destination that belongs to one of the possible outgoing interfaces of the FEC.
Figure 14: DDMAP TLV
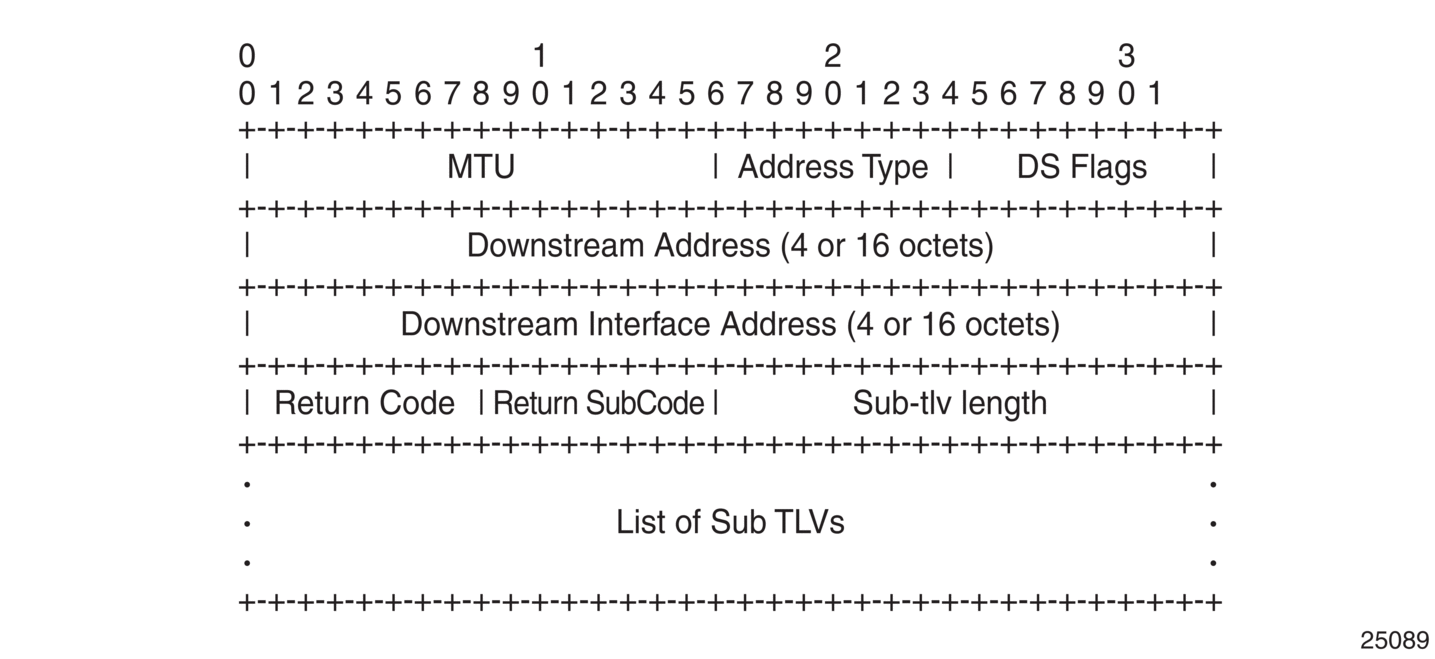
The DDMAP TLV format is derived from the Downstream Mapping (DSMAP) TLV format. The key change is that in the DDMAP TLV, the variable length and optional fields are converted into sub-TLVs. The fields have the same use and meaning as in RFC 4379.
Similar to P2MP LSP ping, an LSP trace probe results on all egress LER nodes that eventually receive the echo request message, but only the traced egress LER node replies to the last probe.
Any branch LSR node or bud LSR node in the P2MP LSP tree may receive a copy of the echo request message with the TTL in the outer label expiring at this node. However, only a branch LSR or bud LSR that has a downstream branch over which the traced egress LER is reachable must respond.
When a branch LSR or BUD LSR node responds to the sender of the echo request message, it sets the global return code in the echo response message to RC=14, “See DDMAP TLV for Return Code and Return Sub-Code” and the return code in the DDMAP TLV corresponding to the outgoing interface of the branch used by the traced S2L path to RC=8, “Label switched at stack-depth <RSC>”.
Because a single egress LER address, for example an S2L path, can be traced, the branch LSR or bud LSR node sets the multipath type to zero in the downstream mapping TLV in the echo response message because including an egress LER address is not required.
3.1.4.1. LSP trace behavior when S2L path traverses a re-merge node
| Note: P2MP LSPs are supported only on the 7210 SAS-Mxp, 7210 SAS-R6, 7210 SAS-R12, 7210 SAS-Sx/S 1/10GE (standalone and standalone-VC mode), and 7210 SAS-T. |
When a node performs a re-merge of one or more ILMs of the P2MP LSP to which the traced S2L sub-LSP belongs, it may block the ILM over which the traced S2L resides. This causes the trace to either fail or to succeed with a missing hop.
The following is an example of this behavior:
S2L1 and S2L2 use ILMs that re-merge at node B. Depending of which ILM is blocked at B, the TTL=2 probe will either yield two responses or timeout.
- Tracing S2L1 when ILM on interface C-B blocked at node B:
- For TTL=1, A gets a response from C only as B does not have S2L1 on the ILM on interface A-B.
- For TTL=2, assume A gets first the response from B which indicates a success. It then builds the next probe with TTL=3. B will only pass the copy of the message arriving on interface A-B and will drop the one arriving on interface C-B (treats it like a data packet since it does not expire at node B). This copy will expire at F. However F will return a "DSMappingMismatched" error because the DDMAP TLV was the one provided by node B in TTL=2 step. The trace will abort at this point in time. However, A knows it got a second response from Node D for TTL=2 with a "DSMappingMismatched" error.
- If A gets the response from D first with the error code, it waits to see if it gets a response from B or it times out. In either case, it will log this status as multiple replies received per probe in the last probe history and aborts the trace.
- Tracing S2L2 when ILM on interface A-B blocked at node B:
- For TTL=1, B responds with a success. C does not respond as it does not have an ILM for S2L2.
- For TTL=2, B drops the copy coming on interface A-B. It receives a copy coming on interface B-C but will drop it as the ILM does not contain S2L2. Node A times out. Next, node A generates a probe with TTL=3 without a DDMAP TLV. This time node D will respond with a success and will include its downstream DDMAP TLV to node E. The rest of the path will be discovered correctly. The traced path for S2L2 will look something like: A-B-(*)-D-E.
The router ingress LER detects a re-merge condition when it receives two or more replies to the same probe, such as the same TTL value. It displays the following message to the user regardless if the trace operation successfully reached the egress LER or was aborted earlier:
This warning message indicates to the user the potential of a re-merge scenario and that a p2mp-lsp-ping command for this S2L should be used to verify that the S2L path is not defective.
The router ingress LER behavior is to always proceed to the next ttl probe when it receives an OK response to a probe or when it times out on a probe. If however it receives replies with an error return code, it must wait until it receives an OK response or it times out. If it times out without receiving an OK reply, the LSP trace must be aborted.
The following are possible echo reply messages received and corresponding ingress LER behavior:
- One or more error return codes + OK: display OK return code. Proceed to next ttl probe. Display warning message at end of trace.
- OK + One or more error return codes: display OK return code. Proceed to next ttl probe right after receiving the OK reply but keep state that more replies received. Display warning message at end of trace.
- OK + OK: should not happen for re-merge but would continue trace on 1st OK reply. This is the case when one of the branches of the P2MP LSP is activating the P2P bypass LSP. In this case, the head-end node will get a reply from both a regular P2MP LSR which has the ILM for the traced S2L and from an LSR switching the P2P bypass for other S2Ls. The latter does not have context for the P2MP LSP being tunneled but will respond after doing a label stack validation.
- One error return code + timeout: abort LSP trace and display error code. Ingress LER cannot tell the error is due to a re-merge condition.
- More than one error return code + timeout: abort LSP trace and display first error code. Display warning message at end of trace.
- Timeout on probe without any reply: display “*” and proceed to next ttl probe.
3.1.5. SDP diagnostics
The 7210 SAS SDP diagnostics are SDP ping and SDP MTU path discovery.
3.1.5.1. SDP ping
SDP ping performs in-band uni-directional or round-trip connectivity tests on SDPs. The SDP ping OAM packets are sent in-band, in the tunnel encapsulation, so it will follow the same path as traffic within the service. The SDP ping response can be received out-of-band in the control plane, or in-band using the data plane for a round-trip test.
For a uni-directional test, SDP ping tests:
- egress SDP ID encapsulation
- ability to reach the far-end IP address of the SDP ID within the SDP encapsulation
- path MTU to the far-end IP address over the SDP ID
- forwarding class mapping between the near-end SDP ID encapsulation and the far-end tunnel termination
For a round-trip test, SDP ping uses a local egress SDP ID and an expected remote SDP ID. Since SDPs are uni-directional tunnels, the remote SDP ID must be specified and must exist as a configured SDP ID on the far-end 7210 SAS. SDP round trip testing is an extension of SDP connectivity testing with the additional ability to test:
- remote SDP ID encapsulation
- potential service round trip time
- round trip path MTU
- round trip forwarding class mapping
3.1.5.2. SDP MTU path discovery
In a large network, network devices can support a variety of packet sizes that are transmitted across its interfaces. This capability is referred to as the Maximum Transmission Unit (MTU) of network interfaces. It is important to understand the MTU of the entire path end-to-end when provisioning services, especially for virtual leased line (VLL) services where the service must support the ability to transmit the largest customer packet.
The Path MTU discovery tool provides a powerful tool that enables service provider to get the exact MTU supported by the network's physical links between the service ingress and service termination points (accurate to one byte).
3.1.6. Service diagnostics
-The Nokia Service ping feature provides end-to-end connectivity testing for an individual service. Service ping operates at a higher level than the SDP diagnostics in that it verifies an individual service and not the collection of services carried within an SDP.
Service ping is initiated from a 7210 SAS router to verify round-trip connectivity and delay to the far-end of the service. -The Nokia implementation functions for MPLS tunnels and tests the following from edge-to-edge:
- tunnel connectivity
- VC label mapping verification
- service existence
- service provisioned parameter verification
- round trip path verification
- service dynamic configuration verification
3.1.7. VPLS MAC diagnostics
While the LSP ping, SDP ping and service ping tools enable transport tunnel testing and verify whether the correct transport tunnel is used, they do not provide the means to test the learning and forwarding functions on a per-VPLS-service basis.
It is conceivable, that while tunnels are operational and correctly bound to a service, an incorrect Forwarding Information Base (FIB) table for a service could cause connectivity issues in the service and not be detected by the ping tools. Nokia has developed VPLS OAM functionality to specifically test all the critical functions on a per-service basis. These tools are based primarily on the IETF document draft-stokes-vkompella-ppvpn-hvpls-oam-xx.txt, Testing Hierarchical Virtual Private LAN Services.
The VPLS OAM tools are:
- Provides an end-to-end test to identify the egress customer-facing port where a customer MAC was learned. MAC ping can also be used with a broadcast MAC address to identify all egress points of a service for the specified broadcast MAC.
- Provides the ability to trace a specified MAC address hop-by-hop until the last node in the service domain. An SAA test with MAC trace is considered successful when there is a reply from a far-end node indicating that they have the destination MAC address on an egress SAP or the CPM.
- Provides the ability to check network connectivity to the specified client device within the VPLS. CPE ping will return the MAC address of the client, as well as the SAP and PE at which it was learned.
- Allows specified MAC addresses to be injected in the VPLS service domain. This triggers learning of the injected MAC address by all participating nodes in the service. This tool is generally followed by MAC ping or MAC trace to verify if correct learning occurred.
- Allows MAC addresses to be flushed from all nodes in a service domain.
3.1.7.1. MAC ping
For a MAC ping test, the destination MAC address (unicast or multicast) to be tested must be specified. A MAC ping packet can be sent through the control plane or the data plane. When sent by the control plane, the ping packet goes directly to the destination IP in a UDP/IP OAM packet. If it is sent by the data plane, the ping packet goes out with the data plane format.
In the control plane, a MAC ping is forwarded along the flooding domain if no MAC address bindings exist. If MAC address bindings exist, then the packet is forwarded along those paths (if they are active). Finally, a response is generated only when there is an egress SAP binding to that MAC address. A control plane request is responded to via a control reply only.
In the data plane, a MAC ping is sent with a VC label TTL of 255. This packet traverses each hop using forwarding plane information for next hop, VC label, etc. The VC label is swapped at each service-aware hop, and the VC TTL is decremented. If the VC TTL is decremented to 0, the packet is passed up to the management plane for processing. If the packet reaches an egress node, and would be forwarded out a customer facing port, it is identified by the following OAM label the VC label and passed to the management plane.
MAC pings are flooded when they are unknown at an intermediate node. They are responded to only by the egress nodes that have mappings for that MAC address.
3.1.7.2. MAC trace
A MAC trace functions like an LSP trace with some variations. Operations in a MAC trace are triggered when the VC TTL is decremented to 0.
Like a MAC ping, a MAC trace can be sent either by the control plane or the data plane.
For MAC trace requests sent by the control plane, the destination IP address is determined from the control plane mapping for the destination MAC. If the destination MAC is known to be at a specific remote site, then the far-end IP address of that SDP is used. If the destination MAC is not known, then the packet is sent unicast, to all SDPs in the service with the appropriate squelching.
A control plane MAC traceroute request is sent via UDP/IP. The destination UDP port is the LSP ping port. The source UDP port is whatever the system gives (note that this source UDP port is really the demultiplexor that identifies the particular instance that sent the request, when correlating the reply). The source IP address is the system IP of the sender.
When a traceroute request is sent via the data plane, the data plane format is used. The reply can be via the data plane or the control plane.
A data plane MAC traceroute request includes the tunnel encapsulation, the VC label, and the OAM, followed by an Ethernet DLC, a UDP and IP header. If the mapping for the MAC address is known at the sender, then the data plane request is sent down the known SDP with the appropriate tunnel encapsulation and VC label. If it is not known, then it is sent down every SDP (with the appropriate tunnel encapsulation per SDP and appropriate egress VC label per SDP binding).
The tunnel encapsulation TTL is set to 255. The VC label TTL is initially set to the min-ttl (default is 1). The OAM label TTL is set to 2. The destination IP address is the all-routers multicast address. The source IP address is the system IP of the sender.
The destination UDP port is the LSP ping port. The source UDP port is whatever the system gives (note that this source UDP port is really the demultiplexor that identifies the particular instance that sent the request, when correlating the reply).
The Reply Mode is either 3 (i.e., reply via the control plane) or 4 (i.e., reply through the data plane), depending on the reply-control option. By default, the data plane request is sent with Reply Mode 3 (control plane reply) Reply Mode 4 (data plane reply).
The Ethernet DLC header source MAC address is set to either the system MAC address (if no source MAC is specified) or to the specified source MAC. The destination MAC address is set to the specified destination MAC. The EtherType is set to IP.
3.1.7.3. CPE ping
The MAC ping OAM tool makes it possible to detect whether a particular MAC address has been learned in a VPLS.
The cpe-ping command extends this capability to detecting end-station IP addresses inside a VPLS. A CPE ping for a specific destination IP address within a VPLS will be translated to a MAC-ping toward a broadcast MAC address. Upon receiving such a MAC ping, each peer PE within the VPLS context will trigger an ARP request for the specific IP address. The PE receiving a response to this ARP request will report back to the requesting 7210 SAS. It is encouraged to use the source IP address of 0.0.0.0 to prevent the provider’s IP address of being learned by the CE.
3.1.7.4. MAC populate
MAC populate is used to send a message through the flooding domain to learn a MAC address as if a customer packet with that source MAC address had flooded the domain from that ingress point in the service. This allows the provider to craft a learning history and engineer packets in a particular way to test forwarding plane correctness.
The MAC populate request is sent with a VC TTL of 1, which means that it is received at the forwarding plane at the first hop and passed directly up to the management plane. The packet is then responded to by populating the MAC address in the forwarding plane, like a conventional learn although the MAC will be an OAM-type MAC in the FIB to distinguish it from customer MAC addresses.
This packet is then taken by the control plane and flooded out the flooding domain (squelching appropriately, the sender and other paths that would be squelched in a typical flood).
This controlled population of the FIB is very important to manage the expected results of an OAM test. The same functions are available by sending the OAM packet as a UDP/IP OAM packet. It is then forwarded to each hop and the management plane has to do the flooding.
Options for MAC populate are to force the MAC in the table to type OAM (in case it already existed as dynamic or static or an OAM induced learning with some other binding), to prevent new dynamic learning to over-write the existing OAM MAC entry, to allow customer packets with this MAC to either ingress or egress the network, while still using the OAM MAC entry.
Finally, an option to flood the MAC populate request causes each upstream node to learn the MAC, for example, populate the local FIB with an OAM MAC entry, and to flood the request along the data plane using the flooding domain.
An age can be provided to age a particular OAM MAC after a different interval than other MACs in a FIB.
3.1.7.5. MAC purge
MAC purge is used to clear the FIBs of any learned information for a particular MAC address. This allows one to do a controlled OAM test without learning induced by customer packets. In addition to clearing the FIB of a particular MAC address, the purge can also indicate to the control plane not to allow further learning from customer packets. This allows the FIB to be clean, and be populated only via a MAC Populate.
MAC purge follows the same flooding mechanism as the MAC populate.
A UDP/IP version of this command is also available that does not follow the forwarding notion of the flooding domain, but the control plane notion of it.
3.1.8. VLL diagnostics
3.1.8.1. VCCV ping
VCCV ping is used to check connectivity of a VLL in-band. It checks that the destination (target) PE is the egress for the Layer 2 FEC. It provides a cross-check between the data plane and the control plane. It is in-band, meaning that the VCCV ping message is sent using the same encapsulation and along the same path as user packets in that VLL. This is equivalent to the LSP ping for a VLL service. VCCV ping reuses an LSP ping message format and can be used to test a VLL configured over an MPLS SDP.
3.1.8.1.1. VCCV-ping application
VCCV effectively creates an IP control channel within the pseudowire between PE1 and PE2. PE2 should be able to distinguish on the receive side VCCV control messages from user packets on that VLL. There are three possible methods of encapsulating a VCCV message in a VLL which translates into three types of control channels:
- Use of a Router Alert Label immediately preceding the VC label. This method has the drawback that if ECMP is applied to the outer LSP label (for example, transport label), the VCCV message will not follow the same path as the user packets. This effectively means it will not troubleshoot the appropriate path. This method is supported by the 7210 SAS.
- Use of the OAM control word as illustrated in the following figure.
Figure 15: OAM control word format
 The first nibble is set to 0x1. The Format ID and the reserved fields are set to 0 and the channel type is the code point associated with the VCCV IP control channel as specified in the PWE3 IANA registry (RFC 4446). The channel type value of 0x21 indicates that the Associated Channel carries an IPv4 packet.The use of the OAM control word assumes that the draft-martini control word is also used on the user packets. This means that if the control word is optional for a VLL and is not configured, the PE node will only advertise the router alert label as the CC capability in the Label Mapping message. This method is supported on 7210 SAS configured in the network mode of operation.
The first nibble is set to 0x1. The Format ID and the reserved fields are set to 0 and the channel type is the code point associated with the VCCV IP control channel as specified in the PWE3 IANA registry (RFC 4446). The channel type value of 0x21 indicates that the Associated Channel carries an IPv4 packet.The use of the OAM control word assumes that the draft-martini control word is also used on the user packets. This means that if the control word is optional for a VLL and is not configured, the PE node will only advertise the router alert label as the CC capability in the Label Mapping message. This method is supported on 7210 SAS configured in the network mode of operation. - Set the TTL in the VC label to 1 to force PE2 control plane to process the VCCV message. This method is not guaranteed to work under all circumstances. For instance, the draft mentions some implementations of penultimate hop popping overwrite the TTL field. This method is not supported on the 7210 SAS.
When sending the label mapping message for the VLL, PE1 and PE2 must indicate which of the preceding OAM packet encapsulation methods (for example, which control channel type) they support. This is accomplished by including an optional VCCV TLV in the pseudowire FEC Interface Parameter field. The following figure shows the format of the VCCV TLV.
Figure 16: VCCV TLV format

Note that the absence of the optional VCCV TLV in the Interface parameters field of the pseudowire FEC indicates the PE has no VCCV capability.
The Control Channel (CC) Type field is a bitmask used to indicate if the PE supports none, one, or many control channel types, as follows:
- 0x00 None of the following VCCV control channel types are supported
- 0x01 PWE3 OAM control word (see Figure 15)
- 0x02 MPLS Router Alert Label
- 0x04 MPLS inner label TTL = 1
If both PE nodes support more than one of the CC types, a 7210 SAS PE will make use of the one with the lowest type value. For instance, OAM control word will be used in preference to the MPLS router alert label.
