2. IP Router Configuration
2.1. Configuring IP Router Parameters
To provision services on a Nokia router, logical IP routing interfaces must be configured to associate attributes such as an IP address, port, or the system with the IP interface.
A special type of IP interface is the system interface. A system interface must have an IP address with a 32-bit subnet mask. The system interface is used as the router identifier by higher-level protocols such as OSPF and BGP, unless overwritten by an explicit router ID.
The following router features can be configured:
Refer to the 7450 ESS, 7750 SR, and VSR Triple Play Service Delivery Architecture Guide for information about DHCP and support as well as configuration examples for the 7750 SR and 7450 ESS.
2.1.1. Interfaces
Nokia routers use different types of interfaces for various functions. Interfaces must be configured with parameters such as the interface type (network and system) and address. A port is not associated with a system interface. An interface can be associated with the system (loopback address).
2.1.1.1. Network Interface
A network interface (a logical IP routing interface) can be configured on one of the following entities:
- Physical or logical port
- A SONET/SDH channel for the 7750 SR or 7450 ESS
2.1.1.2. Network Domains
To determine which network ports (and, therefore, which network complexes) are eligible to transport traffic of individual SDPs, network-domain is provided. Network-domain information is then used for the sap-ingress queue allocation algorithm applied to VPLS SAPs. This algorithm is optimized in so that no sap-ingress queues are allocated if the specified port does not belong to the network-domain used in the specified VPLS. Also, sap-ingress queues will not be allocated toward network ports (regardless of the network-domain membership) if the specified VPLS does not contain any SDPs.
Sap-ingress queue allocation considers the following:
- SHG membership of individual SDPs
- Network-domain definition under SDP to restrict the topology in which the specified SDP can be set-up
The implementation supports four network-domains within any VPLS.
Network-domain configuration at the SDP level is ignored when the SDP is used for Epipe, Ipipe, or Apipe bindings.
Network-domain configuration is irrelevant for Layer 3 services (Layer 3 VPN and/or IES service). Network-domain configuration can be defined in the base routing context and associated only with network interfaces in this context. Network domains are not applicable to loopback and system interfaces.
The network-domain information will only be used for ingress VPLS sap queue-allocation. It will not be considered by routing during SDP setup. Therefore, if the specified SDP is routed through network interfaces that are not part of the configured network domain, the packets will be still forwarded, but their QoS and queuing behavior will be based on default settings. Also, the packet will not appear in SAP statistics.
There will always be one network-domain with reserved name default. The interfaces will always belong to a default network-domain. It will be possible to assign a specific interface to different user-defined network-domains. The loopback and system interfaces will be also associated with the default network-domain at the creation. However, any attempt to associate those interfaces with any explicitly defined network-domain will be blocked at the CLI level because there is no benefit for that association.
Any SDP can be assigned only to one network domain. If none is specified, the system will assign the default network-domain. This means that all SAPs in VPLS will have queue reaching all fwd-complexes serving interfaces that belong to the same network-domains as the SDPs.
It is possible to assign/remove network-domain association of the interface/SDP without requiring deletion of the respective object.
2.1.1.3. System Interface
The system interface is associated with a network entity (such as a specific router or switch), not a specific interface. The system interface is also referred to as the loopback address. The system interface is associated during the configuration of the following entities:
- Termination point of service tunnels
- Hops when configuring MPLS paths and LSPs
- Addresses on a target router for BGP and LDP peering
The system interface is used to preserve connectivity (when routing reconvergence is possible) when an interface fails or is removed. The system interface is used as the router identifier, and a system interface must have an IP address with a 32-bit subnet mask.
2.1.1.4. Unicast Reverse Path Forwarding Check (uRPF)
uRPF helps to mitigate problems that are caused by the introduction of malformed or forged (spoofed) IP source addresses into a network by discarding IP packets that lack a verifiable IP source address. For example, a number of common types of denial-of-service (DoS) attacks, including smurf and tribe flood network (TFN), can take advantage of forged or rapidly changing source addresses to allow attackers to thwart efforts to locate or filter the attacks. For Internet service providers (ISPs) that provide public access, uRPF deflects such attacks by forwarding only packets with source addresses that are valid and consistent with the IP routing table. This action protects the network of the ISP, its customer, and the rest of the Internet.
uRPF is supported for both IPv4 and IPv6 on network and access. It is supported on any IP interface, including base router, IES, VPRN, and subscriber group interfaces.