The Connectivity Verification (CV) bitmask field is used to indicate the specific type of VCCV packets to be sent over the VCCV control channel. The valid values are:
0x00 None of the following VCCV packet type are supported.
0x01 ICMP ping. Not applicable to a VLL over a MPLS SDP and as such is not supported by the 7210 SAS.
0x02 LSP ping. This is used in VCCV-Ping application and applies to a VLL over an MPLS SDP. This is supported by the 7210 SAS.
A VCCV ping is an LSP echo request message as defined in RFC 4379. It contains an L2 FEC stack TLV which must include within the sub-TLV type 10 “FEC 128 Pseudowire”. It also contains a field which indicates to the destination PE which reply mode to use. There are four reply modes defined in RFC 4379:
Reply mode, meaning:
- Do not reply. This mode is supported by the 7210 SAS.
- Reply via an IPv4/IPv6 UDP packet. This mode is supported by the 7210 SAS.
- Reply with an IPv4/IPv6 UDP packet with a router alert. This mode sets the router alert bit in the IP header and is not be confused with the CC type which makes use of the router alert label. This mode is not supported by the 7210 SAS.
- Reply via application level control channel. This mode sends the reply message in-band over the pseudowire from PE2 to PE1. PE2 will encapsulate the Echo Reply message using the CC type negotiated with PE1. This mode is supported by the 7210 SAS.
The reply is an LSP echo reply message as defined in RFC 4379. The message is sent as per the reply mode requested by PE1. The return codes supported are the same as those supported in the 7210 SAS LSP ping capability.
The VCCV ping feature is in addition to the service ping OAM feature which can be used to test a service between 7210 SAS nodes. The VCCV ping feature can test connectivity of a VLL with any third party node which is compliant to RFC 5085.
The following figure shows the VCCV-ping feature application.
Figure 17: VCCV-ping application

3.1.8.1.2. VCCV-ping in a multi-segment pseudowire
Pseudowire switching is a method for scaling a large network of VLL or VPLS services by removing the need for a full mesh of T-LDP sessions between the PE nodes as the number of these nodes grow over time. Pseudowire switching is also used whenever there is a need to deploy a VLL service across two separate routing domains.
In the network, a Termination PE (T-PE) is where the pseudowire originates and terminates.
VCCV ping is extended to be able to perform the following OAM functions:
- VCCV ping to a destination PE. A VLL FEC Ping is a message sent by T-PE1 to test the FEC at T-PE2. The operation at T-PE1 and T-PE2 is the same as in the case of a single-segment pseudowire. The pseudowire switching node, S-PE1, pops the outer label, swaps the inner (VC) label, decrements the TTL of the VC label, and pushes a new outer label. The 7210 SAS PE1 node does not process the VCCV OAM Control Word unless the VC label TTL expires. In that case, the message is sent to the CPM for further validation and processing. This is the method described in draft-hart-pwe3-segmented-pw-vccv.
3.1.8.2. Automated VCCV-trace capability for MS-pseudowire
Although tracing of the MS-pseudowire path is possible using the methods described in previous sections, these require multiple manual iterations and that the FEC of the last pseudowire segment to the target T-PE/S-PE be known a priori at the node originating the echo request message for each iteration. This mode of operation is referred to as a “ping” mode.
The automated VCCV-trace can trace the entire path of a pseudowire with a single command issued at the T-PE or at an S-PE. This is equivalent to LSP-trace and is an iterative process by which the ingress T-PE or T-PE sends successive VCCV-ping messages with incrementing the TTL value, starting from TTL=1.
The method is described in draft-hart-pwe3-segmented-pw-vccv, VCCV Extensions for Segmented Pseudo-Wire, and is pending acceptance by the PWE3 working group. In each iteration, the source T-PE or S-PE builds the MPLS echo request message in a way similar to VCCV ping. The first message with TTL=1 will have the next-hop S-PE T-LDP session source address in the Remote PE Address field in the pseudowire FEC TLV. Each S-PE which terminates and processes the message will include in the MPLS echo reply message the FEC 128 TLV corresponding the pseudowire segment to its downstream node.
The inclusion of the FEC TLV in the echo reply message is allowed in RFC 4379, Detecting Multi-Protocol Label Switched (MPLS) Data Plane Failures. The source T-PE or S-PE can then build the next echo reply message with TTL=2 to test the next-next hop for the MS-pseudowire. It will copy the FEC TLV it received in the echo reply message into the new echo request message. The process is terminated when the reply is from the egress T-PE or when a timeout occurs. If specified, the max-ttl parameter in the vccv-trace command will stop on SPE before reaching T-PE.
The results VCCV-trace can be displayed for a fewer number of pseudowire segments of the end-to-end MS-pseudowire path. In this case, the min-ttl and max-ttl parameters are configured accordingly. However, the T-PE/S-PE node will still probe all hops up to the min-ttl to correctly build the FEC of the desired subset of segments.
Note that this method does not require the use of the downstream mapping TLV in the echo request and echo reply messages.
3.1.8.2.1. VCCV for static pseudowire segments
MS pseudowire is supported with a mix of static and signaled pseudowire segments. However, VCCV ping and VCCV-trace is allowed until at least one segment of the MS pseudowire is static. Users cannot test a static segment but also, cannot test contiguous signaled segments of the MS-pseudowire. VCCV ping and VCCV trace is not supported in static-to-dynamic configurations.
3.1.8.2.2. Detailed VCCV-trace operation
A trace can be performed on the MS-pseudowire originating from T-PE1 by a single operational command. The following process occurs:
- T-PE1 sends a VCCV echo request with TTL set to 1 and a FEC 128 containing the pseudo-wire information of the first segment (pseudowire1 between T-PE1 and S-PE) to S-PE for validation.
- S-PE validates the echo request with the FEC 128. Since it is a switching point between the first and second segment it builds an echo reply with a return code of 8 and includes the FEC 128 of the second segment (pseudowire2 between S-PE and T-PE2) and sends the echo reply back to T-PE1.
- T-PE1 builds a second VCCV echo request based on the FEC128 in the echo reply from the S-PE. It increments the TTL and sends the next echo request out to T-PE2. Note that the VCCV echo request packet is switched at the S-PE datapath and forwarded to the next downstream segment without any involvement from the control plane.
- T-PE2 receives and validates the echo request with the FEC 128 of the pseudowire2 from T-PE1. Since T-PE2 is the destination node or the egress node of the MS-pseudowire it replies to T-PE1 with an echo reply with a return code of 3 (egress router) and no FEC 128 is included.
- T-PE1 receives the echo reply from T-PE2. T-PE1 is made aware that T-PE2 is the destination of the MS pseudowire because the echo reply does not contain the FEC 128 and because its return code is 3. The trace process is completed.
3.1.8.2.3. Control plane processing of a VCCV echo message in a MS-pseudowire
3.1.8.2.3.1. Sending a VCCV echo request
When in the ping mode of operation, the sender of the echo request message requires the FEC of the last segment to the target S-PE/T-PE node. This information can either be configured manually or be obtained by inspecting the corresponding sub-TLVs of the pseudowire switching point TLV. However, the pseudowire switching point TLV is optional and there is no guarantee that all S-PE nodes will populate it with their system address and the pseudowire-id of the last pseudowire segment traversed by the label mapping message. Therefore, the 7210 SAS implementation will always make use of the user configuration for these parameters.
3.1.8.2.3.2. Receiving an VCCV echo request
Upon receiving a VCCV echo request the control plane on S-PEs (or the target node of each segment of the MS pseudowire) validates the request and responds to the request with an echo reply consisting of the FEC 128 of the next downstream segment and a return code of 8 (label switched at stack-depth) indicating that it is an S-PE and not the egress router for the MS-pseudowire.
If the node is the T-PE or the egress node of the MS-pseudowire, it responds to the echo request with an echo reply with a return code of 3 (egress router) and no FEC 128 is included.
3.1.8.2.3.3. Receiving an VCCV echo reply
The operation to be taken by the node that receives the echo reply in response to its echo request depends on its current mode of operation such as ping or trace.
In ping mode, the node may choose to ignore the target FEC 128 in the echo reply and report only the return code to the operator.
3.1.9. MPLS-TP on-demand OAM commands
| Note: This feature is supported only on 7210 SAS-T (network operating mode), 7210 SAS-R6, and 7210 SAS-R12. |
Ping and Trace tools for PWs and LSPs are supported with both IP encapsulation and the MPLS-TP on demand CV channel for non-IP encapsulation (0x025).
3.1.9.1. MPLS-TP pseudowires: VCCV-ping/VCCV-trace
For vccv-ping and vccv-trace commands:
- Sub-type static must be specified. This indicates to the system that the rest of the command contains parameters that are applied to a static PW with a static PW FEC.
- Add the ability to specify the non-IP ACH channel type (0x0025). This is known as the non-ip control-channel. This is the default for type static. GAL is not supported for PWs.
- If the ip-control-channel is specified as the encapsulation, then the IPv4 channel type is used (0x0021). In this case, a destination IP address in the 127/8 range is used, while the source address in the UDP/IP packet is set to the system IP address, or may be explicitly configured by the user with the src-ip-address option. This option is only valid if the IPv4 control-channel is specified.
- The reply mode are always assumed to be the same application level control channel type for type static.
- Allow an MPLS-TP global ID and node ID specified under the spoke SDPs with a specific sdp-id:vc-id, used for MPLS-TP PW MEPs, or node ID (prefix) only for MIPs.
- The following CLI command description shows the options that are only allowed if the type static option is configured. All other options are blocked.
- As in the existing implementation, the downstream mapping and detailed downstream mapping TLVs (DSMAP/DDMAP TLVs) is not supported on PWs.vccv-ping static <sdp-id:vc-id> [dest-global-id <global-id> dest-node-id <node-id>] [control-channel ipv4 | non-ip] [fc <fc-name> [profile {in | out}]] [size <octets>] [count <send-count>] [timeout <timeout>] [interval <interval>] [ttl <vc-label-ttl>] [src-ip-address <ip-address>]vccv-trace static <sdp-id:vc-id> [size <octets>] [min-ttl <min-vc-label-ttl>] [max-ttl <max-vc-label-ttl>] [max-fail <no-response-count>] [probe-count <probe-count>] [control-channel ipv4 | non-ip] [timeout <timeout-value>] [interval <interval-value>] [fc <fc-name> [profile {in | out}]] [src-ip-address <ip-address>] [detail]
If the spoke SDP referred to by the sdp-id:vc-id has an MPLS-TP PW-Path-ID defined, then those parameters are used to populate the static PW TLV in the target FEC stack of the VCCV ping or VCCV trace packet. If a global ID and node ID are specified in the command, then these values are used to populate the destination node TLV in the VCCV ping or VCCV trace packet.
The global ID/node ID are only used as the target node identifiers if the vccv-ping is not end-to-end (for example, a TTL is specified in the VCCV ping/trace command and it is less than 255); otherwise, the value in the PW Path ID is used. For VCCV ping, the dest-node-id may be entered as a 4-octet IP address in the form a.b.c.d or as a 32-bit integer ranging from 1 to 4294967295. For VCCV trace, the destination node ID and global ID are taken from the spoke-sdp context.
The same command syntax is applicable for SAA tests configured under configure saa test a type.
3.1.9.2. MPLS-TP LSPs: LSP ping/LSP trace
For lsp-ping and lsp-trace commands:
- The sub-type static must be specified. This indicates to the system that the rest of the command contains parameters specific to a LSP identified by a static LSP FEC.
- The 7210 SAS supports the use of the G-ACh with non-IP encapsulation or labeled encapsulation with IP de-multiplexing for both the echo request and echo reply for LSP-Ping and LSP-Trace on LSPs with a static LSP FEC (such as MPLS-TP LSPs).
- It is possible to specify the target MPLS-TP MEP/MIP identifier information for LSP Ping. If the target global-id and node-id are not included in the lsp-ping command, then these parameters for the target MEP ID are taken from the context of the LSP. The tunnel-number tunnel-num and lsp-num lsp-num for the far-end MEP are always taken from the context of the path under test.lsp-ping static <lsp-name>[force][path-type [active | working | protect]][fc <fc-name> [profile {in | out}]][size <octets>][ttl <label-ttl>][send-count <send-count>][timeout <timeout>][interval <interval>][src-ip-address <ip-address>][dest-global-id <dest-global-id> dest-node-id <dest-node-id>][control-channel none | non-ip][detail]lsp-trace static <lsp-name>[force][path-type [active | working | protect][fc <fc-name> [profile {in | out}]][max-fail <no-response-count>][probe-count <probes-per-hop>][size <octets>][min-ttl <min-label-ttl>][max-ttl <max-label-ttl>][timeout <timeout>][interval <interval>][src-ip-address <ip-address>][control-channel none | non-ip][downstream-map-tlv <dsmap | ddmap>][detail]
The following commands are only valid if the sub-type static option is configured, implying that lsp-name refers to an MPLS-TP tunnel LSP:
path-type. Values: active, working, protect. Default: active.
dest-global-id global-id dest-node-id node-id: Default: the to global-id:node-id from the LSP ID.
control-channel: If this is set to none, then IP encapsulation over an LSP is used with a destination address in the 127/8 range. The source address is set to the system IP address, unless the user specifies a source address using the src-ip-address option. If this is set to non-ip, then non-IP encapsulation over a G-ACh with channel type 0x00025 is used. This is the default for sub-type static. Note that the encapsulation used for the echo reply is the same as the encapsulation used for the echo request.
downstream-map-tlv: LSP Trace commands with this option can only be executed if the control-channel is set to none. The DSMAP/DDMAP TLV is only included in the echo request message if the egress interface is either a numbered IP interface, or an unnumbered IP interface. The TLV will not be included if the egress interface is of type unnumbered-mpls-tp.
For lsp-ping, the dest-node-id may be entered as a 4-octet IP address in the form a.b.c.d or as a 32-bit integer ranging from 1 to 4294967295. For lsp-trace, the destination node ID and global ID are taken from the spoke-sdp context.
The send mode and reply mode are always taken to be an application level control channel for MPLS-TP.
The force parameter causes an LSP ping echo request to be sent on an LSP that has been brought oper-down by BFD (LSP-Ping echo requests would be dropped on oper-down LSPs). This parameter is not applicable to SAA.
The LSP ID used in the LSP Ping packet is derived from a context lookup based on lsp-name and path-type (active/working/protect).
Dest-global-id and dest-node-id refer to the target global/node id. They do not need to be entered for end-to-end ping and trace, and the system will use the destination global id and node id from the LSP ID.
The same command syntax is applicable for SAA tests configured under configure>saa>test.
3.1.10. MPLS-TP show commands
3.1.10.1. Static MPLS labels
The following new commands show the details of the static MPLS labels.
show>router>mpls-labels>label start-label [end-label [in-use | label-owner]]
show>router>mpls-labels>label-range
An example output is as follows:
3.1.10.2. MPLS-TP tunnel configuration
The following is a sample configuration output of a specific tunnel.
show>router>mpls>tp-lsp
3.1.10.3. MPLS-TP path configuration
This can reuse and augment the output of the current show commands for static LSPs. They should also show if BFD is enabled on a specific path. If this referring to a transit path, this should also display (among others) the path-id (7 parameters) for a specific transit-path-name, or the transit-path-name for a specific the path-id (7 parameters)
show>router>mpls>tp-lsp>path
A sample output is as follows:
3.1.10.4. MPLS-TP protection
These should show the protection configuration for a specific tunnel, which path in a tunnel is currently working and which is protect, and whether the working or protect is currently active.
show>router>mpls>tp-lsp>protection
A sample output is as follows:
3.1.10.5. BFD
The existing show>router>bfd context is enhanced for MPLS-TP, as follows:
show>router>bfd>mpls-tp-lsp
Displays the MPLS –TP paths for which BFD is enabled.
show>router>bfd>session [src ip-address [dest ip-address | detail]] | [mpls-tp-path lsp-id… [detail]]
Should be enhanced to show the details of the BFD session on a particular MPLS-TP path, where lsp-id is the fully qualified lSP ID to which the BFD session is in associated.
A sample output is as follows:
3.1.10.6. MPLS TP node configuration
Displays the Global ID, Node ID and other general MPLS-TP configurations for the node.
show>router>mpls>mpls-tp
A sample output is as follows:
3.1.10.7. MPLS-TP interfaces
The existing show>router>interface command should be enhanced to display MPLS-TP- specific information.
The following is a sample output:
3.1.10.8. Services using MPLS-TP PWs
The show>service command should be updated to display MPLS-TP-specific information such as the PW path ID and control channel status signaling parameters.
The following is a sample output:
3.1.11. MPLS-TP debug commands
The following command provides the debug command for an MPLS-TP tunnel:
tools>dump>router>mpls>tp-tunnel lsp-name [clear]
The following is a sample output:
The following command shows the free MPLS tunnel IDs.
The following command provides a debug tool to view control-channel-status signaling packets.
3.2. IP Performance Monitoring (IP PM)
The 7210 SAS supports Two-Way Active Measurement Protocol (TWAMP) and Two-Way Active Measurement Protocol Light (TWAMP Light).
| Note: On 7210 SAS-R6, 7210 SAS-R12, 7210 SAS-Mxp, and 7210 SAS-T, the MVR RVPLS service configured with IGMPv3 snooping shares resources with TWAMP and TWAMP Light. An increase in one decreases the amount of resources available for the other. Contact your Nokia representative for more information about scaling of these features. For more information about IGMPv3 snooping, refer to the 7210 SAS-Mxp, S, Sx, T Services Guide. |
3.2.1. Two-Way Active Measurement Protocol (TWAMP)
Two-Way Active Measurement Protocol (TWAMP) provides a standards-based method for measuring the round-trip IP performance (packet loss, delay and jitter) between two devices. TWAMP uses the methodology and architecture of One-Way Active Measurement Protocol (OWAMP) to define a way to measure two-way or round-trip metrics.
There are four logical entities in TWAMP:
- the control-client
- the session-sender
- the server
- the session-reflector
The control-client and session-sender are typically implemented in one physical device (the “client”) and the server and session-reflector in a second physical device (the “server”) with which the two-way measurements are being performed. The 7210 SAS acts as the server. The control-client and server establishes a TCP connection and exchange TWAMP-Control messages over this connection. When the control-client requires to start testing, the client communicates the test parameters to the server. If the server corresponds to conduct the described tests, the test begins as soon as the client sends a Start-Sessions message. As part of a test, the session sender sends a stream of UDP-based test packets to the session-reflector, and the session reflector responds to each received packet with a response UDP-based test packet. When the session-sender receives the response packets from the session-reflector, the information is used to calculate two-way delay, packet loss, and packet delay variation between the two devices.
3.2.1.1. Configuration notes
The following are the configuration notes:
- Unauthenticated mode is supported. Encrypted and Authenticated modes are not supported.
- TWAMP is supported only in the base router instance.
- By default, the 7210 SAS uses TCP port number 862 to listen for TWAMP control connections. This is not user configurable.
3.2.2. Two-Way Active Measurement Protocol Light (TWAMP Light)
TWAMP Light is an optional model included in the TWAMP standard RFC5357 that uses standard TWAMP test packets but provides a lightweight approach to gathering ongoing IP delay performance data for base router and per-VPRN statistics. Full details are described in Appendix I of RFC 5357 (Active Two Way Measurement Protocol). The 7210 SAS implementation supports the TWAMP Light model for gathering delay and loss statistics.
For TWAMP Light, the TWAMP Client/Server model is replaced with the Session Controller/Responder model. In general terms, the Session Controller is the launch point for the test packets and the Responder performs the reflection function.
TWAMP Light maintains the TWAMP test packet exchange but eliminates the TWAMP TCP control connection with local configurations; however, not all negotiated control parameters are replaced with local configuration. For example, CoS parameters communicated over the TWAMP control channel are replaced with a reply-in-kind approach. The reply-in-kind model reflects back the received CoS parameters, which are influenced by the reflector’s QoS policies.
The responder function is configured under the config>router>twamp-light command hierarchy for base router reflection, and under the config>service>vprn>twamp-light command hierarchy for per VPRN reflection. The TWAMP Light reflector function is configured per context and must be activated before reflection can occur; the function is not enabled by default for any context. The reflector requires the operator to define the TWAMP Light UDP listening port that identifies the TWAMP Light protocol and the prefixes that the reflector will accept as valid sources for a TWAMP Light request. If the configured TWAMP Light listening UDP port is in use by another application on the system, a Minor OAM message will be presented indicating that the port is unavailable and that the activation of the reflector is not allowed.
f the source IP address in the TWAMP Light packet arriving on the responder does not match a configured IP address prefix, the packet is dropped. Multiple prefix entries may be configured per context on the responder. An inactivity timeout under the config>oam-test>twamp>twamp-light hierarchy defines the amount of time the reflector will keep the individual reflector sessions active in the absence of test packets. A responder requires CPM3 or better hardware.
TWAMP Light test packet launching is controlled by the OAM Performance Monitoring (OAM-PM) architecture and adheres to those rules; this includes the assignment of a test Id. TWAMP Light does not carry the 4-byte test ID in the packet to remain locally significant and uniform with other protocols under the control of the OAM-PM architecture. The OAM-PM construct allow the various test parameters to be defined. These test parameters include the IP session-specific information which allocates the test to the specific routing instance, the source and destination IP address, the destination UDP port (which must match the listening UDP port on the reflector) and a number of other options that allow the operator to influence the packet handling. The probe interval and padding size can be configured under the specific session. The size of the all “0” padding can be included to ensure that the TWAMP packet is the same size in both directions. The TWAMP PDU definition does not accomplish symmetry by default. A pad size of 27 bytes will accomplish symmetrical TWAMP frame sizing in each direction.
The OAM-PM architecture does not perform any validation of the session information. The test will be allowed to be activated regardless of the validity of this information. For example, if the configured source IP address is not local within the router instance to which the test is allocated, the test will start sending TWAMP Light packets but will not receive any responses.
The OAM Performance Monitoring (OAM-PM) section of this guide provides more information describing the integration of TWAMP Light and the OAM-PM architecture, including hardware dependencies.
The following is a summary of supported TWAMP Light functions.
- base router instances for network interfaces and IES services:
- IPv6 addresses are supported only with IP interfaces that support IPv6, such as an IES IP interface in access-uplink and network mode. IPv6 is not supported for IP interfaces that do not support IPv6; for example, routed VPLS services in access-uplink mode do not support IPv6, and therefore TWAMP Light IPv6 sessions are not supported with it.
- per-VPRN service context
- IPv4 and IPv6:
- must be unicast
- for IPv6, addresses cannot be a reserved or link local address
- reflector prefix definition for acceptable TWAMP Light sources:
- Prefix list may be added and removed without shutting down the reflector function.
- If no prefixes are defined, the reflector will drop all TWAMP Light packets.
- integration with OAM-PM architecture capturing delay and loss measurement statistics:
- Not available from interactive CLI.
- Multiple test sessions can be configured between the same source and destination IP endpoints. The tuple of Source IP, Destination IP, Source UDP, and Destination UDP provide a unique index for each test.
The following example shows a basic configuration using TWAMP Light to monitor two IP endpoints in a VPRN, including the default TWAMP Light values that were not overridden with configuration entries.
The following is a sample reflector configuration output.
The following is a sample session controller configuration output.
3.3. Ethernet Connectivity Fault Management
The IEEE and the ITU-T have cooperated to define the protocols, procedures and managed objects to support service-based fault management. Both IEEE 802.1ag standard (Ethernet Connectivity Fault Management (ETH-CFM)) and the ITU-T Y.1731 recommendation support a common set of tools that allow operators to deploy the necessary administrative constructs, management entities and functionality. The ITU-T has also implemented a set of advanced ETH-CFM and performance management functions and features that build on the proactive and on-demand troubleshooting tools.
CFM uses Ethernet frames and is distinguishable by ether-type 0x8902. In certain cases, the different functions use a reserved multicast address that can also be used to identify specific functions at the MAC layer. However, the multicast MAC addressing is not used for every function or in every case. The Operational Code (OpCode) in the common CFM header is used to identify the type of function carried in the CFM packet. CFM frames are only processed by IEEE MAC bridges. With CFM, interoperability can be achieved between different vendor equipment in the service provider network up to and including customer premise bridges.
IEEE 802.1ag and ITU-T Y.1731 functions that are implemented are available on the 7210 SAS platforms.
The following table lists the CFM-related acronyms used in this section.
Table 11: ETH-CFM acronym expansions
Acronym | Expansion |
1DM | One way Delay Measurement (Y.1731) |
AIS | Alarm Indication Signal |
CCM | Continuity check message |
CFM | Connectivity fault management |
DMM | Delay Measurement Message (Y.1731) |
DMR | Delay Measurement Reply (Y.1731) |
LBM | Loopback message |
LBR | Loopback reply |
LTM | Linktrace message |
LTR | Linktrace reply |
ME | Maintenance entity |
MA | Maintenance association |
MA-ID | Maintenance association identifier |
MD | Maintenance domain |
MEP | Maintenance association end point |
MEP-ID | Maintenance association end point identifier |
MHF | MIP half function |
MIP | Maintenance domain intermediate point |
OpCode | Operational Code |
RDI | Remote Defect Indication |
TST | Ethernet Test (Y.1731) |
3.3.1. ETH-CFM building blocks
The IEEE and the ITU-T use their own nomenclature when describing administrative contexts and functions. This introduces a level of complexity to configuration, description and different vendors naming conventions. The 7210 SAS OS CLI has chosen to standardize on the IEEE 802.1ag naming where overlap exists. ITU-T naming is used when no equivalent is available in the IEEE standard. In the following definitions, both the IEEE name and ITU-T names are provided for completeness, using the format IEEE Name/ITU-T Name.
Maintenance Domain (MD)/Maintenance Entity (ME) is the administrative container that defines the scope, reach and boundary for faults. It is typically the area of ownership and management responsibility. The IEEE allows for various formats to name the domain, allowing up to 45 characters, depending on the format selected. ITU-T supports only a format of none and does not accept the IEEE naming conventions:
- 0Undefined and reserved by the IEEE.
- 1No domain name. It is the only format supported by Y.1731 as the ITU-T specification does not use the domain name. This is supported in the IEEE 802.1ag standard but not in currently implemented for 802.1ag defined contexts.
- 2,3,4Provides the ability to input various different textual formats, up to 45 characters. The string format (2) is the default and therefore the keyword is not shown when looking at the configuration.
Maintenance Association (MA)/Maintenance Entity Group (MEG) is the construct where the different management entities will be contained. Each MA is uniquely identified by its MA-ID. The MA-ID is comprised of the by the MD level and MA name and associated format. This is another administrative context where the linkage is made between the domain and the service using the bridging-identifier configuration option. The IEEE and the ITU-T use their own specific formats. The MA short name formats (0-255) have been divided between the IEEE (0-31, 64-255) and the ITU-T (32-63), with five currently defined (1-4, 32). Even though the different standards bodies do not have specific support for the others formats a Y.1731 context can be configured using the following IEEE format options:
- 1 (Primary VID) - values 0 to 4094
- 2 (String) - raw ASCII, excluding 0-31 decimal/0-1F hex (which are control characters) form the ASCII table
- 3 (2-octet integer) - 0 to 65535
- 4 (VPN ID) - hex value as described in RFC 2685, Virtual Private Networks Identifier
- 32 (icc-format) - exactly 13 characters from the ITU-T recommendation T.50
| Note: When a VID is used as the short MA name, 802.1ag will not support VLAN translation because the MA-ID must match all the MEPs. The default format for a short MA name is an integer. Integer value 0 means the MA is not attached to a VID. This is useful for VPLS services on 7210 SAS platforms because the VID is locally significant. |
Maintenance Domain Level (MD Level)/Maintenance Entity Group Level (MEG Level) is the numerical value (0-7) representing the width of the domain. The wider the domain, higher the numerical value, the farther the ETH-CFM packets can travel. It is important to understand that the level establishes the processing boundary for the packets. Strict rules control the flow of ETH-CFM packets and are used to ensure correct handling, forwarding, processing and dropping of these packets. To keep it simple ETH-CFM packets with higher numerical level values will flow through MEPs on MIPs on SAPs configured with lower level values. This allows the operator to implement different areas of responsibility and nest domains within each other. Maintenance association (MA) includes a set of MEPs, each configured with the same MA-ID and MD level used verify the integrity of a single service instance.
Maintenance Endpoint (MEP)/MEG Endpoint (MEP) are the workhorses of ETH-CFM. A MEP is the unique identification within the association (0-8191). Each MEP is uniquely identified by the MA-ID, MEPID tuple. This management entity is responsible for initiating, processing and terminating ETH-CFM functions, following the nesting rules. MEPs form the boundaries which prevent the ETH-CFM packets from flowing beyond the specific scope of responsibility. A MEP has direction, up or down. Each indicates the directions packets will be generated; UP toward the switch fabric, down toward the SAP away from the fabric. Each MEP has an active and passive side. Packets that enter the active point of the MEP will be compared to the existing level and processed accordingly. Packets that enter the passive side of the MEP are passed transparently through the MEP. Each MEP contained within the same maintenance association and with the same level (MA-ID) represents points within a single service. MEP creation on a SAP is allowed only for Ethernet ports with NULL, Q-tags, Q-in-Q encapsulations. MEPs may also be created on SDP bindings.
Maintenance Intermediate Point (MIP)/MEG Intermediate Point (MIP) are management entities between the terminating MEPs along the service path. These provide insight into the service path connecting the MEPs. MIPs only respond to Loopback Messages (LBM) and Linktrace Messages (LTM). All other CFM functions are transparent to these entities. Only one MIP is allowed per SAP or SDP. The creation of the MIPs can be done when the lower level domain is created (explicit). This is controlled by the use of the mhf-creation mode within the association under the bridge-identifier. MIP creation is supported on a SAP and SDP, not including Mesh SDP bindings. By default, no MIPs are created.
There are two locations in the configuration where ETH-CFM is defined. The domains, associations (including linkage to the service id), MIP creation method, common ETH-CFM functions and remote MEPs are defined under the top level eth-cfm command. It is important to note, when Y.1731 functions are required the context under which the MEPs are configured must follow the Y.1731 specific formats (domain format of none, MA format icc-format). When these parameters have been entered, the MEP and possibly the MIP can be defined within the service under the SAP or SDP.
Table 12, Table 13, Table 14, Table 15, Table 16, and Table 17 are general tables that indicates the ETH-CFM support for the different services and endpoints. It is not meant to indicate the services that are supported or the requirements for those services on the individual platforms.
Table 12: ETH-CFM support matrix for the 7210 SAS-T (network mode)
Service | Ethernet connection type | MEP | MIP | Primary VLAN | ||
Down MEP | Up MEP | Ingress MIP | Egress MIP | |||
Epipe | SAP | ✓ | ✓ | ✓ | ✓ | ✓ 1 |
SDP | ✓ | ✓ | ✓ | ✓ | ||
VPLS | SAP | ✓ | ✓ | ✓ | ✓ 1 | |
Spoke-SDP | ✓ | ✓ | ✓ | |||
Mesh-SDP | ✓ | ✓ | ||||
RVPLS | SAP | |||||
IES | IES IPv4 interface | |||||
PBB Epipe | I-SAP | ✓ | ||||
PBB VPLS | I-SAP | |||||
PBB B-VPLS | B-SAP | |||||
IES | SAP | |||||
VPRN | SAP | |||||
- Only on Down MEP
Note:
Table 13: ETH-CFM support matrix for the 7210 SAS-T (access-uplink mode)
Service | Ethernet connection type | MEP | MIP | Primary VLAN | ||
Down MEP | Up MEP | Ingress MIP | Egress MIP | |||
Epipe | SAP (Access and Access-uplink SAP) | ✓ | ✓ | ✓ | ✓ | |
VPLS | SAP (Access and Access-uplink SAP) | ✓ | ✓ | ✓ | ||
RVPLS | SAP | |||||
IES | IES IPv4 interface | |||||
SAP | ||||||
Table 14: ETH-CFM support matrix for 7210 SAS-Mxp Devices
Service | Ethernet connection type | MEP | MIP | Primary VLAN | ||
Down MEP | Up MEP | Ingress MIP | Egress MIP | |||
Epipe | SAP | ✓ | ✓ | ✓ | ✓ | ✓ 1 |
SDP | ✓ | ✓ | ✓ | ✓ | ||
VPLS | SAP | ✓ | ✓ | ✓ | ✓ 1 | |
Spoke-SDP | ✓ | ✓ | ✓ |
| ||
Mesh-SDP | ✓ | ✓ | ||||
RVPLS | SAP | |||||
IES | IES IPv4 interface | |||||
PBB Epipe | I-SAP | |||||
PBB VPLS | I-SAP | |||||
PBB B-VPLS | B-SAP | |||||
IES | SAP | |||||
VPRN | SAP | |||||
- Only on Down MEP
Note:
Table 15: ETH-CFM support matrix for 7210 SAS-R6 and 7210 SAS-R12 devices
Service | Ethernet connection type | MEP | MIP | Primary VLAN | ||
Down MEP | Up MEP | Ingress MIP | Egress MIP | |||
Epipe | SAP | ✓ | ✓ | ✓ | ✓ | ✓ 1 |
SDP | ✓ | ✓ | ✓ | ✓ | ||
VPLS | SAP | ✓ | ✓ 2 | ✓ | ✓ | ✓ 3 |
Spoke-SDP | ✓ | ✓ 2 | ✓ | |||
Mesh-SDP | ✓ 2 | |||||
R-VPLS | SAP | |||||
IES | IES IPv4 interface | |||||
PBB Epipe | I-SAP | |||||
PBB VPLS | I-SAP | |||||
PBB B-VPLS | B-SAP | |||||
IES | SAP | |||||
VPRN | SAP | |||||
- Supported for Down MEP only.
- Supported for IMMv2 only.
- Supported only for Down MEP and MIP.
Notes:
Table 16: ETH-CFM support matrix for 7210 SAS-Sx/S 1/10GE devices
Service | Ethernet connection type | MEP
| MIP | Primary VLAN | ||
Down MEP | Up MEP | Ingress MIP | Egress MIP | |||
Epipe | SAP | ✓ | ✓ | ✓ | ✓ | ✓ 1 |
SDP | ✓ | ✓ | ✓ | ✓ | ||
VPLS | SAP | ✓ | ✓ | ✓ | ✓ 1 | |
Spoke-SDP | ✓ | ✓ | ✓ | |||
Mesh-SDP | ✓ | ✓ | ||||
RVPLS | SAP | |||||
IES | IES IPv4 interface | |||||
PBB Epipe | I-SAP | |||||
PBB VPLS | I-SAP | |||||
PBB B-VPLS | B-SAP | |||||
IES | SAP | |||||
VPRN | SAP | |||||
- Only on Down MEP
Note:
Table 17: ETH-CFM support matrix for 7210 SAS-Sx 10/100GE devices
Service | Ethernet connection type | MEP | MIP | Primary VLAN | ||
Down MEP | Up MEP | Ingress MIP | Egress MIP | |||
Epipe | SAP | ✓ | ✓ | ✓ | ✓ | ✓ 1 |
SDP | ✓ | ✓ | ✓ | ✓ | ||
VPLS | SAP | ✓ | ✓ | ✓ | ✓ 1 | |
Spoke-SDP | ✓ | ✓ | ✓ | |||
Mesh-SDP | ✓ | ✓ | ||||
RVPLS | SAP | |||||
IES | IES IPv4 interface | |||||
PBB Epipe | I-SAP | |||||
PBB VPLS | I-SAP | |||||
PBB B-VPLS | B-SAP | |||||
IES | SAP | |||||
VPRN | SAP | |||||
- Only on Down MEP
Note:
The following figures show the detailed IEEE representation of MEPs, MIPs, levels and associations, using the standards defined icons.
Figure 18: MEP and MIP
Figure 19: MEP, MIP and MD levels
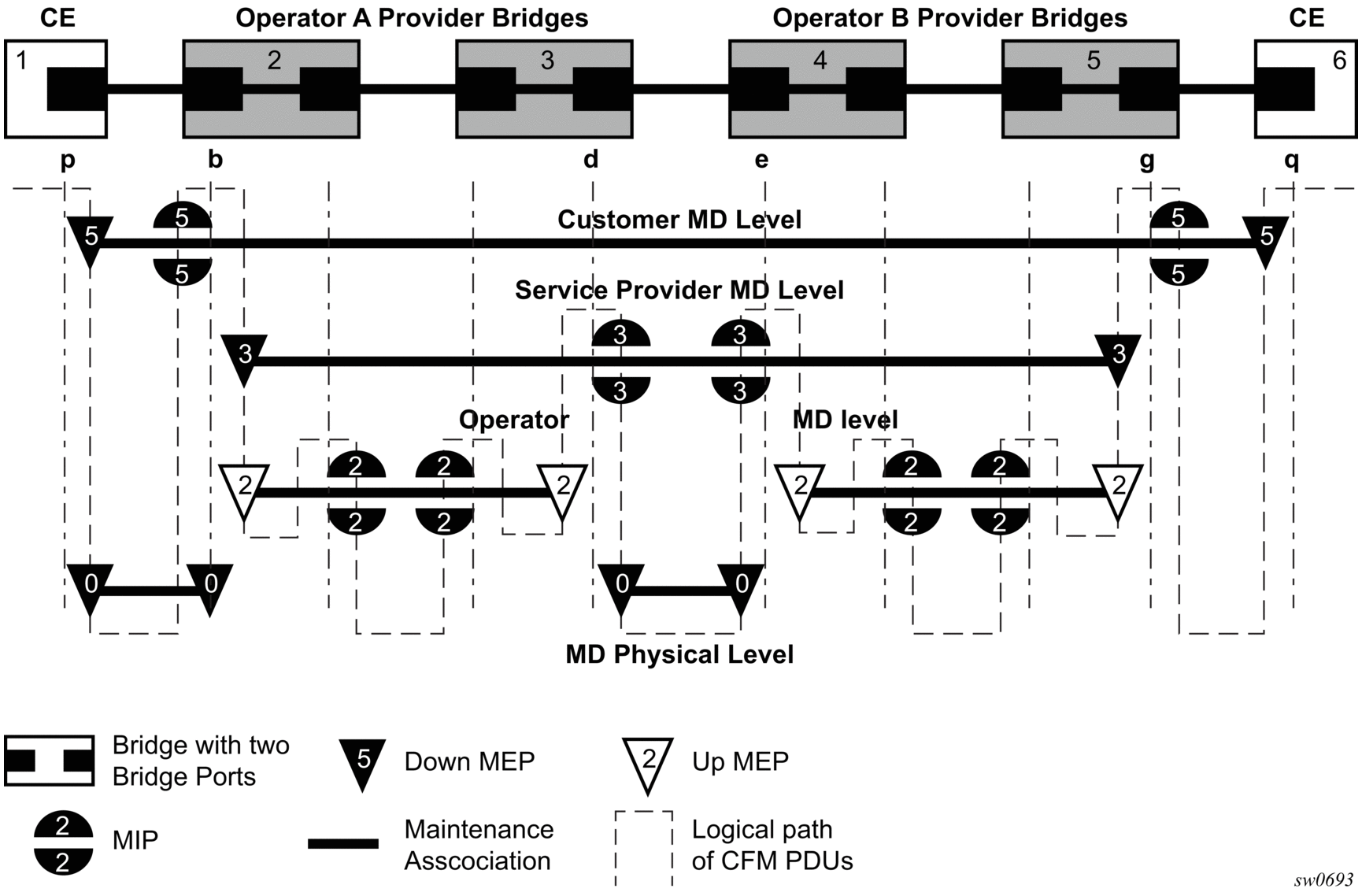
3.3.1.1. Loopback
A loopback message is generated by a MEP to its peer MEP (see the following figure). The functions are similar to an IP ping to verify Ethernet connectivity between the nodes.
Figure 20: CFM loopback
The following loopback-related functions are supported:
- Loopback message functionality on a MEP or MIP can be enabled or disabled.
- A MEP supports generating loopback messages and responding to loopback messages with loopback reply messages.
- A MIP supports responding to loopback messages with loopback reply messages when loopback messages are targeted to itself.
- The Sender ID TLV may optionally be configured to carry the Chassis ID. When configured, the following information will be included in LBM messages:
- Only the Chassis ID portion of the TLV will be included.
- The Management Domain and Management Address fields are not supported on transmission.
- As per the specification, the LBR function copies and returns any TLVs received in the LBM message. This means that the LBR message will include the original Sender ID TLV.
- The Sender ID TLV is supported for service (id-permission) MEPs.
- The Sender ID TLV is supported for both MEPs and MIPs.
- Loopback test results are displayed on the originating MEP. There is a limit of 10 outstanding tests per node.