In strict mode, uRPF checks whether the incoming packet has a source address that matches a prefix in the routing table, and whether the interface expects to receive a packet with this source address prefix.
In loose mode, uRPF checks whether the incoming packet has a source address that matches a prefix in the routing table; loose mode does not check whether the interface expects to receive a packet with a specific source address prefix.
Loose mode uRPF check is supported for ECMP, IGP shortcuts, and VPRN MP-BGP routes. Packets coming from a source that matches any ECMP, IGP shortcut, or VPRN MP-BGP route will pass the uRPF check even when uRPF is set to strict mode on the incoming interface.
In the case of ECMP, this allows a packet received on an IP interface configured in strict uRPF mode to be forwarded if the source address of the packet matches an ECMP route, even if the IP interface is not a next-hop of the ECMP route or not a member of any ECMP routes. The strict-no-ecmp uRPF mode may be configured on any interface that is known to not be a next-hop of any ECMP route. When a packet is received on this interface, and the source address matches an ECMP route, the packet is dropped by uRPF.
If there is a default route, the following is included in the uRPF check:
- A loose mode uRPF check always succeeds.
- A strict mode uRPF check only succeeds if the source address matches any route (including the default route) where the next-hop is on the incoming interface for the packet.
Otherwise, the uRPF check fails.
If the source IP address matches a discard/blackhole route, the packet is treated as if it failed the uRPF check.
2.1.1.5. Creating an IP Address Range
An IP address range can be reserved for exclusive use for services by defining the config>router>service-prefix command. When the service is configured, the IP address must be in the range specified by a service prefix. If no service prefix is configured, no limitation exists.
Addresses in the range of a service prefix can be allocated to a network port unless the exclusive parameter is specified. Then, the address range is exclusively reserved for services.
When defining a range that is a superset of a previously defined service prefix, the subset will be replaced with the superset definition. For example, if a service prefix exists for 10.10.10.0/24, and a new service prefix is configured as 10.10.0.0/16, then the old address (10.10.10.0/24) will be replaced with the new address (10.10.0.0/16).
When defining a range that is a subset of a previously defined service prefix, the subset will replace the existing superset, providing that addresses used by services are not affected. For example, if a service prefix exists for 10.10.0.0/16, and a new service prefix is configured as 10.10.10.0/24, then the 10.10.0.0/16 address will be removed, provided that no services are configured that use 10.10.x.x addresses other than 10.10.10.x.
2.1.1.6. QoS Policy Propagation Using BGP (QPPB)
This section describes QPPB as it applies to VPRN, IES, and router interfaces. Refer to the “Internet Enhanced Service” section in the 7450 ESS, 7750 SR, 7950 XRS, and VSR Layer 3 Services Guide: IES and VPRN and the “IP Router Configuration” section in the 7450 ESS, 7750 SR, 7950 XRS, and VSR Router Configuration Guide.
QoS policy propagation using BGP (QPPB) is a feature that allows a route to be installed in the routing table with a forwarding-class and priority so that packets matching the route can receive the associated QoS. The forwarding-class and priority associated with a BGP route are set using BGP import route policies. This feature is called QPPB, even though the feature name refers to BGP specifically. On SR OS, QPPB is supported for BGP (IPv4, IPv6, VPN-IPv4, VPN-IPv6), RIP, and static routes.
SAP ingress and network QoS policies can achieve the same result as QPPB (for example, by assigning a packet arriving on an IP interface to a specific forwarding-class and priority/profile, based on the source address or destination address of the packet). However, the effort involved in creating the QoS policies, keeping them up-to-date, and applying them across many nodes is much greater than with QPPB. In a typical application of QPPB, a BGP route is advertised with a BGP community attribute that conveys a specific QoS. Routers that receive the advertisement accept the route into their routing table and set the forwarding-class and priority of the route from the community attribute.
2.1.1.6.1. QPPB Applications
There are two typical applications of QPPB:
- Coordination of QoS policies between different administrative domains
- Traffic differentiation within a single domain, based on route characteristics
2.1.1.6.2. Inter-AS Coordination of QoS Policies
The operator of an administrative domain “A” can use QPPB to signal to a peer administrative domain “B” that traffic sent to certain prefixes advertised by domain A should receive a specific QoS treatment in domain B. For example, an ASBR of domain A can advertise a prefix to domain B and include a BGP community attribute with the route. The community value implies a specific QoS treatment, as agreed by the two domains (in their peering agreement or service level agreement, for example). When the ASBR and other routers in domain B accept and install the route for that prefix into their routing table, they apply a QoS policy on selected interfaces that classifies traffic toward that prefix into the QoS class implied by the BGP community value.