3.3.1.2. Linktrace
A linktrace message is originated by an MEP and targeted to a peer MEP in the same MA and within the same MD level (see Figure 21). Its function is similar to IP traceroute. Linktrace traces a specific MAC address through the service. The peer MEP responds with a linktrace reply message after successful inspection of the linktrace message. The MIPs along the path also process the linktrace message and respond with linktrace replies to the originating MEP if the received linktrace message that has a TTL greater than 1; the MIPs also forward the linktrace message if a lookup of the target MAC address in the Layer 2 FIB is successful. The originating MEP will receive multiple linktrace replies and from processing the linktrace replies, it can put together the route to the target bridge.
A traced MAC address (the targeted MAC address) is carried in the payload of the linktrace message. Each MIP and MEP receiving the linktrace message checks whether it has learned the target MAC address. To use linktrace, the target MAC address must have been learned by the nodes in the network. If the address has been learned, a linktrace message is sent back to the originating MEP. A MIP forwards the linktrace message out of the port where the target MAC address was learned.
The linktrace message has a multicast destination address. On a broadcast LAN, it can be received by multiple nodes connected to that LAN; However, only one node will send a reply.
Figure 21: CFM linktrace
The following linktrace-related functions are supported:
- Linktrace functions can be enabled or disabled on an MEP.
- A MEP supports generating linktrace messages and responding with linktrace reply messages.
- A MIP supports responding to linktrace messages with linktrace reply messages when encoded TTL is greater than 1; The MIPs forward the linktrace messages accordingly if a lookup of the target MAC address in the Layer 2 FIB is successful.
- The Sender ID TLV may optionally be configured to carry the Chassis ID. When configured, the following information will be included in LTM and LTR messages:
- Only the Chassis ID portion of the TLV will be included.
- The Management Domain and Management Address fields are not supported on transmission.
- The LBM message will include the Sender ID TLV that is configured on the launch point. The LBR message will include the Sender ID TLV information from the reflector (MIP or MEP) if it is supported.
- The Sender ID TLV is supported for service (id-permission) MEPs.
- The Sender ID TLV is supported for both MEPs and MIPs.
The display output has been updated to include the Sender ID TLV contents if they are included in the LBR.
- Linktrace test results are displayed on the originating MEP. There is a limit of 10 outstanding tests per node. Storage is provided for up to 10 MEPs and for the last 10 responses. If more than 10 responses are received older entries will be overwritten.
3.3.1.3. Continuity Check (CC)
A Continuity Check Message (CCM) is a multicast frame that is generated by a MEP and multicast to all other MEPs in the same MA. The CCM does not require a reply message. To identify faults, the receiving MEP maintains an internal list of remote MEPs it should be receiving CCM messages from.
This list is based on the remote MEP ID configuration within the association the MEP is created in. When the local MEP does not receive a CCM from one of the configured remote MEPs within a preconfigured period, the local MEP raises an alarm.
The following figure shows a CFM continuity check.
Figure 22: CFM Continuity Check
The following figure shows a CFM CC failure scenario.
Figure 23: CFM CC failure scenario

The following functions are supported:
- CC can be enabled and disabled for an MEP.
- MEP entries can be configured and deleted in the CC MEP monitoring database manually. Only remote MEPs must be configured. Local MEPs are automatically added to the database when they are created.
- The CCM transmit interval is configurable. See the Diagnostics command reference for more information about supported timer intervals on different platforms for MEPs used in the service context and G.8032 control instance context.
- CCM will declare a fault, when:
- the CCM stops hearing from one of the remote MEPs for 3.5 times CC interval
- the CCM hears from a MEP with a LOWER MD level
- the CCM hears from a MEP that is not part of the local MEP’s MA
- the CCM hears from a MEP that is in the same MA but not in the configured MEP list
- the CCM hears from a MEP that is in the same MA with the same MEP ID as the receiving MEP
- the CC interval of the remote MEP does not match the local configured CC interval
- the remote MEP is declaring a fault
- An alarm is raised and a trap is sent if the defect is greater than or equal to the configured low-priority-defect value.
- Remote Defect Indication (RDI) is supported but by default is not recognized as a defect condition because the low-priority-defect setting default does not include RDI.
- The Sender ID TLV may optionally be configured to carry the Chassis ID. When configured, the following information will be included in CCM messages:
- Only the Chassis ID portion of the TLV will be included.
- The Management Domain and Management Address fields are not supported on transmission.
- The Sender ID TLV is not supported with subsecond CCM-enabled MEPs.
- The Sender ID TLV is supported for service (id-permission) MEPs.
3.3.1.4. Alarm Indication Signal (ETH-AIS Y.1731)
Alarm Indication Signal (AIS) provides an Y.1731 capable MEP the ability to signal a fault condition in the reverse direction of the MEP, out the passive side. When a fault condition is detected the MEP will generate AIS packets at the configured client levels and at the specified AIS interval until the condition is cleared. Currently a MEP configured to generate AIS must do so at a level higher than its own. The MEP configured on the service receiving the AIS packets is required to have the active side facing the receipt of the AIS packet and must be at the same level the AIS, The absence of an AIS packet for 3.5 times the AIS interval set by the sending node will clear the condition on the receiving MEP.
It is important to note that AIS generation is not supported to an explicitly configured endpoint. An explicitly configured endpoint is an object that contains multiple individual endpoints, as in PW redundancy.
3.3.1.5. Test (ETH-TST Y.1731)
Ethernet test affords operators an Y.1731 capable MEP the ability to send an in service on demand function to test connectivity between two MEPs. The test is generated on the local MEP and the results are verified on the destination MEP. Any ETH-TST packet generated that exceeds the MTU will be silently dropped by the lower level processing of the node.
3.3.2. Y.1731 time stamp capability
Accurate results for one-way and two-way delay measurement tests using Y.1731 messages are obtained if the nodes are capable of time stamping packets in hardware:
- 7210 SAS-Sx 10/100GE support is as follows:
- Y.1731 2-DM messages for both Down MEPs and UP MEPs, 1-DM for both Down MEPs and UP MEPs, and 2-SLM for both Down MEPs and UP MEPs use software-based timestamps on Tx and hardware based timestamp on Rx. It uses the system clock (free-running or synchronized to NTP) to obtain the timestamps.
- 7210 SAS-T (network mode), 7210 SAS-Sx 1/10GE, 7210 SAS-Mxp, 7210 SAS-R6 and 7210 SAS-R12 support is as follows:
- Y.1731 2-DM messages for both Down MEPs and UP MEPs, 1-DM for both Down MEPs and UP MEPs, and 2-SLM for both Down MEPs and UP MEPs use software-based timestamps on transmission and hardware-based timestamps on receipt. The timestamps are obtained as follows:
- from NTP, when NTP is enabled and PTP is disabled
- from PTP, when PTP is enabled (irrespective of whether NTP is disabled or enabled)
- from PTP, when PTP is enabled and NTP is configured to use PTP for system time
- from free-running system time, when both NTP and PTP are disabled.
- The 7210 SAS-T (access-uplink mode) support is as follows:
- Y.1731 2-DM messages for Down MEPs uses hardware timestamps for both Rx (packets received by the node) and Tx (packets sent out of the node). The timestamps is obtained from a free-running hardware clock. It provides accurate 2-way delay measurements and it is not recommended to use it for computing 1-way delay.
- Y.1731 2-DM messages for UP MEPs, 1-DM for both Down MEPs and UP MEPs, and 2-SLM for both Down MEPs and UP MEPs use software based timestamps on Tx and hardware based timestamp on Rx. The timestamps are obtained as follows:
- from NTP, when NTP is enabled and PTP is disabled
- from PTP, when PTP is enabled (irrespective of whether NTP is disabled or enabled)
- from PTP, when PTP is enabled and NTP is configured to use PTP for system time
- from free-running system time, when both NTP and PTP are disabled.
| Note: On 7210 SAS-T, 7210 SAS-Mxp, 7210 SAS-R6, 7210 SAS-R12 after PTP is enabled once, if the user needs to go back to NTP time scale, or system free-run time scale, a node reboot is required. |
3.3.3. ITU-T Y.1731 Ethernet Bandwidth Notification
| Note: This feature is only supported on the 7210 SAS-Mxp, 7210 SAS-R6, and 7210 SAS-R12. |
The Ethernet Bandwidth Notification (ETH-BN) function is used by a server MEP to signal link bandwidth changes to a client MEP.
This functionality is for point-to-point microwave radios. When a microwave radio uses adaptive modulation, the capacity of the radio can change based on the condition of the microwave link. For example, in adverse weather conditions that cause link degradation, the radio can change its modulation scheme to a more robust one (which will reduce the link bandwidth) to continue transmitting.
This change in bandwidth is communicated from the server MEP on the radio, using an Ethernet Bandwidth Notification Message (ETH-BNM), to the client MEP on the connected router. The server MEP transmits periodic frames with ETH-BN information, including the interval, the nominal and currently available bandwidth. A port MEP with the ETH-BN feature enabled will process the information contained in the CFM PDU and appropriately adjust the rate of traffic sent to the radio.
A port MEP that is not a LAG member port supports the client side reception and processing of the ETH-BN CFM PDU sent by the server MEP. By default, processing is disabled. The config port ethernet eth-cfm mep eth-bn receive CLI command sets the ETH-BN processing state on the port MEP. A port MEP supports untagged packet processing of ETH-CFM PDUs at domain levels 0 and 1 only. The port client MEP sends the ETH-BN rate information received to be applied to the port egress rate in a QoS update. A pacing mechanism limits the number of QoS updates sent. The config port ethernet eth-cfm mep eth-bn rx-update-pacing CLI command allows the updates to be paced using a configurable range of 1 to 600 seconds (the default is 5 seconds). The pacing timer begins to count down following the most recent QoS update sent to the system for processing. When the timer expires, the most recent update that arrived from the server MEP is compared to the most recent value sent for system processing. If the value of the current bandwidth is different from the previously processed value, the update is sent and the process begins again. Updates with a different current bandwidth that arrive when the pacing timer has already expired are not subject to a timer delay. Refer to the 7210 SAS-Mxp, R6, R12, S, Sx, T Interface Configuration Guide for more information about these CLI commands.
A complimentary QoS configuration is required to allow the system to process current bandwidth updates from the CFM engine. The config port ethernet eth-bn-egress-rate-changes CLI command is required to enable the QoS function to update the port egress rates based on the current available bandwidth updates from the CFM engine. By default, the function is disabled.
Both the CFM and QoS functions must be enabled for the changes in current bandwidth to dynamically update the egress rate.
When the MEP enters a state that prevents it from receiving the ETH-BNM, the current bandwidth last sent for processing is cleared and the egress rate reverts to the configured rate. Under these conditions, the last update cannot be guaranteed as current. Explicit notification is required to dynamically update the port egress rate. The following types of conditions lead to ambiguity:
- administrative MEP shut down
- port admin down
- port link down
- eth-bn no receive transitioning the ETH-BN function to disable
If the eth-bn-egress-rate-changes command is disabled using the no option, CFM continues to send updates, but the updates are held without affecting the port egress rate.
The ports supporting ETH-BN MEPs can be configured for the network, access, hybrid, and access-uplink modes. When ETH-BN is enabled on a port MEP and the config>port>ethernet>eth-cfm>mep>eth-bn>receive and the QoS config>port>ethernet>eth-bn-egress-rate-changes contexts are configured, the egress rate is dynamically changed based on the current available bandwidth indicated by the ETH-BN server.
| Note: For SAPs configured on an access port or hybrid port, changes in port bandwidth on reception of ETH-BNM messages will result in changes to the port egress rate, but the SAP egress aggregate shaper rate and queue egress shaper rate provisioned by the user are unchanged, which may result in an oversubscription of the committed bandwidth. Consequently, Nokia recommends that the user should change the SAP egress aggregate shaper rate and queue egress shaper rate for all SAPs configured on the port from an external management station after egress rate changes are detected on the port. |
The port egress rate is capped by the minimum of the configured egress-rate, and the maximum port rate. The minimum egress rate using ETH-BN is 1024 kb/s. If a current bandwidth of zero is received, it does not affect the egress port rate and the previously processed current bandwidth will continue to be used.
The client MEP requires explicit notification of changes to update the port egress rate. The system does not timeout any previously processed current bandwidth rates using a timeout condition. The specification does allow a timeout of the current bandwidth if a frame has not been received in 3.5 times the ETH-BNM interval. However, the implicit approach can lead to misrepresented conditions and has not been implemented.
When you start or restart the system, the configured egress rate is used until an ETH-BNM arrives on the port with a new bandwidth request from the ETH-BN server MEP.
An event log is generated each time the egress rate is changed based on reception of a BNM. If a BNM is received that does not result in a bandwidth change, no event log is generated.
The destination MAC address can be a Class 1 multicast MAC address (that is, 01-80-C2-00-0x) or the MAC address of the port MEP configured. Standard CFM validation and identification must be successful to process CFM PDUs.
For information on the eth-bn-egress-rate-changes command, refer to the 7210 SAS-Mxp, R6, R12, S, Sx, T Interface Configuration Guide.
The Bandwidth Notification Message (BNM) PDU used for ETH-BN information is a sub-OpCode within the Ethernet Generic Notification Message (ETH-GNM).
The following table shows the BNM PDU format fields.
Table 18: BNM PDU format fields
Label | Description |
MEG Level | Carries the MEG level of the client MEP (0 to 7). This field must be set to either 0 or 1 to be recognized as a port MEP. |
Version | The current version is 0 |
OpCode | The value for this PDU type is GNM (32) |
Flags | Contains one information element: Period (3 bits), which indicates how often ETH-BN messages are transmitted by the server MEP. The following are the valid values:
|
TLV Offset | This value is set to 13 |
Sub-OpCode | The value for this PDU type is BNM (1) |
Nominal Bandwidth | The nominal full bandwidth of the link, in Mb/s. This information is reported in the display but not used to influence QoS egress rates. |
Current Bandwidth | The current bandwidth of the link in Mb/s. The value is used to influence the egress rate. |
Port ID | A non-zero unique identifier for the port associated with the ETH-BN information, or zero if not used. This information is reported in the display, but is not used to influence QoS egress rates. |
End TLV | An all zeros octet value On the 7210 SAS, port-level MEPs with level 0 or 1 should be implemented to support this application. A port-level MEP must support CCM, LBM, LTM, RDI, and ETH-BN, but can be used for ETH-BN only. |
The show eth-cfm mep eth-bandwidth-notification display output includes the ETH-BN values received and extracted from the PDU, including a last reported value and the pacing timer. If the n/a value appears in the field, it indicates that field has not been processed.
The base show eth-cfm mep output is expanded to include the disposition of the ETH-BN receive function and the configured pacing timer.
The show port port-id detail is expanded to include an Ethernet Bandwidth Notification Message Information section. This section includes the ETH-BN Egress Rate disposition and the current Egress BN rate being used.
3.3.3.1. ETH-BN configuration guidelines
The following guidelines apply to the ETH-BN configuration:
- In a committed information rate (CIR) loop, scheduling is packet-based round robin with weight 1. This scheduling applies to SAP and port queues, and between SAP aggregates and network aggregates when the node is operating in the SAP scheduler mode. Refer to the 7210 SAS-Mxp, R6, R12, S, Sx, T Quality of Service Guide for more information about schedulers.
- When the node is operating in the port-scheduler-mode, the access egress QoS policy is attached to the access port. Users can configure queue rates for the access egress QoS policy using either the rate or percent-rate command. The percent-rate command configures queue rates as a percentage of the port shaper rate that is currently in effect.When using the ETH-BN feature, Nokia recommends using the percent-rate command to configure queue rates in the access egress QoS policy so that the system can update queue rates based on the ETH-BN port egress rate changes and oversubscription of the port scheduler is avoided.
- To implement port-level policy attachment changes or queue mode changes for access egress or network queue policies, Nokia recommends shutting down the ports to which the policy is attached and waiting until the queues clear before modifying the QoS policy.
- When modifying the queue mode on a queue for a SAP egress QoS policy that is already attached to SAPs, or when modifying a SAP egress QoS policy attached to any SAP, Nokia recommends shutting down the SAPs that the policy is attached to and waiting until the queues clear before modifying the QoS policy. Use the show pools access-egress and network-egress commands to check for zero queue depth.
- Egress rate changes due to ETH-BN may lead to CIR oversubscription, which is not supported on the 7210 SAS-Mxp, 7210 SAS-R6, and 7210 SAS-R12. Use the following guidelines to avoid CIR oversubscription:
- To use SAP scheduler mode for access or hybrid port mode, configure the CIR on queues in the SAP egress policy and SAP aggregates or network aggregates based on the lower ETH-BN expected rate, and ensure that the CIR is not oversubscribed. A change in the ETH-BN rate will not cause CIR oversubscription because the values are based on the lowest ETH-BN rate.
- After an ETH-BN rate change is detected, update the QoS policy CIR and PIR values, and SAP and network aggregate rates from the management station to prevent CIR oversubscription.
3.3.4. Port-based MEPs
The 7210 SAS supports port-based MEPs for use with CFM ETH-BN. The port MEP must be configured at level 0 or 1 and can be used for ETH-BN message reception and processing as described in ITU-T Y.1731 Ethernet Bandwidth Notification. Port-based MEPs only support CFM CC, LT, LS, and RDI message processing; other CFM and Y.1731 messages are not supported.
| Note: Port-based MEPs are designed for the ETH-BN application. Nokia does not recommend the use of port-based MEPs with other applications. |
3.3.5. ETH-CFM statistics
| Note: This feature is supported on all 7210 SAS platforms as described in this document, including those operating in access-uplink mode. |
A number of statistics are available to view the current processing requirements for CFM. Any packet that is counted against the CFM resource is included in the statistics counters. The counters do not include sub-second CCM and ETH-CFM PDUs generated by non-ETH-CFM functions (which include OAM-PM & SAA) or filtered by a security configuration.
SAA and OAM-PM use standard CFM PDUs. The reception of these packets is included in the receive statistics. However, SAA and OAM-PM launch their own test packets and do not consume ETH-CFM transmission resources.
Per-system and per-MEP statistics are included with a per-OpCode breakdown. These statistics help operators determine the busiest active MEPs on the system and provide a breakdown of per-OpCode processing at the system and MEP level.
Use the show eth-cfm statistics command to view the statistics at the system level. Use the show eth-cfm mep mep-id domain md-index association ma-index statistics command to view the per-MEP statistics. Use the clear eth-cfm mep mep-id domain md-index association ma-index statistics command to clear statistics. The clear command clears the statistics for only the specified function. For example, clearing the system statistics does not clear the individual MEP statistics because each MEP maintains its own unique counters.
All known OpCodes are listed in the transmit and receive columns. Different versions for the same OpCode are not displayed. This does not imply that the network element supports all functions listed in the table. Unknown OpCodes are dropped.
Use the tools dump eth-cfm top-active-meps command to display the top ten active MEPs in the system. This command provides a nearly real-time view of the busiest active MEPS by displaying the active (not shutdown) MEPs and inactive (shutdown) MEPs in the system. ETH-CFM MEPs that are shutdown continue to consume CPM resources because the main task is syncing the PDUs. The counts begin from the last time that the command was issued using the clear option.
3.3.6. Synthetic Loss Measurement (ETH-SL)
Nokia applied pre-standard OpCodes 53 (Synthetic Loss Reply) and 54 (Synthetic Loss Message) for the purpose of measuring loss using synthetic packets.
| Note: These will be changes to the assigned standard values in a future release. This means that the Release 4.0R6 is prestandard and will not interoperate with future releases of SLM or SLR that supports the standard OpCode values. |
This synthetic loss measurement approach is a single-ended feature that allows the operator to run on-demand and proactive tests to determine “in”, “out” loss and “unacknowledged” packets. This approach can be used between peer MEPs in both point to point and multipoint services. Only remote MEP peers within the association and matching the unicast destination will respond to the SLM packet.
The specification uses various sequence numbers to determine in which direction the loss occurred. Alcatel-Lucent has implemented the required counters to determine loss in each direction. To correctly use the information that is gathered the following terms are defined:
- countThe count is the number of probes that are sent when the last frame is not lost. When the last frames is or are lost, the count and unacknowledged equals the number of probes sent.
- out-loss (far-end)Out-loss packets are lost on the way to the remote node, from test initiator to the test destination.
- in-loss (near-end)In-loss packets are lost on the way back from the remote node to the test initiator.
- unacknowledgedUnacknowledged number of packets are at the end of the test that were not responded to.
The per probe specific loss indicators are available when looking at the on-demand test runs, or the individual probe information stored in the MIB. When tests are scheduled by Service Assurance Application (SAA) the per probe data is summarized and per probe information is not maintained. Any “unacknowledged” packets will be recorded as “in-loss” when summarized.
The on-demand function can be executed from CLI or SNMP. The on demand tests are meant to provide the carrier a way to perform on the spot testing. However, this approach is not meant as a method for storing archived data for later processing. The probe count for on demand SLM has a range of one to 100 with configurable probe spacing between one second and ten seconds. This means it is possible that a single test run can be up to 1000 seconds.
Although possible, it is more likely the majority of on demand case can increase to 100 probes or less at a one second interval. A node may only initiate and maintain a single active on demand SLM test at any specific time. A maximum of one storage entry per remote MEP is maintained in the results table. Subsequent runs to the same peer can overwrite the results for that peer. This means, when using on demand testing the test should be run and the results checked before starting another test.
The proactive measurement functions are linked to SAA. This backend provides the scheduling, storage and summarization capabilities. Scheduling may be either continuous or periodic. It also allows for the interpretation and representation of data that may enhance the specification. As an example, an optional TVL has been included to allow for the measurement of both loss and delay or jitter with a single test. The implementation does not cause any interoperability because the optional TVL is ignored by equipment that does not support this. In mixed vendor environments loss measurement continues to be tracked but delay and jitter can only report round trip times. It is important to point out that the round trip times in this mixed vendor environments include the remote nodes processing time because only two time stamps will be included in the packet. In an environment where both nodes support the optional TLV to include time stamps unidirectional and round trip times is reported. Since all four time stamps are included in the packet the round trip time in this case does not include remote node processing time. Of course, those operators that wish to run delay measurement and loss measurement at different frequencies are free to run both ETH-SL and ETH-DM functions. ETH-SL is not replacing ETH-DM. Service Assurance is only briefly described here to provide some background on the basic functionality. To know more about SAA functions see Service Assurance Agent overview.
The ETH-SL packet format contains a test-id that is internally generated and not configurable. The test-id is visible for the on demand test in the display summary. It is possible for a remote node processing the SLM frames receives overlapping test-ids as a result of multiple MEPs measuring loss between the same remote MEP. For this reason, the uniqueness of the test is based on remote MEP-ID, test-id and Source MAC of the packet.
ETH-SL is applicable to up and down MEPs and as per the recommendation transparent to MIPs. There is no coordination between various fault conditions that could impact loss measurement. This is also true for conditions where MEPs are placed in shutdown state as a result of linkage to a redundancy scheme like MC-LAG. Loss measurement is based on the ETH-SL and not coordinated across different functional aspects on the network element. ETH-SL is supported on service based MEPs.
It is possible that two MEPs may be configured with the same MAC on different remote nodes. This causes various issues in the FDB for multipoint services and is considered a misconfiguration for most services. It is possible to have a valid configuration where multiple MEPs on the same remote node have the same MAC. In fact, this is likely to happen. In this release, only the first responder is used to measure packet loss. The second responder is dropped. Since the same MAC for multiple MEPs is only truly valid on the same remote node this should is an acceptable approach.
There is no way for the responding node to understand when a test is completed. For this reason a configurable “inactivity-timer” determines the length of time a test is valid. The timer will maintain an active test as long as it is receiving packets for that specific test, defined by the test-id, remote MEP Id and source MAC. When there is a gap between the packets that exceeds the inactivity-timer the responding node responds with a sequence number of one regardless of what the sequence number was the instantiating node sent. This means the remote MEP accepts that the previous test has expired and these probes are part of a new test. The default for the inactivity timer is 100 second and has a range of 10 to 100 seconds.
The responding node is limited to a fixed number of SLM tests per platform. Any test that attempts to involve a node that is already actively processing more than the system limit of the SLM tests shows up as “out loss” or “unacknowledged” packets on the node that instantiated the test because the packets are silently discarded at the responder. It is important for the operator to understand this is silent and no log entries or alarms is raised. It is also important to keep in mind that these packets are ETH-CFM based and the different platforms stated receive rate for ETH-CFM must not be exceeded. ETH-SL provides a mechanism for operators to pro-actively trend packet loss for service based MEPs.
3.3.6.1. Configuration example
The following figure shows the configuration required for proactive SLM test using SAA.
Figure 24: SLM example

The output from the MIB is shown as follows as an example of an on-demand test. Node1 is tested for this example. The SAA configuration does not include the accounting policy required to collect the statistics before they are overwritten. NODE2 does not have an SAA configuration. NODE2 includes the configuration to build the MEP in the VPLS service context.
3.3.7. ETH-CFM QoS considerations
UP MEPs and DOWN MEPs have been aligned as of this release to better emulate service data. When an UP MEP or DOWN MEP is the source of the ETH-CFM PDU the priority value configured, as part of the configuration of the MEP or specific test, will be treated as the Forwarding Class (FC) by the egress QoS policy. If there is no egress QoS policy the priority value will be mapped to the CoS values in the frame. However, egress QoS Policy may overwrite this original value. The Service Assurance Agent (SAA) uses fc fc-name to accomplish similar functionality.
UP MEPs and DOWN MEPs terminating an ETH-CFM PDU will use the received FC as the return priority for the appropriate response, again feeding into the egress QoS policy as the FC.
ETH-CFM PDUs received on the MPLS-SDP bindings will now correctly pass the EXP bit values to the ETH-CFM application to be used in the response.
These are default behavioral changes without CLI options.
3.3.8. ETH-CFM configuration guidelines
The following lists ETH-CFM configuration guidelines:
- Up MEPs and bidirectional MIPs are not created by default on system bootup, and additional resources must be allocated to enable Up MEP and bidirectional MIP functionality. By default, no resources are allocated. Before Up MEPs and bidirectional MIPs can be created, the user must first use the configure>system>resource-profile context to explicitly allocate hardware resources for use with these features. The software will reject the configuration to create an Up MEP or bidirectional MIP and generate an error until resources are allocated. Refer to the 7210 SAS-Mxp, R6, R12, S, Sx, T Basic System Configuration Guide for more information.
- 7210 SAS platforms support functionality for ingress and egress MIPs. In most services, only ingress MIPs are supported. Some services also support both ingress and egress MIPs, also called bidirectional MIPs. An ingress MIP or a Down MIP processes messages in the ingress direction when the OAM message is received on ingress of the SAP or port (subject to other checks). An egress MIP or an UP MIP refers to a MIP that processes messages in the egress direction when the OAM message is being sent out of the SAP/port. See Table 12, Table 13, Table 14, Table 15, Table 16, and Table 17 for more information about ingress MIP, egress MIP, and bidirectional MIP support for service entities.
- On 7210 SAS platforms, Ethernet Linktrace Response (ETH-LTR) is always sent out with priority 7.
- 7210 SAS platforms, send out all CFM packets as in-profile. Currently, there is no mechanism in the SAA tools to specify the profile of the packet.
- On the 7210 SAS-R6 and 7210 SAS-R12, and on the 7210 SAS-Sx/S 1/10GE operating in the standalone-VC mode, before configuring bidirectional MIPs for an Epipe SAP or Epipe SDP binding, resources must be allocated to both Down MEPs and Up MEPs. That is, bidirectional MIPs in an Epipe service use the resources from both the Down MEP and Up MEP resource pools. By default, no resources are allocated for bidirectional MIPs, and configuration attempts before resource allocation are not permitted by the system and will generate a system error/log. Refer to the 7210 SAS-Mxp, R6, R12, S, Sx, T Basic System Configuration Guide for more information.
- Sender ID TLV processing (insertion and reception) is not supported for CCM messages for MEPs that are implemented in hardware; that is, on 7210 SAS-T Down MEPs in access-uplink mode. For these MEPs, Sender ID TLV processing is supported only for LTM and LBM messages.
- Sender ID TLV processing is supported only for service MEPs. It is not supported for G.8032 MEPs.
- Facility MEPs are not supported on the 7210 SAS. G8032 MEPs are supported on the 7210 SAS.
- Ethernet rings are not configurable under all service types. Any service restrictions for MEP direction or MIP support will override the generic capability of the Ethernet ring MPs. Refer to the 7210 SAS-Mxp, R6, R12, S, Sx, T Interface Configuration Guide for more information about Ethernet rings.
- On 7210 SAS devices, when two bidirectional MIPs are configured in an Epipe service on both the service entities and endpoints (for example, on both the SAP and SDP configured in the Epipe service), only the MIP ingressing in the direction of linktrace messages responds. This is applicable to 7210 SAS platforms that support both ingress and egress MIPs (also referred to as bidirectional MIPs).
3.4. OAM mapping
OAM mapping is a mechanism that enables a way of deploying OAM end-to-end in a network where different OAM tools are used in different segments. For instance, an Epipe service could span across the network using Ethernet access (CFM used for OAM), pseudowire (T-LDP status signaling used for OAM), and Ethernet access (CFM used for OAM).
In the 7210 SAS implementation, the Service Manager (SMGR) is used as the central point of OAM mapping. It receives and processes the events from different OAM components, then decides the actions to take, including triggering OAM events to remote peers.
Fault propagation for CFM is by default disabled at the MEP level to maintain backward compatibility. When required, it can be explicitly enabled by configuration.
Fault propagation for a MEP can only be enabled when the MA is comprised of no more than two MEPs (point-to-point).
3.4.1. CFM connectivity fault conditions
CFM MEP declares a connectivity fault when its defect flag is equal to or higher than its configured lowest defect priority. The defect can be any of the following depending on configuration:
- DefRDICCM
- DefMACstatus
- DefRemoteCCM
- DefErrorCCM
- DefXconCCM
The following additional fault condition applies to Y.1731 MEPs:
- reception of AIS for the local MEP level
Setting the lowest defect priority to allDef may cause problems when fault propagation is enabled in the MEP. In this scenario, when MEP A sends CCM to MEP B with interface status down, MEP B will respond with a CCM with RDI set. If MEP A is configured to accept RDI as a fault, then it gets into a dead lock state, where both MEPs will declare fault and never be able to recover.
The default lowest defect priority is DefMACstatus, which will not be a problem when interface status TLV is used. It is also very important that different Ethernet OAM strategies should not overlap the span of each other. In some cases, independent functions attempting to perform their normal fault handling can negatively impact the other. This interaction can lead to fault propagation in the direction toward the original fault, a false positive, or worse, a deadlock condition that may require the operator to modify the configuration to escape the condition. For example, overlapping Link Loss Forwarding (LLF) and ETH-CFM fault propagation could cause these issues.
For the DefRemoteCCM fault, it is raised when any remote MEP is down. So whenever a remote MEP fails and fault propagation is enabled, a fault is propagated to SMGR.
3.4.2. CFM fault propagation methods
When CFM is the OAM module at the other end, it is required to use any of the following methods (depending on local configuration) to notify the remote peer:
- Generating AIS for certain MEP levels
- Sending CCM with interface status TLV “down”
- Stopping CCM transmission
| Note: 7210 platforms expect that the fault notified using interface status TLV, is cleared explicitly by the remote MEP when the fault is no longer present on the remote node. On 7210 SAS, use of CCM with interface status TLV Down is not recommended to be configured with a Down MEP, unless it is known that the remote MEP clears the fault explicitly. |
User can configure UP MEPs to use Interface Status TLV with fault propagation. Special considerations apply only to Down MEPs.
When a fault is propagated by the service manager, if AIS is enabled on the SAP/SDP-binding, then AIS messages are generated for all the MEPs configured on the SAP/SDP-binding using the configured levels.
Note that the existing AIS procedure still applies even when fault propagation is disabled for the service or the MEP. For example, when a MEP loses connectivity to a configured remote MEP, it generates AIS if it is enabled. The new procedure that is defined in this document introduces a new fault condition for AIS generation, fault propagated from SMGR, that is used when fault propagation is enabled for the service and the MEP.
The transmission of CCM with interface status TLV must be done instantly without waiting for the next CCM transmit interval. This rule applies to CFM fault notification for all services.
Notifications from SMGR to the CFM MEPs for fault propagation should include a direction for the propagation (up or down: up means in the direction of coming into the SAP/SDP-binding; down means in the direction of going out of the SAP/SDP-binding), so that the MEP knows what method to use. For instance, an up fault propagation notification to a down MEP will trigger an AIS, while a down fault propagation to the same MEP can trigger a CCM with interface TLV with status down.
For a specific SAP/SDP-binding, CFM and SMGR can only propagate one single fault to each other for each direction (up or down).
When there are multiple MEPs (at different levels) on a single SAP/SDP-binding, the fault reported from CFM to SMGR will be the logical OR of results from all MEPs. Basically, the first fault from any MEP will be reported, and the fault will not be cleared as long as there is a fault in any local MEP on the SAP/SDP-binding.
3.4.3. Epipe services
Down and up MEPs are supported for Epipe services as well as fault propagation. When there are both up and down MEPs configured in the same SAP/SDP-binding and both MEPs have fault propagation enabled, a fault detected by one of them will be propagated to the other, which in turn will propagate fault in its own direction.
3.4.3.1. CFM detected fault
When a MEP detects a fault and fault propagation is enabled for the MEP, CFM needs to communicate the fault to SMGR, so SMGR will mark the SAP/SDP-binding faulty but still oper-up. CFM traffic can still be transmitted to or received from the SAP/SDP-binding to ensure when the fault is cleared, the SAP will go back to normal operational state. Since the operational status of the SAP/SDP-binding is not affected by the fault, no fault handling is performed. For example, applications relying on the operational status are not affected.
If the MEP is an up MEP, the fault is propagated to the OAM components on the same SAP/SDP-binding; if the MEP is a down MEP, the fault is propagated to the OAM components on the mate SAP/SDP-binding at the other side of the service.
3.4.3.2. SAP/SDP-binding failure (including pseudowire status)
When a SAP/SDP-binding becomes faulty (oper-down, admin-down, or pseudowire status faulty), SMGR needs to propagate the fault to up MEPs on the same SAP/SDP-bindings about the fault, as well as to OAM components (such as down MEPs) on the mate SAP/SDP-binding.
3.4.3.3. Service down
This section describes procedures for the scenario where an Epipe service is down due to the following:
- Service is administratively shutdown. When service is administratively shutdown, the fault is propagated to the SAP/SDP-bindings in the service.
- If the Epipe service is used as a PBB tunnel into a B-VPLS, the Epipe service is also considered operationally down when the B-VPLS service is administratively shutdown or operationally down. If this is the case, fault is propagated to the Epipe SAP.
In addition, one or more SAPs/SDP-bindings in the B-VPLS can be configured to propagate fault to this Epipe (see the following fault-propagation-bmac). If the B-VPLS is operationally up but all of these entities have detected fault or are down, the fault is propagated to this Epipe’s SAP.
3.4.3.4. Interaction with pseudowire redundancy
When a fault occurs on the SAP side, the pseudowire status bit is set for both active and standby pseudowires. When only one of the pseudowire is faulty, SMGR does not notify CFM. The notification occurs only when both pseudowire becomes faulty. The SMGR propagates the fault to CFM.
Since there is no fault handling in the pipe service, any CFM fault detected on an SDP binding is not used in the pseudowire redundancy’s algorithm to choose the most suitable SDP binding to transmit on.
3.4.3.5. LLF and CFM fault propagation
LLF and CFM fault propagation are mutually exclusive. CLI protection is in place to prevent enabling both LLF and CFM fault propagation in the same service, on the same node and at the same time. However, there are still instances where irresolvable fault loops can occur when the two schemes are deployed within the same service on different nodes. This is not preventable by the CLI. At no time should these two fault propagation schemes be enabled within the same service.
3.4.3.6. 802.3ah EFM OAM mapping and interaction with service manager
802.3ah EFM OAM declares a link fault when any of the following occurs:
- loss of OAMPDU for a certain period of time
- receiving OAMPDU with link fault flags from the peer
When 802.3ah EFM OAM declares a fault, the port goes into operation state down. The SMGR communicates the fault to CFM MEPs in the service. OAM fault propagation in the opposite direction (SMGR to EFM OAM) is not supported.
3.4.4. Fault propagation to access dot1q/QinQ ports on the 7210 SAS-T in access-uplink mode
A fault on the access-uplink port brings down all access ports with services independent of the encapsulation type of the access port (null, dot1q, or QinQ), that is, support Link Loss Forwarding (LLF). A fault propagated from the access-uplink port to access ports is based on configuration. A fault is propagated only in a single direction from the access-uplink port to access port.
A fault on the access-uplink port is detected using Loss of Signal (LoS) and EFM-OAM.
The following figure shows local fault propagation.
Figure 25: Local fault propagation
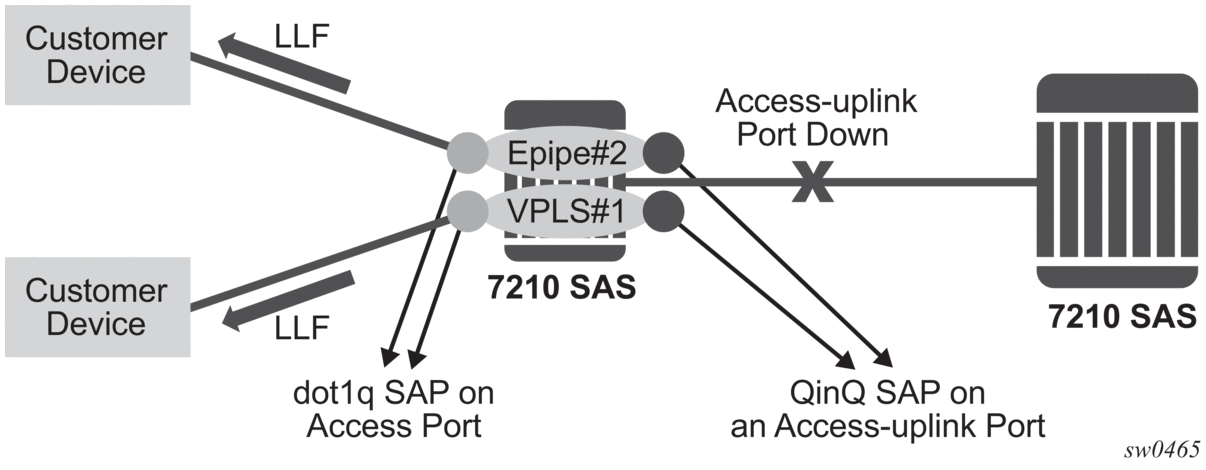
3.4.4.1. Configuring fault propagation
The operational group functionality, also referred to as oper-group, is used to detect faults on access-uplink ports and propagate them to all interested access ports regardless of their encapsulation. On the 7210 SAS operating in access-uplink mode, ports can be associated with oper-groups. Perform the following procedure to configure the use of the oper-group functionality for fault detection on a port and monitor-oper-group to track the oper-group status and propagate the fault based on the operational state of the oper-group.
- Create an oper-group (for example, “uplink-to-7210”).
- Configure an access-uplink port to track its operational state (for example, 1/1/20) and associate it with the oper-group created in 1 (that is, uplink-to-7210).
- Configure dot1q access ports for which the operational state must be driven by the operational state of the access-uplink port (for example, 1/1/1 and 1/1/5) as the monitor-oper-group.
- To detect a fault on the access-uplink port and change the operational state, use either the LoS or EFM OAM feature.
- When the operational state of the access-uplink port changes from up to down, the state of all access ports configured to monitor the group changes to down. Similarly, a change in state from down to up changes the operational state of the access port to up. When the operational state of the access port is brought down, the laser of the port is also shut down. The hold-timers command is supported to avoid the flapping of links.
3.4.4.1.1. Configuration example for fault propagation using oper-group
The following is a sample oper-group system configuration output.
| Note: Refer to the 7210 SAS-Mxp, R6, R12, S, Sx, T Basic System Configuration Guide for more information about this CLI. |
3.4.5. Fault propagation to access dot1q/QinQ ports on the 7210 SAS-Sx/S 1/10GE and 7210 SAS-Sx 10/100GE in standalone mode
| Note: An uplink port refers to an access port or LAG or hybrid port or LAG that is facing the network core. |
A fault on the uplink port or LAG brings down all access ports with services independent of the encapsulation type of the access port (null, dot1q, or QinQ), that is, support Link Loss Forwarding (LLF). A fault propagated from the uplink port or LAG to access ports is based on configuration. A fault is propagated only in a single direction from the uplink port or LAG to access port.
A fault on the uplink port or LAG is detected using Loss of Signal (LoS) and EFM-OAM.
The following figure show local fault propagation.
Figure 26: Local fault propagation
3.4.5.1. Configuring fault propagation
The oper-group functionality is used to detect faults on uplink ports or LAGs and propagate them to all interested access ports regardless of their encapsulation. On the 7210 SAS, ports or LAGs can be associated with oper-groups. Perform the following procedure to configure the use of the oper-group functionality for fault detection on a port or LAG and monitor-oper-group to track the oper-group status and propagate the fault based on the operational state of the oper-group:
- Create an oper-group (for example, “uplink-to-7210”).
- Configure an uplink port or LAG to track its operational state (for example, 1/1/20) and associate it with the oper-group created in 1 (that is, uplink-to-7210).