QPPB may also be used to request that traffic sourced from specific networks receive appropriate QoS handling in downstream nodes that may span different administrative domains. This can be achieved by advertising the source prefix with a BGP community, as described. However, in this case, other approaches are equally valid, such as marking the DSCP or other CoS fields based on the source IP address, so that downstream domains can take action based on a common understanding of the QoS treatment implied by different DSCP values.
In the preceding examples, coordination of QoS policies using QPPB could be between a business customer and their IP VPN service provider, or between one service provider and another.
2.1.1.6.3. Traffic Differentiation Based on Route Characteristics
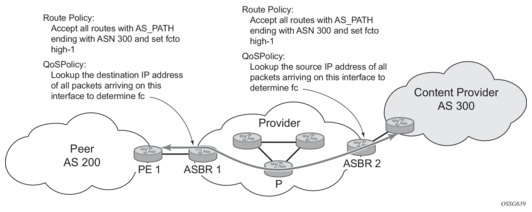
A network operator might need to provide differentiated service to specific traffic flows within its network, and these traffic flows can be identified with known routes. For example, the operator of an ISP network might need to give priority to traffic originating in a specific ASN (the ASN of a content provider offering over-the-top services to the ISP’s customers), following a specific AS_PATH, or destined for a specific next-hop (remaining on-net vs. off-net).
Figure 1 shows an example of an ISP that has an agreement with the content provider managing AS300 to provide traffic sourced and terminating within AS300 with differentiated service appropriate to the content being transported. In this example, ASBR1 and ASBR2 mark the DSCP of packets terminating and sourced, respectively, in AS300 so that other nodes within the ISP’s network do not need to rely on QPPB to determine the correct forwarding-class to use for the traffic. The DSCP or other CoS markings could be left unchanged in the ISP’s network and QPPB used on every node.
Figure 1: Use of QPPB to Differentiate Traffic in an ISP Network
2.1.1.7. QPPB
There are two main aspects of the QPPB feature:
- The ability to associate a forwarding-class and priority with specific routes in the routing table.
- The ability to classify an IP packet arriving on a specific IP interface to the forwarding-class and priority associated with the route that best matches the packet.
2.1.1.7.1. Associating an FC and Priority with a Route
This feature uses the fc command in the route-policy hierarchy to set the forwarding class and, optionally, the priority associated with routes accepted by a route-policy entry. The command has the following structure:
The use of the fc command is shown by the following example:
The fc command is supported with all existing from and to match conditions in a route policy entry, with any action other than reject, and with next-entry, next-policy, and accept actions. If a next-entry or next-policy action results in multiple matching entries, then the last entry with a QPPB action determines the forwarding class and priority.
A route policy that includes the fc command in one or more entries can be used in any import or export policy, but the fc command has no effect except in the following types of policies:
- VRF import policies:
- config>service>vprn>vrf-import
- BGP import policies:
- config>router>bgp>import
- config>router>bgp>group>import
- config>router>bgp>group>neighbor>import
- config>service>vprn>bgp>import
- config>service>vprn>bgp>group>import
- config>service>vprn>bgp>group>neighbor>import
- RIP import policies:
- config>router>rip>import
- config>router>rip>group>import
- config>router>rip>group>neighbor>import
- config>service>vprn>rip>import
- config>service>vprn>rip>group>import
- config>service>vprn>rip>group>neighbor>import
As shown, QPPB route policies support routes learned from RIP and BGP neighbors of a VPRN, as well as for routes learned from RIP and BGP neighbors of the base/global routing instance.
QPPB is supported for BGP routes belonging to any of the following address families:
- IPv4 (AFI=1, SAFI=1)
- IPv6 (AFI=2, SAFI=1)
- VPN-IPv4 (AFI=1, SAFI=128)
- VPN-IPv6 (AFI=2, SAFI=128)
A VPN-IP route may match both a VRF import policy entry and a BGP import policy entry (if vpn-apply-import is configured in the base router BGP instance). In this case, the VRF import policy is applied first, then the BGP import policy, so the QPPB QoS is based on the BGP import policy entry.
This feature also provides the ability to associate a forwarding-class and, optionally, priority with IPv4 and IPv6 static routes. This is achieved by specifying the forwarding-class within the static-route-entry next-hop or indirect context.