- Configure dot1q access ports for which the operational state must be driven by the operational state of the uplink port or LAG (for example, 1/1/1 and 1/1/5) as the monitor-oper-group.
- To detect a fault on the uplink port or LAG and change the operational state, use either the LoS or EFM OAM feature.
- When the operational state of the uplink port or LAG changes from up to down, the state of all access ports configured to monitor the group changes to down. Similarly, a change in state from down to up changes the operational state of the access port to up. When the operational state of the access port is brought down, the laser of the port is also shut down. The hold-timers command is supported to avoid the flapping of links.
3.4.5.1.1. Configuration example for fault propagation using oper-group
The following is a sample oper-group system configuration output.
| Note: Refer to the 7210 SAS-Mxp, R6, R12, S, Sx, T Basic System Configuration Guide for more information about this CLI. |
3.5. Service Assurance Agent overview
In the last few years, service delivery to customers has drastically changed. Services such as VPLS and VPRN are offered. The introduction of Broadband Service Termination Architecture (BSTA) applications such as Voice over IP (VoIP), TV delivery, video and high speed Internet services force carriers to produce services where the health and quality of Service Level Agreement (SLA) commitments are verifiable to the customer and internally within the carrier.
SAA is a feature that monitors network operations using statistics such as jitter, latency, response time, and packet loss. The information can be used to troubleshoot network problems, problem prevention, and network topology planning.
The results are saved in SNMP tables are queried by either the CLI or a management system. Threshold monitors allow for both rising and falling threshold events to alert the provider if SLA performance statistics deviate from the required parameters.
3.5.1. SAA two-way timing
SAA allows two-way timing for several applications. This provides the carrier and their customers with data to verify that the SLA agreements are being correctly enforced.
3.5.1.1. Traceroute implementation
The 7210 SAS devices insert the timestamp in software (by control CPU).
When interpreting these timestamps care must be taken that some nodes are not capable of providing timestamps, as such timestamps must be associated with the same IP-address that is being returned to the originator to indicate what hop is being measured.
3.5.1.2. NTP
Because NTP precision can vary (+/- 1.5ms between nodes even under best case conditions), SAA one-way latency measurements might display negative values, especially when testing network segments with very low latencies. The one-way time measurement relies on the accuracy of NTP between the sending and responding nodes.
3.5.1.3. Writing SAA results to accounting files
SAA statistics enables writing statistics to an accounting file. When results are calculated an accounting record is generated.
To write the SAA results to an accounting file in a compressed XML format at the termination of every test, the results must be collected, and, in addition to creating the entry in the appropriate MIB table for this SAA test, a record must be generated in the appropriate accounting file.
3.5.1.3.1. Accounting file management
Because the SAA accounting files have a similar role to existing accounting files that are used for billing purposes, existing file management information is leveraged for these accounting (billing) files.
3.5.1.3.2. Assigning SAA to an accounting file ID
When an accounting file has been created, accounting information can be specified and will be collected by the config>log>acct-policy> to file log-file-id context.
3.5.1.3.3. Continuous testing
When you configure a test, use the config>saa>test>continuous command to make the test run
continuously. Use the no continuous command to disable continuous testing and shutdown to
disable the test completely. When you have configured a test as continuous, you cannot start or stop it by using the saa test-name [owner test-owner] {start | stop} [no-accounting] command.
3.5.2. Configuring SAA test parameters
The following is a sample SAA configuration output.
3.6. Y.1564 testhead OAM tool
| Note: Port loopback with mac-swap and Y.1564 testhead is supported only for Epipe and VPLS services. |
ITU-T Y.1564 defines the out-of-service test methodology to be used and parameters to be measured to test service SLA conformance during service turn up. It primarily defines 2 test phases. The first test phase defines service configuration test, which consists of validating whether the service is configured correctly. As part of this test the throughput, Frame Delay, Frame Delay Variation (FDV), and Frame Loss Ratio (FLR) is measured for each service. This test is typically run for a short duration. The second test phase consists of validating the quality of services delivered to the end customer and is referred to as the service performance test. These tests are typically run for a longer duration and all traffic is generated up to the configured CIR for all the services simultaneously and the service performance parameters are measured for each the service.
The 7210 SAS supports service configuration test for user configured rate and measurement of delay, delay variation and frame loss ratio with the testhead OAM tool. The 7210 SAS testhead OAM tool supports bidirectional measurement and it can generate test traffic for only one service at a specific time. It can validate if the user specified rate is available and compute the delay, delay variation and frame loss ratio for the service under test at the specified rate. It is capable of generating traffic up to 1G rate. On some 7210 SAS devices, the user needs to configure the resources of the front-panel port for use with this feature and some other 7210 SAS platforms resources needed for this feature is automatically allocated by software from the internal ports. For more information, see the following Configuration guidelines, to which 7210 SAS platforms need user configuration and on which 7210 SAS platforms software allocates it automatically.
The following figure shows the remote loopback required and the flow of the frame through the network generated by the testhead tool.
Figure 27: 7210 acting as traffic generator and traffic analyzer
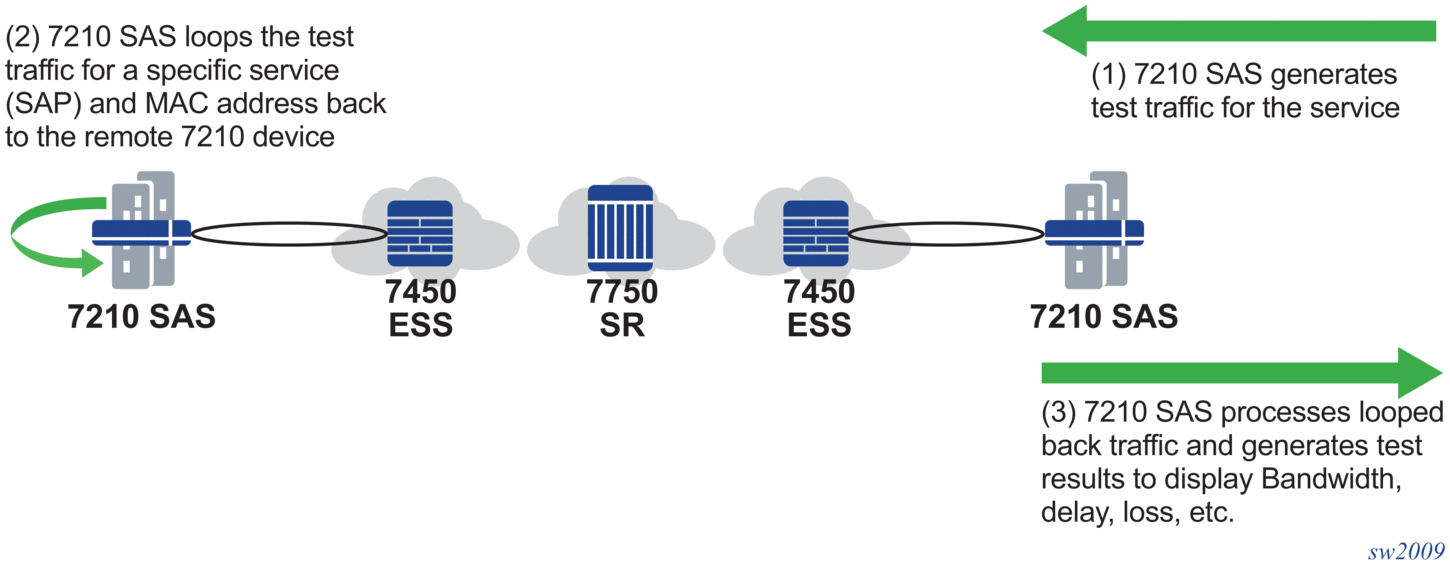
The tool allows the user to specify the frame payload header parameters independent of the test SAP configuration parameters to allow the user flexibility to test for different possible frame header encapsulations. This allows user to specify the appropriate VLAN tags, Ethertype, and Dot1p values, independent of the SAP configuration like with actual service testing. That is, the software does not use the parameters (For example: SAP ID, Source MAC, and Destination MAC) during the invocation of the testhead tool to build the test frames. Instead it uses the parameters specified using the frame-payload CLI command tree. The software does not verify that the parameters specified match the service configuration used for testing, for example, software does not match if the VLAN tags specified matches the SAP tags, the Ethertype specified matches the user configured port Ethertype, and so on. It is expected that the user configures the frame-payload appropriately so that the traffic matches the SAP configuration.
The 7210 SAS supports Y.1564 testhead for performing CIR or PIR tests in color-aware mode. With this functionality, users can perform service turn-up tests to validate the performance characteristics (delay, jitter, and loss) for committed rate (CIR) and excess rate above CIR (that is, PIR rate). The testhead OAM tool uses the in-profile packet marking value and out-of-profile packet marking value, to differentiate between committed traffic and PIR traffic in excess of CIR traffic. Traffic within CIR (that is, committed traffic) is expected to be treated as in-profile traffic in the network and traffic in excess of CIR (that is, PIR traffic) is expected to be treated as out-of-profile traffic in the network, allowing the network to prioritize committed traffic over PIR traffic. The testhead OAM tool allows the user to configure individual thresholds for green or in-profile packets and out-of-profile or yellow packets. It is used by the testhead OAM tool to compare the measured value for green or in-profile packets and out-of-profile or yellow packets against the configured thresholds and report success or failure.
The functionality listed as follows is supported by the testhead OAM tool:
- Supports configuration of only access SAPs as the test measurement point.
- Supports all port encapsulation supported on all service SAP types, with some exceptions as noted in the following Configuration guidelines.
- Supported for only VPLS and Epipe service.
- Supports two-way measurement of service performance metrics. The tests measure throughput, frame delay, frame delay variation, and frame loss ratio.
- For two-way measurement of the service performance metrics, such as frame delay and frame delay variation, test frames (also called as marker packets) are injected at a low rate at periodic intervals. Frame delay and Frame delay variation is computed for these frames. Hardware-based timestamps are used for delay computation.
- The 7210 SAS supports configuration of a rate value and provides an option to measure the performance metrics. The testhead OAM tool generates traffic up to the specified rate and measures service performance metrics such as delay, jitter, and loss for in-profile and out-of-profile traffic.
- Testhead tool can generate traffic up to about 1G rate. CIR and PIR rate can be specified by the user and is rounded off the nearest rate the hardware supports by using the adaptation rule configured by the user.
- Allows the user to specify the different frame-sizes from 64 bytes - 9212 bytes.
- User can configure the following frame payload types: L2 payload, IP payload, and IP/TCP/UDP payload. Testhead tool will use the configured values for the IP header fields and TCP header fields based on the payload type configured. User is provided with an option to specify the data pattern to used in the payload field of the frame/packet.
- Allows the user to configure the duration of the test up to a maximum of 24 hours, 60 minutes, and 60 seconds. The test performance measurements by are done after the specified rate is achieved. At any time user can probe the system to know the current status and progress of the test.
- Supports configuration of the Forwarding Class (FC). It is expected that user will define consistent QoS classification policies to map the packet header fields to the FC specified on the test SAP ingress on the local node, in the network on the nodes through which the service transits, and on the SAP ingress in the remote node.
- Allows the user to configure a test-profile, also known as, a policy template that defines the test configuration parameters. User can start a test using a preconfigured test policy for a specific SAP and service. The test profile allows the user to configure the acceptance criteria. The acceptance criteria allows user to configure the thresholds that indicates the acceptable range for the service performance metrics. An event is generated if the test results exceed the configured thresholds. For more information, see the following CLI section.At the end of the test, the measured values for FD, FDV, and FLR are compared against the configured thresholds to determine the PASS or FAIL criteria and to generate a trap to the management station. If the acceptance criteria is not configured, the test result is declared to be PASS, if the throughput is achieved and frame-loss is 0 (zero).
- ITU-T Y.1564 specifies different test procedures as follows. CIR and PIR configuration tests are supported by the testhead tool, as follows:
- CIR and PIR configuration test (color-aware and non-color aware).
- Traffic policing test (color-aware and non-color aware) is supported. Traffic policing tests can be executed by the user by specifying a PIR to be 125% of the desired PIR. Traffic policing test can be executed in either color-aware mode or color-blind (non-color-aware) mode.
- ITU-T Y.1564 specifies separate test methodology for color-aware and non-color-aware tests. The standard requires a single test to provide the capability to generate both green-color/in-profile traffic for rates within CIR and yellow-color or out-of-profile traffic for rates above CIR and within EIR. The 7210 SAS testhead marks test packets appropriately when generating the traffic, as SAP ingress does not support color-aware metering, it is not possible to support EIR color-aware, and traffic policing color-aware tests end-to-end in a network (that is, from test SAP to test SAP). Instead, It is possible to use the tests to measure the performance parameters from the other endpoint (example Access-uplink SAP) in the service, through the network, to the remote test SAP, and back again to the local test SAP.
- The 7210 SAS Y.1564 testhead is applicable only for VPLS and epipe services.
3.6.1. Prerequisites for using the testhead tool
This section describes the prerequisites for using the Testhead tool.
3.6.1.1. Generic prerequisites for use of testhead tool (applicable for all 7210 SAS platforms)
The following describes the generic prerequisites for the use of the Testhead tool:
- It is expected that the user will configure the appropriate ACL and QoS policies to ensure that the testhead traffic is processed as desired by the local and remote node/SAP. In particular, QoS policies in use must ensure that the rate in use for the SAP ingress meters exceed or are equal to the user configured rate for testhead tests and the classification policies map the testhead packets to the appropriate FCs/queues (the FC classification must match the FC specified in the CLI command testhead-test) using the packet header fields configured in the frame-payload. Similarly, ACL policies must ensure that testhead traffic is not blocked.
- The testhead OAM tool does not check the state of the service or the SAPs on the local endpoint before initiating the tests. The operator must ensure that the service and SAPs used for the test are UP before the tests are started. If they are not, the testhead tool will report a failure.
- The port configuration of the ports used for validation (For example: access port on which the test SAP is configured and access-uplink port) must not be modified after the testhead tool is invoked. Any modifications can be made only when the testhead tool is not running.
- Testhead tool can be used to test only unicast traffic flows. It must not be used to test BUM traffic flows.
- Only out-of-service performance metrics can be measured using the testhead OAM tool. For in-service performance metrics, user has the option to use SAA based Y.1731/CFM tools.
The following describes some prerequisites to use the testhead tool:
- The configuration guidelines and prerequisites that are to be followed when the port loopback with MAC swap feature is used standalone, applies to its use along with the testhead tool. For more information, see the description in the 7210 SAS-Mxp, R6, R12, S, Sx, T Interface Configuration Guide.
- Users must configure resources for ACL MAC criteria in ingress-internal-tcam using the command config>system>resource-profile>ingress-internal-tcam> cl-sap-ingress> mac-match-enable. Additionally users must allocate resources to egress ACL MAC or IPv4 or IPv6 64-bit criteria using the command config>system> resource-profile> egress-internal-tcam> acl-sap-egress> mac-ipv4-match-enable or mac-ipv6-64bit-enable or mac-ipv4-match-enable). The testhead tool uses resources from these resource pools. If no resources are allocated to these pools or no resources are available for use in these pools, then the testhead fails to function. Testhead needs a minimum of about 6 entries from the ingress internal TCAM pool and 2 entries from the egress internal TCAM pool. If users allocate resources to egress ACLs IPv6 128-bit match criteria (using the command config> system> resource-profile> egress-internal-tcam> acl-sap-egress> ipv6-128bit-match-enable), then the testhead tool fails to function.
- For both Epipe and VPLS service, the test can be used to perform only a point-to-point test between the specific source and destination MAC address. Port loopback MAC swap functionality must be used for both Epipe and VPLS services. The configured source and destination MAC address is associated with the two SAPs configured in the service and used as the two endpoints. That is, the user configured source MAC and destination MAC addresses are used by the testhead tool on the local node to identify the packets as belonging to testhead application and are processed appropriately at the local end and at the remote end these packets are processed by the port loopback with mac-swap application.
- Configure the MACs (source and destination) statically for VPLS service.
- Port loopback must be in use on both the endpoints (that is, the local node, the port on which the test SAP is configured and the remote node, the port on which the remote SAP is configured for both Epipe and VPLS services. Port loopback with mac-swap must be setup by the user on both the local end and the remote end before invoking the testhead tool. These must match appropriately for traffic to flow, else there will be no traffic flow and the testhead tool reports a failure at the end of the completion of the test run.
- Additionally, port loopback with mac-swap must be used at both the ends and if any services/SAPs are configured on the test port, they need to be shutdown to avoid packets being dropped on the non-test SAP. The frames generated by the testhead tool will egress the access SAP and ingress back on the same port, using the resources of the 2 internal loopback ports (one for testhead and another for mac-swap functionality), before being sent out to the network side (typically an access-uplink SAP) to the remote end”. At the remote end, it is expected that the frames will egress the SAP under test and ingress back in again through the same port, going through another loopback (with mac-swap) before being sent back to the local node where the testhead application is running.
- The FC specified is used to determine the queue to enqueue the marker packets generated by testhead application on the egress of the test SAP on the local node.
- The use of port loopback is service affecting. It affects all the services configured on the port. It is not recommended to use a SAP, if the port on which they are configured, is used to transport the service packets toward the core. As, a port loopback is required for the testhead to function correctly, doing so might result in loss of connectivity to the node when in-band management is in use. Additionally, all services being transported to the core will be affected.
- It also affects service being delivered on that SAP. Only out-of-service performance metrics can be measured using testhead OAM tool. For in-service performance metrics, user has the option to use SAA based Y.1731/CFM tools.
- Testhead tool uses marker packets with special header values. The QoS policies and ACL policies need to ensure that same treatment as accorded to testhead traffic is given to marker packets. Marker packets are IPv4 packet with IP option set and IP protocol set to 252. It uses the source and destination MAC addresses, Dot1p, IP ToS, IP DSCP, IP TTL, IP source address and destination address as configured in the frame-payload. It does not use the IP protocol and TCP/UDP port numbers from the frame-payload configured. If the payload-type is “l2”, IP addresses are set to 0.0.0.0, IP TTL is set to 0, IP TOS is set to 0 and DSCP is set to be, if these values are not explicitly configured in the frame-payload. Ethertype configured in the frame-payload is not used for marker packets, it is always set to Ethertype = 0x0800 (Ethertype for IPv4) as marker packets are IPv4 packets.QoS policies applied in the network needs to configured such that the classification for marker packets is similar to service packets. An easy way to do this is by using the header fields that are common across marker packets and service packets, such as MAC (src and dst) addresses, VLAN ID, Dot1p, IPv4 (source and destination) addresses, IP DSCP, and IP ToS. Use of other fields which are different for marker packets and service packets is not recommended. ACL policies in the network must ensure that marker packets are not dropped.
- The mac-swap loopback port, the testhead loopback port and the uplink port must not be modified after the testhead tool is invoked. Any modifications can be made only when the testhead tool is not running.
- Link-level protocols (For example: LLDP, EFM, and other protocols) must not be enabled on the port on which the test SAP is configured. In general, no other traffic must be sent out of the test SAP when the testhead tool is running.
- The frame payload must be configured such that number of tags match the number of SAP tags. For example: For 0.* SAP, the frame payload must be untagged or priority tagged and it cannot contain another tag following the priority tag.
3.6.2. Configuration guidelines
This section provide the configuration guidelines for this feature (that is, testhead OAM tool). It is applicable to all the platforms described in this guide unless a specific platform is called out explicitly:
- On the 7210 SAS-Sx 10/100GE platform, the following limitation must be addressed in the testhead configuration: the testhead loopback port and MAC swap loopback port must be configured with the same Ethernet speeds and have the same operational speeds. Failure to do so will cause the testhead session start to fail.
- SAPs configured on LAG cannot be configured for testing with testhead tool. Other than the test SAP, other service endpoints (For example: SAPs/SDP-Bindings) configured in the service can be over a LAG.
- The user needs to configure the resources of another port for use with the testhead OAM tool. The user can configure the resources of the internal virtual ports (if available) or configure the resources of a front-panel port for use with testhead OAM tool. Please read the details provided in the CLI command config>system>loopback-no-svc-port in the 7210 SAS-Mxp, R6, R12, S, Sx, T Interface Configuration Guide Interfaces to know if front-panel port resources are needed and use the command show>system>internal-loopback-ports [detail] to know if internal port resources are available in use by other applications. The port configured for testhead tool use cannot be shared with other applications that need the loopback port. The resources of the loopback port are used by the testhead tool for traffic generation.

Note: On 7210 SAS-R6 and 7210 SAS-R12, the ports allocated for testhead OAM tool, the MAC swap OAM tool and the test SAP must be on the same line card and cannot be on different line cards.
- Port loopback with mac-swap is used at both ends and all services on the port on which the test SAP is configured and SAPs in the VPLS service, other than the test SAP should be shutdown or should not receive any traffic.
- The configured CIR/PIR rate is rounded off to the nearest available hardware rates. User is provided with an option to select the adaptation rule to use (similar to support available for QoS policies).
- 7210 SAS supports all port speeds (that is, up to 1G rate). Users need to configure the appropriate loopback port to achieve a desired rate. For example, user must dedicate the resources of a 1G port, if intended to test rates to go up to 1G.
- ITU-T Y.1564 recommends to provide an option to configure the CIR step-size and the step-duration for the service configuration tests. This is not supported directly in 7210 SAS. It can be achieved by SAM or a third-party NMS system or an application with configuration of the desired rate and duration to correspond to the CIR step-size and step duration and repeating the test a second time, with a different value of the rate (that is, CIR step size) and duration (that is, step duration) and so on.
- Testhead waits for about 5 seconds at the end of the configured test duration before collecting statistics. This allows for all in-flight packets to be received by the node and accounted for in the test measurements. User cannot start another test during this period.
- When using testhead to test bandwidth available between SAPs configured in a VPLS service, operators must ensure that no other SAPs in the VPLS service are exchanging any traffic, particularly BUM traffic and unicast traffic destined to either the local test SAP or the remote SAP. BUM traffic eats into the network resources which is also used by testhead traffic.
- It is possible that test packets (both data and/or marker packets) remain in the loop created for testing when the tests are killed. This is highly probably when using QoS policies with very less shaper rates resulting in high latency for packets flowing through the network loop. User must remove the loop at both ends when the test is complete or when the test is stopped and wait for a suitable time before starting the next test for the same service, to ensure that packets drain out of the network for that service. If this is not done, then the subsequent tests might process and account these stale packets, resulting in incorrect results. Software cannot detect stale packets in the loop as it does not associate or check each and every packet with a test session
- Traffic received from the remote node and looped back into the test port (where the test SAP is configured) on the local end (that is, the end where the testhead tool is invoked) is dropped by hardware after processing (and is not sent back to the remote end). The SAP ingress QoS policies and SAP ingress filter policies must match the packet header fields specified by the user in the testhead profile, except that the source/destination MAC addresses are swapped.
- Latency is not be computed if marker packets are not received by the local node where the test is generated and printed as 0 (zero), in such cases. If jitter = 0 and latency > 0, it means that jitter calculated is less than the precision used for measurement. There is also a small chance that jitter was not actually calculated, that is, only one value of latency has been computed. This typically indicates a network issue, rather than a testhead issue.
- When the throughput is not met, FLR cannot be calculated. If the measured throughput is approximately +/-10% of the user configured rate, FLR value is displayed; else software prints “Not Applicable”. The percentage of variance of measured bandwidth depends on the packet size in use and the configured rate.
- Users must not use the CLI command to clear statistics of the test SAP port, testhead loopback port, or MAC swap loopback port when the testhead tool is running. The port statistics are used by the tool to determine the Tx/Rx frame count.
- Testhead tool generates traffic at a rate slightly above the CIR. The additional bandwidth is attributable to the marker packets used for latency measurements. This is not expected to affect the latency measurement or the test results in a significant way.
- If the operational throughput is 1kbps and it is achieved in the test loop, the throughput computed could still be printed as 0 if it is less than 1Kb/s (0.99 kb/s, for example). Under such cases, if FLR is PASS, the tool indicates that the throughput has been achieved.
- The testhead tool displays a failure result if the received count of frames is less than the injected count of frames, even though the FLR might be displayed as 0. This happens due to truncation of FLR results to 6 decimal places and can happen when the loss is very less.
- As the rate approaches 1Gbps or the maximum bandwidth achievable in the loop, user needs to account for the marker packet rate and the meter behavior while configuring the CIR rate. That is, if the user needs to test 1Gbps for 512 bytes frame size, then they will need to configure about 962396Kbps, instead of 962406Kbps, the maximum rate that can be achieved for this frame-size. In general, they would need to configure about 98%-99% (based on packet size) of the maximum possible rate to account for marker packets when they need to test at rates which are closer to bandwidth available in the network. The reason for this is that at the maximum rate, injection of marker packets by CPU will result in drops of either the injected data traffic or the marker packets themselves, as the net rate exceeds the capacity. These drops cause the testhead to always report a failure, unless the rate is marginally reduced.
- The testhead uses the Layer 2 rate, which is calculated by subtracting the Layer 1 overhead that is caused when the IFG and Preamble are added to every Ethernet frame (typically about 20 bytes (IFG = 12 bytes and Preamble = 8 bytes)). The testhead tool uses the user-configured frame size to compute the Layer 2 rate and does not allow the user to configure a value greater than that rate. For 512-byte Ethernet frames, the L2 rate is 962406 Kb/s and the Layer 1 rate is 1 Gb/s.
- It is not expected that the operator will use the testhead tool to measure the throughput or other performance parameters of the network during the course of network event. The network events could be affecting the other SAP/SDP-Binding/PW configured in the service. Examples are transition of a SAP due to G8032 ring failure, transition of active/ standby SDP-Binding/PW due to link or node failures.
- The 2-way delay (also known as “latency”) values measured by the testhead tool is more accurate than obtained using OAM tools, as the timestamps are generated in hardware.
- The 7210 SAS does not support color-aware metering on access SAP ingress, therefore, any color-aware packets generated by the testhead is ignored on access SAP ingress. 7210 SAS service access port, access-uplink port, or network port can mark the packets appropriately on egress to allow the subsequent nodes in the network to differentiate the in-profile and out-of-profile packets and provide them with appropriate QoS treatment. The 7210 SAS access-uplink ingress and network port ingress is capable of providing appropriate QoS treatment to in-profile and out-of-profile packets.
- The marker packets are sent over and above the configured CIR or PIR rate, the tool cannot determine the number of green packets injected and the number of yellow packets injected individually. Therefore, marker packets are not accounted in the injected or received green or in-profile and yellow or out-of-profile packet counts. They are only accounted for the Total Injected and the Total Received counts. So, the FLR metric accounts for marker packet loss (if any), while green or yellow FLR metric does not account for any marker packet loss.
- Marker packets are used to measure green or in-profile packets latency and jitter and the yellow or out-of-profile packets latency and jitter. These marker packets are identified as green or yellow based on the packet marking (Example: dot1p). The latency values can be different for green and yellow packets based on the treatment provided to the packets by the network QoS configuration.The following table describes SAP encapsulation supported by the testhead tool.
Table 19: SAP encapsulations supported by testhead tool
Epipe service configured with svc-sap-type
Test SAP encapsulations
null-star
Null, :* , 0.* , Q.*
Any
Null , :0 , :Q , :Q1.Q2
dot1q-preserve
:Q
- The following combination of 1G and 10G port can be used, as long as the rate validated is less than or equal to 1Gb/s:
- The test SAP is a 10G port, the uplink is 1G port and other ports (that is, uplink, MAC swap, and testhead) are 1G port.
- The test SAP is a 10G port, the uplink is a 10G port and other ports (that is, MAC swap and testhead) are 1G port.
- The test SAP is a 1G port, the uplink is a 10G port and other ports (that is, MAC swap and testhead) are 1G port.
3.6.3. Configuring testhead tool parameters
The following is a sample port loopback MAC swap configuration output using the service and SAP.
The following is a sample port loopback with MAC swap configuration output on the remote end.
The following is a sample testhead profile configuration output.
The following command is used to execute the testhead profile.
3.7. OAM Performance Monitoring (OAM-PM)
OAM-PM provides an architecture for gathering and computing key performance indicators (KPIs) using standard protocols and a robust collection model. The architecture is comprised of the following foundational components:
- sessionThe session is the overall collection of different tests, test parameters, measurement intervals, and mappings to configured storage models. It is the overall container that defines the attributes of the session.
- standard PM packetsStandard PM packets are the protocols defined by various standards bodies which contains the necessary fields to collect statistical data for the performance attribute they represent. OAM-PM leverages single-ended protocols. Single-ended protocols typically follow a message response model, message sent by a launch point, response updated and reflected by a responder.
- measurement intervals (MI)MI are time-based non-overlapping windows that capture all results that are received in that window of time.
- data structuresData structures are the unique counters and measurement results that represent the specific protocol.
- bin groupBin groups are ranges in microseconds that count the results that fit into the range.
The following figure shows the hierarchy of the architecture. This diagram is only meant to show the relationship between the components. It is not meant to depict all details of the required parameters.
Figure 28: OAM-PM architecture hierarchy

OAM-PM configurations are not dynamic environments. All aspects of the architecture must be carefully considered before configuring the various architectural components, making external references to other related components, or activating the OAM-PM architecture. No modifications are allowed to any components that are active or have any active sub-components. Any function being referenced by an active OAM-PM function or test cannot be modified or shut down. For example, to change any configuration element of a session, all active tests must be in a shutdown state. To change any bin group configuration (described later in this section) all sessions that reference the bin group must have every test shutdown. The description parameter is the only exception to this rule.
Session source and destination configuration parameters are not validated by the test that makes use of that information. When the test is activated with a no shutdown command, the test engine will attempt to send the test packets even if the session source and destination information does not accurately represent the entity that must exist to successfully transmit packets. If the entity does not exist, the transmit count for the test will be zero.
OAM-PM is not a hitless operation. If a high availability event occurs that causes the backup CPM to become the active CPM, or when ISSU functions are performed, the test data will not be correctly reported. There is no synchronization of state between the active and the backup control modules. All OAM-PM statistics stored in volatile memory will be lost. When the reload or high availability event is completed and all services are operational then the OAM-PM functions will commence.
It is possible that during times of network convergence, high CPU utilizations, or contention for resources, OAM-PM may not be able to detect changes to an egress connection or allocate the necessary resources to perform its tasks.
3.7.1. Session
This is the overall collection of different tests, the test parameters, measurement intervals, and mapping to configured storage models. It is the overall container that defines the attributes of the session:
- session typeA session type is the impetus of the test, which is either proactive (default) or on-demand. Individual test timing parameters are influenced by this setting. A proactive session will start immediately following the execution of a no shutdown command for the test. A proactive test will continue to execute until a manual shutdown stops the individual test. On-demand tests will also start immediately following the no shutdown command. However, the operator can override the no test-duration default and configure a fixed amount of time that the test will execute, up to 24 hours (86400 seconds). If an on-demand test is configured with a test-duration, it is important to shut down tests when they are completed. In the event of a high availability event causing the backup CPM to become the active CPM, all on-demand tests that have a test-duration statement will restart and run for the configured amount of time regardless of their progress on the previously active CPM.
- test familyThe test family is the main branch of testing that addresses a specific technology. The available test for the session are based on the test family. The destination, source, and priority are common to all tests under the session and are defined separately from the individual test parameters.
- test parametersTest parameters are the parameters included in individual tests, as well as the associated parameters including start and stop times and the ability to activate and deactivate the individual test.
- measurement intervalA measurement interval is the assignment of collection windows to the session with the appropriate configuration parameters and accounting policy for that specific session.
The session can be viewed as the single container that brings all aspects of individual tests and the various OAM-PM components under a single umbrella. If any aspects of the session are incomplete, the individual test cannot be activated with a no shutdown command, and an "Invalid ethernet session parameters" error will occur.
3.7.2. Standard PM packets
A number of standards bodies define performance monitoring packets that can be sent from a source, processed, and responded to by a reflector. The protocols available to carry out the measurements are based on the test family type configured for the session.
Ethernet PM delay measurements are carried out using the Two Way Delay Measurement Protocol version 1 (DMMv1) defined in Y.1731 by the ITU-T. This allows for the collection of Frame Delay (FD), InterFrame Delay Variation (IFDV), Frame Delay Range (FDR), and Mean Frame Delay (MFD) measurements for round trip, forward, and backward directions.
DMMv1 adds the following to the original DMM definition:
- the Flag Field (1 bit – LSB) is defined as the Type (Proactive=1 | On-Demand=0)
- the TestID TLV (32 bits) is carried in the Optional TLV portion of the PDU
DMMv1 and DMM are backwards compatible and the interaction is defined in Y.1731 ITU-T-2011 Section 11 "OAM PDU validation and versioning".
Ethernet PM loss measurements are carried out using Synthetic Loss Measurement (SLM), which is defined in Y.1731 by the ITU-T. This allows for the calculation of Frame Loss Ratio (FLR) and availability.
A session can be configured with one or more tests. Depending on the session test type family, one or more test configurations may need to be included in the session to gather both delay and loss performance information. Each test that is configured shares the common session parameters and the common measurement intervals. However, each test can be configured with unique per-test parameters. Using Ethernet as an example, both DMM and SLM would be required to capture both delay and loss performance data.
Each test must be configured with a TestID as part of the test parameters, which uniquely identifies the test within the specific protocol. A TestID must be unique within the same test protocol. Again using Ethernet as an example, DMM and SLM tests within the same session can use the same TestID because they are different protocols. However, if a TestID is applied to a test protocol (like DMM or SLM) in any session, it cannot be used for the same protocol in any other session. When a TestID is carried in the protocol, as it is with DMM and SLM, this value does not have global significance. When a responding entity must index for the purpose of maintaining sequence numbers, as in the case of SLM, the TestID, Source MAC, and Destination MAC are used to maintain the uniqueness of the responder. This means that the TestID has only local, and not global, significance.
3.7.3. Measurement intervals
A measurement interval is a window of time that compartmentalizes the gathered measurements for an individual test that have occurred during that time. Allocation of measurement intervals, which equates to system memory, is based on the metrics being collected. This means that when both delay and loss metrics are being collected, they allocate their own set of measurement intervals. If the operator is executing multiple delay and loss tests under a single session, then multiple measurement intervals will be allocated, with one interval allocated per criteria per test.
Measurement intervals can be 15 minutes (15-min), one hour (1-hour) and 1 day (1-day) in duration. The boundary-type defines the start of the measurement interval and can be aligned to the local time of day clock, with or without an optional offset. The boundary-type can be aligned using the test-aligned option, which means that the start of the measurement interval coincides with the activation of the test. By default the start boundary is clock-aligned without an offset. When this configuration is deployed, the measurement interval will start at zero, in relation to the length. When a boundary is clock-aligned and an offset is configured, the specified amount of time will be applied to the measurement interval. Offsets are configured on a per-measurement interval basis and only applicable to clock-aligned measurement intervals. Only offsets less than the measurement interval duration are allowed. The following table describes some examples of the start times of each measurement interval.
Table 20: Measurement interval start times
Offset | 15-min | 1-hour | 1-day |
0 (default) | 00, 15, 30, 45 | 00 (top of the hour) | midnight |
10 minutes | 10, 25, 40, 55 | 10 min after the hour | 10 min after midnight |
30 minutes | rejected | 30 min after the hour | 30 min after midnight |
60 minutes | rejected | rejected | 01:00 AM |
Although test-aligned approaches may seem beneficial for simplicity, there are some drawbacks that need to be considered. The goal of the time-based and well defined collection windows allows for the comparison of measurements across common windows of time throughout the network and for relating different tests or sessions. It is suggested that proactive sessions use the default clock-aligned boundary type. On-demand sessions may make use of test-aligned boundaries. On-demand tests are typically used for troubleshooting or short term monitoring that does not require alignment or comparison to other PM data.
The statistical data collected and the computed results from each measurement interval are maintained in volatile system memory by default. The number of intervals stored is configurable per measurement interval. Different measurement intervals will have different defaults and ranges. The interval-stored parameter defines the number of completed individual test runs to store in volatile memory. There is an additional allocation to account for the active measurement interval. To look at the statistical information for the individual tests and a specific measurement interval stored in volatile memory, the show oam-pm statistics … interval-number command can be used. If there is an active test, it can be viewed by using the interval number 1. In this case, the first completed record would be interval number 2, and previously completed records would increment up to the maximum intervals stored value plus one.
As new tests for the measurement interval are completed, the older entries are renumbered to maintain their relative position to the current test. If the retained test data for a measurement interval consumes the final entry, any subsequent entries cause the removal of the oldest data.
There are drawbacks to this storage model. Any high availability function that causes an active CPM switch will flush the results that are in volatile memory. Another consideration is the large amount of system memory consumed using this type of model. With the risks and resource consumption this model incurs, an alternate method of storage is supported.
An accounting policy can be applied to each measurement interval to write the completed data in system memory to non-volatile flash memory in an XML format. The amount of system memory consumed by historically completed test data must be balanced with an appropriate accounting policy. Nokia recommends that only necessary data be stored in non-volatile memory to avoid unacceptable risk and unnecessary resource consumption. It is further suggested that a large overlap between the data written to flash memory and stored in volatile memory is unnecessary.
The statistical information in system memory is also available through SNMP. If this method is chosen, a balance must be struck between the intervals retained and the times at which the SNMP queries collect the data. Determining the collection times through SNMP must be done with caution. If a file is completed while another file is being retrieved through SNMP, then the indexing will change to maintain the relative position to the current run. Correct spacing of the collection is key to ensuring data integrity.
The OAM-PM XML file contains the keywords and MIB references described in the following table.
Table 21: OAM-PM XML keywords and MIB reference
XML file keyword | Description | TIMETRA-OAM-PM-MIB object |
oampm | — | None - header only |
Keywords shared by all OAM-PM protocols | ||
sna | OAM-PM session name | tmnxOamPmCfgSessName |
mi | Measurement interval record | None - header only |
dur | Measurement interval duration (minutes) | tmnxOamPmCfgMeasIntvlDuration (enumerated) |
ivl | Measurement interval number | tmnxOamPmStsIntvlNum |
sta | Start timestamp | tmnxOamPmStsBaseStartTime |
ela | Elapsed time (seconds) | tmnxOamPmStsBaseElapsedTime |
ftx | Frames sent | tmnxOamPmStsBaseTestFramesTx |
frx | Frames received | tmnxOamPmStsBaseTestFramesRx |
sus | Suspect flag | tmnxOamPmStsBaseSuspect |
dmm | Delay record | None - header only |
mdr | Minimum frame delay, round-trip | tmnxOamPmStsDelayDmm2wyMin |
xdr | Maximum frame delay, round-trip | tmnxOamPmStsDelayDmm2wyMax |
adr | Average frame delay, round-trip | tmnxOamPmStsDelayDmm2wyAvg |
mdf | Minimum frame delay, forward | tmnxOamPmStsDelayDmmFwdMin |
xdf | Maximum frame delay, forward | tmnxOamPmStsDelayDmmFwdMax |
adf | Average frame delay, forward | tmnxOamPmStsDelayDmmFwdAvg |
mdb | Minimum frame delay, backward | tmnxOamPmStsDelayDmmBwdMin |
xdb | Maximum frame delay, backward | tmnxOamPmStsDelayDmmBwdMax |
adb | Average frame delay, backward | tmnxOamPmStsDelayDmmBwdAvg |
mvr | Minimum inter-frame delay variation, round-trip | tmnxOamPmStsDelayDmm2wyMin |
xvr | Maximum inter-frame delay variation, round-trip | tmnxOamPmStsDelayDmm2wyMax |
avr | Average inter-frame delay variation, round-trip | tmnxOamPmStsDelayDmm2wyAvg |
mvf | Minimum inter-frame delay variation, forward | tmnxOamPmStsDelayDmmFwdMin |
xvf | Maximum inter-frame delay variation, forward | tmnxOamPmStsDelayDmmFwdMax |
avf | Average inter-frame delay variation, forward | tmnxOamPmStsDelayDmmFwdAvg |
mvb | Minimum inter-frame delay variation, backward | tmnxOamPmStsDelayDmmBwdMin |
xvb | Maximum inter-frame delay variation, backward | tmnxOamPmStsDelayDmmBwdMax |
avb | Average inter-frame delay variation, backward | tmnxOamPmStsDelayDmmBwdAvg |
mrr | Minimum frame delay range, round-trip | tmnxOamPmStsDelayDmm2wyMin |
xrr | Maximum frame delay range, round-trip | tmnxOamPmStsDelayDmm2wyMax |
arr | Average frame delay range, round-trip | tmnxOamPmStsDelayDmm2wyAvg |
mrf | Minimum frame delay range, forward | tmnxOamPmStsDelayDmmFwdMin |
xrf | Maximum frame delay range, forward | tmnxOamPmStsDelayDmmFwdMax |
arf | Average frame delay range, forward | tmnxOamPmStsDelayDmmFwdAvg |
mrb | Minimum frame delay range, backward | tmnxOamPmStsDelayDmmBwdMin |
xrb | Maximum frame delay range, backward | tmnxOamPmStsDelayDmmBwdMax |
arb | Average frame delay range, backward | tmnxOamPmStsDelayDmmBwdAvg |
fdr | Frame delay bin record, round-trip | None - header only |
fdf | Frame delay bin record, forward | None - header only |
fdb | Frame delay bin record, backward | None - header only |
fvr | Inter-frame delay variation bin record, round-trip | None - header only |
fvf | Inter-frame delay variation bin record, forward | None - header only |
fvb | Inter-frame delay variation bin record, backward | None - header only |
frr | Frame delay range bin record, round-trip | None - header only |
frf | Frame delay range bin record, forward | None - header only |
frb | Frame delay range bin record, backward | None - header only |
lbo | Configured lower bound of the bin | tmnxOamPmCfgBinLowerBound |
cnt | Number of measurements within the configured delay range Note: The session_name, interval_duration, interval_number, {fd, fdr, ifdv}, bin_number, and {forward, backward, round-trip} indices are provided by the surrounding XML context | tmnxOamPmStsDelayDmmBinFwdCount tmnxOamPmStsDelayDmmBinBwdCount tmnxOamPmStsDelayDmmBin2wyCount |
slm | Synthetic loss measurement record | None - header only |
txf | Transmitted frames in the forward direction | tmnxOamPmStsLossSlmTxFwd |
rxf | Received frames in the forward direction | tmnxOamPmStsLossSlmRxFwd |
txb | Transmitted frames in the backward direction | tmnxOamPmStsLossSlmTxBwd |
rxb | Received frames in the backward direction | tmnxOamPmStsLossSlmRxBwd |
avf | Available count in the forward direction | tmnxOamPmStsLossSlmAvailIndFwd |
avb | Available count in the forward direction | tmnxOamPmStsLossSlmAvailIndBwd |
uvf | Unavailable count in the forward direction | tmnxOamPmStsLossSlmUnavlIndFwd |
uvb | Unavailable count in the forward direction | tmnxOamPmStsLossSlmUnavlIndBwd |
uaf | Undetermined available count in the forward direction | tmnxOamPmStsLossSlmUndtAvlFwd |
uab | Undetermined available count in the backward direction | tmnxOamPmStsLossSlmUndtAvlBwd |
uuf | Undetermined unavailable count in the forward direction | tmnxOamPmStsLossSlmUndtUnavlFwd |
uub | Undetermined unavailable count in the backward direction | tmnxOamPmStsLossSlmUndtUnavlBwd |
hlf | Count of HLIs in the forward direction | tmnxOamPmStsLossSlmHliFwd |
hlb | Count of HLIs in the backward direction | tmnxOamPmStsLossSlmHliBwd |
chf | Count of CHLIs in the forward direction | tmnxOamPmStsLossSlmChliFwd |
chb | Count of CHLIs in the backward direction | tmnxOamPmStsLossSlmChliBwd |
mff | Minimum FLR in the forward direction | tmnxOamPmStsLossSlmMinFlrFwd |
xff | Maximum FLR in the forward direction | tmnxOamPmStsLossSlmMaxFlrFwd |
aff | Average FLR in the forward direction | tmnxOamPmStsLossSlmAvgFlrFwd |
mfb | Minimum FLR in the backward direction | tmnxOamPmStsLossSlmMinFlrBwd |
xfb | Maximum FLR in the backward direction | tmnxOamPmStsLossSlmMaxFlrBwd |
afb | Average FLR in the backward direction | tmnxOamPmStsLossSlmAvgFlrBwd |
By default, the 15-min measurement interval stores 33 test runs (32+1) with a configurable range of 1 to 96, and the 1-hour measurement interval stores 9 test runs (8+1) with a configurable range of 1 to 24. The only storage for the 1-day measurement interval is 2 (1+1). This value for the 1-day measurement interval cannot be changed.
All three measurement intervals may be added to a single session if required. Each measurement interval that is included in a session is updated simultaneously for each test that is executing. If a measurement interval length is not required, it should not be configured. In addition to the three predetermined length measurement intervals, a fourth “always on” raw measurement interval is allocated at test creation. Data collection for the raw measurement interval commences immediately following the execution of a no shutdown command. It is a valuable tool for assisting in real-time troubleshooting as it maintains the same performance information and relates to the same bins as the fixed length collection windows. The operator may clear the contents of the raw measurement interval and flush stale statistical data to look at current conditions. This measurement interval has no configuration options, cannot be written to flash memory, and cannot be disabled; It is a single never-ending window.
Memory allocation for the measurement intervals is performed when the test is configured. Volatile memory is not flushed until the test is deleted from the configuration, a high availability event causes the backup CPM to become the newly active CPM, or some other event clears the active CPM system memory. Shutting down a test does not release the allocated memory for the test.
Measurement intervals also include a suspect flag. The suspect flag is used to indicate that data collected in the measurement interval may not be representative. The flag will be set to true only under the following conditions:
- Time of day clock is adjusted by more than 10 seconds.
- Test start does not align with the start boundary of the measurement interval. This would be common for the first execution for clock aligned tests.
- Test stopped before the end of the measurement interval boundary
The suspect flag is not set when there are times of service disruption, maintenance windows, discontinuity, low packet counts, or other such events. Higher level systems would be required to interpret and correlate those types of event for measurement intervals which executed during the time that relate to the specific interruption or condition. Since each measurement interval contains a start and stop time, the information is readily available for higher level systems to discount the specific windows of time.
3.7.4. Data structures and storage
There are two main metrics that are the focus of OAM-PM: delay and loss. The different metrics have two unique storage structures and will allocate their own measurement intervals for these structures. This occurs regardless of whether the performance data is gathered with a single packet or multiple packet types.
Delay metrics include Frame Delay (FD), InterFrame Delay Variation (IFDV), Frame Delay Range (FDR) and Mean Frame Delay (MFD). Unidirectional and round trip results are stored for each metric:
- Frame DelayThe Frame Delay is the amount of time required to send and receive the packet.
- InterFrame Delay VariationIFDV is the difference in the delay metrics between two adjacent packets.
- Frame Delay RangeThe Frame Delay Range is the difference between the minimum frame delay and the individual packet
- Mean Frame DelayThe Mean Frame Delay is the mathematical average for the frame delay over the entire window.
FD, IFDV and FDR statistics are binnable results. FD, IFDV, FDR and MFD all include minimum, maximum, and average values. Unidirectional and round trip results are stored for each metric.
Unidirectional frame delay and frame delay range measurements require exceptional time of day clock synchronization. If the time of day clock does not exhibit extremely tight synchronization, unidirectional measurements will not be representative. In one direction, the measurement will be artificially increased by the difference in the clocks. In the other direction, the measurement will be artificially decreased by the difference in the clocks. This level of clocking accuracy is not available with NTP. To achieve this level of time of day clock synchronization, Precision Time Protocol (PTP) 1588v2 should be considered.
Round trip metrics do not require clock synchronization between peers, since the four timestamps allow for accurate representation of the round trip delay. The mathematical computation removes remote processing and any difference in time of day clocking. Round trip measurements do require stable local time of day clocks.
Any delay metric that is negative will be treated as zero and placed in bin 0, the lowest bin which has a lower boundary of 0 microseconds.
Delay results are mapped to the measurement interval that is active when the result arrives back at the source.
There are no supported log events based on delay metrics.
Loss metrics are only unidirectional and will report frame loss ratio (FLR) and availability information. Frame loss ratio is the computation of loss (lost/sent) over time. Loss measurements during periods of unavailability are not included in the FLR calculation as they are counted against the unavailability metric.
Availability requires relating three different functions. First, the individual probes are marked as available or unavailable based on sequence numbers in the protocol. A number of probes are rolled up into a small measurement window, typically 1 s. Frame loss ratio is computed over all the probes in a small window. If the resulting percentage is higher than the configured threshold, the small window is marked as unavailable. If the resulting percentage is lower than the threshold, the small window is marked as available. A sliding window is defined as some number of small windows, typically 10. The sliding window is used to determine availability and unavailability events. Switching from one state to the other requires every small window in the sliding window to be the same state and different from the current state.
Availability and unavailability counters are incremented based on the number of small windows that have occurred in all available and unavailable windows.
Availability and unavailability using synthetic loss measurements is meant to capture the loss behavior for the service. It is not meant to capture and report on service outages or communication failures. Communication failures of a bidirectional or unidirectional nature must be captured using some other means of connectivity verification, alarming, or continuity checking. During times of complete or extended failure periods it becomes necessary to timeout individual test probes. It is not possible to determine the direction of the loss because no response packets are being received back on the source. In this case, the statistics calculation engine maintains the previous state, updating the appropriate directional availability or unavailability counter. At the same time, an additional per-direction undetermined counter is updated. This undetermined counter is used to indicate that the availability or unavailability statistics could not be determined for a number of small windows.
During connectivity outages, the higher level systems can be used to discount the loss measurement interval, which covers the same span as the outage.
Availability and unavailability computations may delay the completion of a measurement interval. The declaration of a state change or the delay to a closing a measurement interval could be equal to the length of the sliding window and the timeout of the last packet. Closing of a measurement interval cannot occur until the sliding window has determined availability or unavailability. If the availability state is changing and the determination is crossing two measurement intervals, the measurement interval will not complete until the declaration has occurred. Typically, standard bodies indicate the timeout per packet. In the case of Ethernet, DMMv1, and SLM, timeout values are set at 5 s and cannot be configured.
There are no log events based on availability or unavailability state changes.
During times of availability, there can be times of high loss intervals (HLI) or consecutive high loss intervals (CHLI). These are indicators that the service was available but individual small windows or consecutive small windows experienced frame loss ratios exceeding the configured acceptable limit. A HLI is any single small window that exceeds the configured frame loss ratio. This could equate to a severely errored second, assuming the small window is one second. A CHIL is a consecutive high loss interval that exceeds a consecutive threshold within the sliding window. Only one HLI will be counted for a window.
Availability can only be reasonably determined with synthetic packets. This is because the synthetic packet is the packet being counted and provides a uniform packet flow that can be used for the computation. Transmit and receive counter-based approaches cannot reliably be used to determine availability because there is no guarantee that service data is on the wire, or the service data on the wire uniformity could make it difficult to make a declaration valid.
The following figure shows loss in a single direction using synthetic packets, and demonstrates what happens when a possible unavailability event crosses a measurement interval boundary. In the diagram, the first 13 small windows are all marked available (1), which means that the loss probes that fit into each of those small windows did not equal or exceed a frame loss ratio of 50%. The next 11 small windows are marked as unavailable, which means that the loss probes that fit into each of those small windows were equal to or above a frame loss ratio of 50%. After the 10th consecutive small window of unavailability, the state transitions from available to unavailable. The 25th small window is the start of the new available state which is declared following the 10th consecutive available small window. Notice that the frame loss ratio is 00.00%; this is because all the small windows that are marked as unavailable are counted toward unavailability, and as such are excluded from impacting the FLR. If there were any small windows of unavailability that were outside of an unavailability event, they would be marked as HLI or CHLI and be counted as part of the frame loss ratio.
Figure 29: Evaluating and computing loss and availability
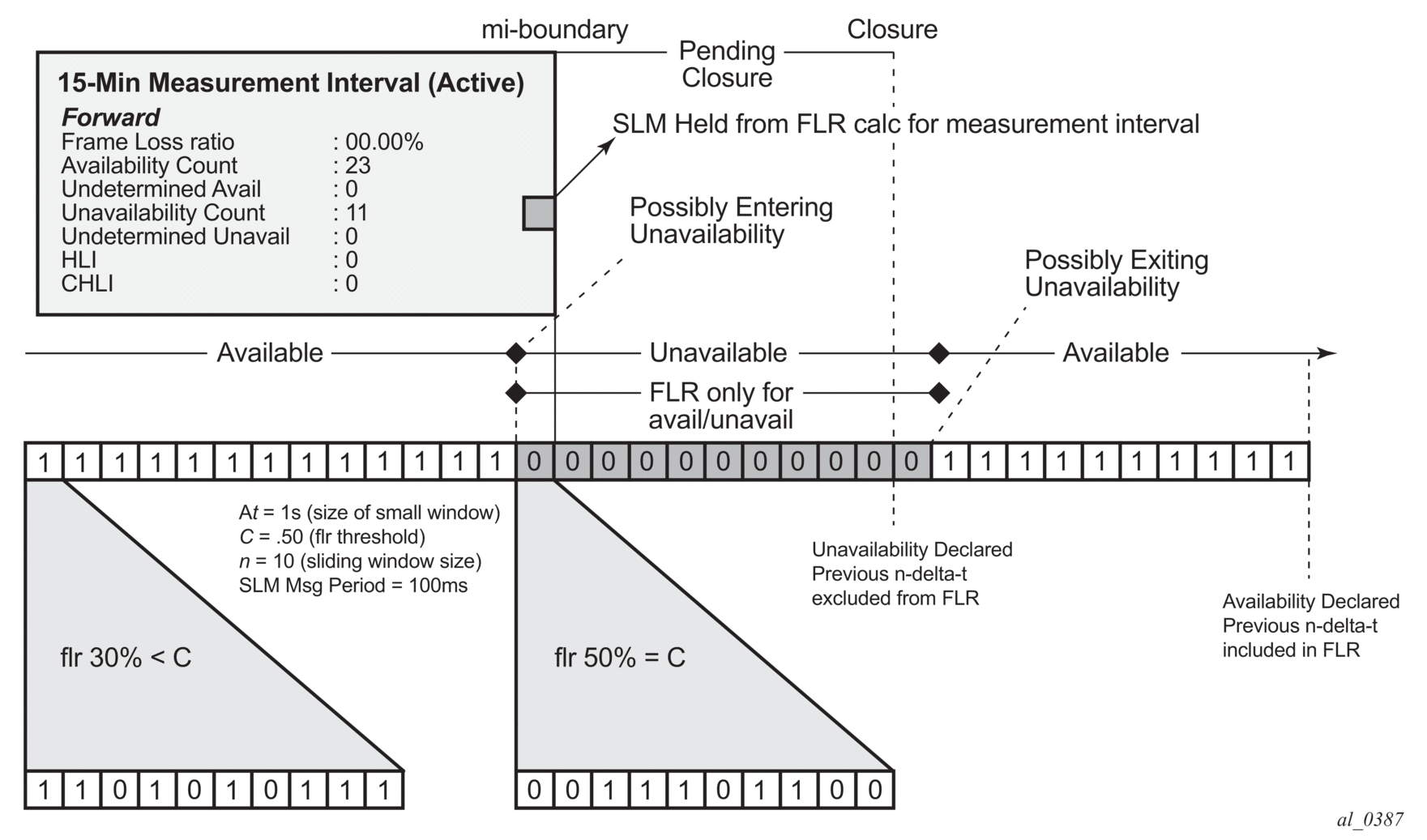
3.7.5. Bin groups
Bin groups are templates that are referenced by the session. Three types of binnable statistics are available: FD, IFDV, and FDR, all of which are available in forward, backward, and round trip directions. Each of these metrics can have up to ten bin groups configured to group the results. Bin groups are configured by indicating a lower boundary. Bin 0 has a lower boundary that is always zero and is not configurable. The microsecond range of the bins is the difference between the adjacent lower boundaries. For example, bin-type fd bin 1 configured with lower-bound 1000 means that bin 0 will capture all frame delay statistics results between 0 and 1 ms. Bin 1 will capture all results above 1 ms and below the bin 2 lower boundary. The last bin to be configured would represent the bin that collects all the results at and above that value. Not all ten bins must be configured.
Each binnable delay metric type requires their own values for the bin groups. Each bin in a type is configurable for one value. It is not possible to configure a bin with different values for round trip, forward, and backward. Consideration must be given to the configuration of the boundaries that represent the important statistics for that specific service.
As stated earlier in this section, this is not a dynamic environment. If a bin group is being referenced by any active test the bin group cannot shutdown. To modify the bin group it must be shut down. If the configuration of a bin group must be changed, and a large number of sessions are referencing the bin group, migrating existing sessions to a new bin group with the new parameters can be considered to reduce the maintenance window. To modify any session parameter, every test in the session must be shut down.
Bin group 1 is the default bin group. Every session requires a bin group to be assigned. By default, bin group 1 is assigned to every OAM-PM session that does not have a bin group explicitly configured. Bin group 1 cannot be modified. The bin group 1 configuration parameters are as follows:
3.7.6. Relating the components
The following figure shows the architecture of all of the OAM-PM concepts previously described. It shows a more detailed hierarchy than previously shown in the introduction. This shows the relationship between the tests, the measurement intervals, and the storage of the results.
Figure 30: Relating OAM-PM components
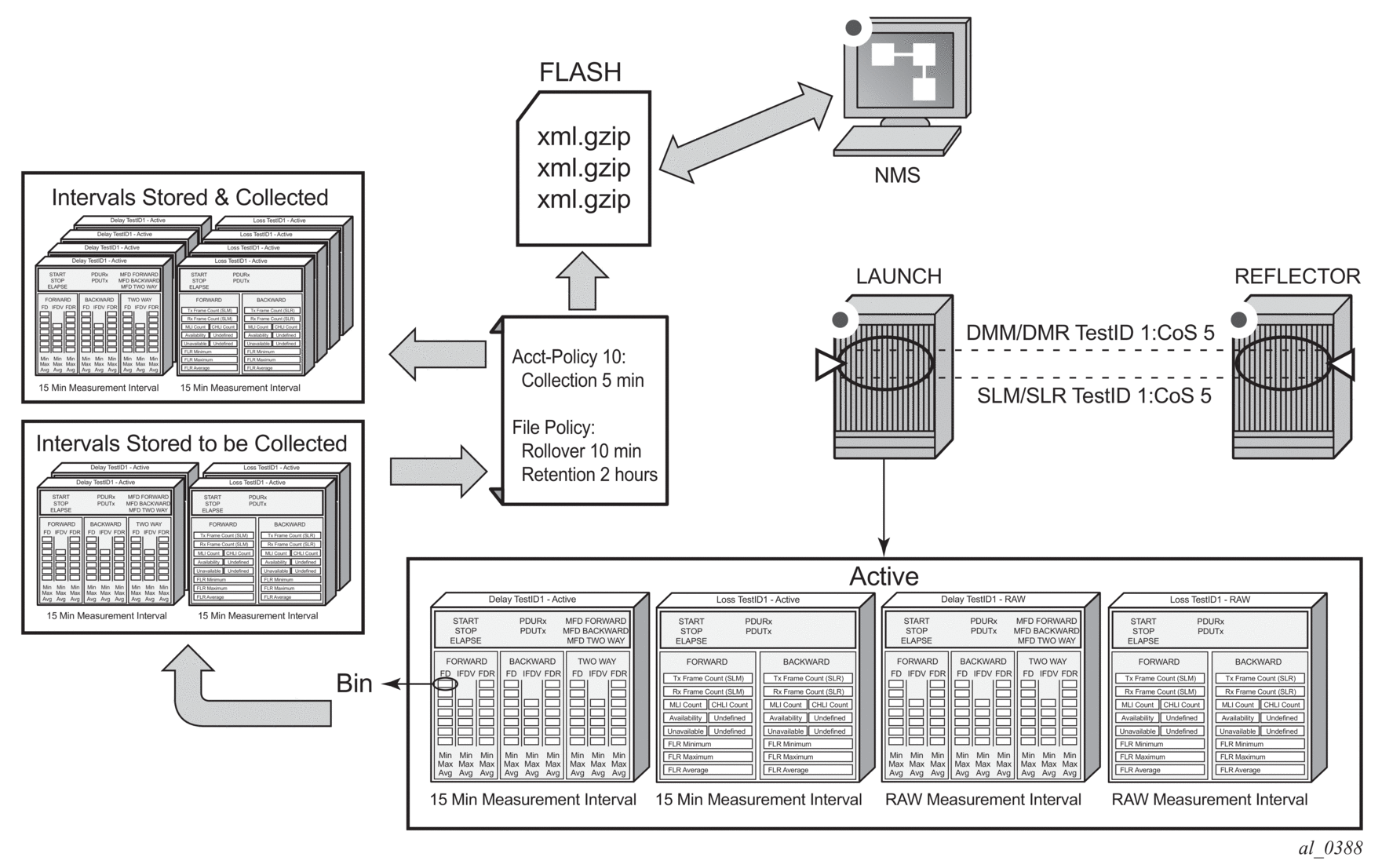
3.7.7. Monitoring
The following configuration examples are used to demonstrate the different show and monitoring commands available to check OAM-PM.
3.7.7.1. Accounting policy configuration
3.7.7.2. ETH-CFM configuration
3.7.7.3. Service configuration
3.7.7.4. OAM-PM configuration
3.7.7.5. Show and monitor commands
The monitor command can be used to automatically update the statistics for the raw measurement interval.