Priority is optional when specifying the forwarding class of a static route, but when configured it can only be deleted and returned to unspecified by deleting the entire static route.
2.1.1.7.2. Displaying QoS Information Associated with Routes
The following commands are enhanced to show the forwarding-class and priority associated with the displayed routes:
- show router route-table
- show router fib
- show router bgp routes
- show router rip database
- show router static-route
This feature uses a qos keyword with the show>router>route-table command. When this option is specified, the output includes an additional line per route entry that displays the forwarding class and priority of the route. If a route has no fc and priority information, the third line is blank. The following CLI shows an example:
show router route-table [family] [ip-prefix[/prefix-length]] [longer | exact] [protocol protocol-name] qos
An example output of this command is as follows:
2.1.1.7.3. Enabling QPPB on an IP interface
To enable QoS classification of ingress IP packets on an interface based on the QoS information associated with the routes that best match the packets, configure the qos-route-lookup command in the IP interface. The qos-route-lookup command has parameters to indicate whether the QoS result is based on lookup of the source or destination IP address in every packet. There are separate qos-route-lookup commands for the IPv4 and IPv6 packets on an interface, which allows QPPB to be enabled for IPv4 only, IPv6 only, or both IPv4 and IPv6. Currently, QPPB based on a source IP address is not supported for IPv6 packets or for ingress subscriber management traffic on a group interface.
The qos-route-lookup command is supported on the following types of IP interfaces:
- base router network interfaces (config>router>interface)
- VPRN SAP and spoke SDP interfaces (config>service>vprn>interface)
- VPRN group-interfaces (config>service>vprn>sub-if>grp-if)
- IES SAP and spoke SDP interfaces (config>service>ies>interface)
- IES group-interfaces (config>service>ies>sub-if>grp-if)
When the qos-route-lookup command with the destination parameter is applied to an IP interface and the destination address of an incoming IP packet matches a route with QoS information, the packet is classified to the fc and priority associated with that route. The command overrides the FC and priority/profile determined from the SAP ingress or network QoS policy associated with the IP interface (see section 5.7 for more information). If the destination address of the incoming packet matches a route with no QoS information, the fc and priority of the packet remain as determined by the sap-ingress or network qos policy.
Similarly, when the qos-route-lookup command with the source parameter is applied to an IP interface and the source address of an incoming IP packet matches a route with QoS information, the packet is classified to the FC and priority associated with that route. The command overrides the FC and priority/profile determined from the SAP ingress or network QoS policy associated with the IP interface. If the source address of the incoming packet matches a route with no QoS information, the FC and priority of the packet remain as determined by the SAP ingress or network QoS policy.
Currently, QPPB is not supported for ingress MPLS traffic on network interfaces or on CsC PE’-CE’ interfaces (config>service>vprn>nw-if).
| Note: QPPB based on a source IP address is not supported for ingress subscriber management traffic on a group interface. |
2.1.1.7.4. QPPB When Next-Hops are Resolved by QPPB Routes
In some cases (IP VPN inter-AS model C, Carrier Supporting Carrier, indirect static routes, and so on), an IPv4 or IPv6 packet may arrive on a QPPB-enabled interface and match a route A1 whose next-hop N1 is resolved by a route A2 with next-hop N2. Similarly, N2 is resolved by a route A3 with next-hop N3, and so on. The QPPB result is based only on the forwarding-class and priority of route A1. If A1 does not have a forwarding-class and priority association, the QoS classification is not based on QPPB, even if routes A2, A3, and so on, have forwarding-class and priority associations.
2.1.1.7.5. QPPB and Multiple Paths to a Destination
When ECMP is enabled, some routes may have multiple equal-cost next-hops in the forwarding table. When an IP packet matches such a route, the next-hop selection is typically based on a hash algorithm that tries to load balance traffic across all the next-hops while keeping all packets of a flow on the same path. The QPPB configuration model described in Associating an FC and Priority with a Route allows different QoS information to be associated with the different ECMP next-hops of a route. The forwarding-class and priority of a packet matching an ECMP route is based on the next-hop used to forward the packet.
When Edge PIC [1] is enabled, some BGP routes may have a backup next-hop in the forwarding table, as well as the one or more primary next-hops representing the equal-cost best paths allowed by the ECMP/multipath configuration. When an IP packet matches such a route, a reachable primary next-hop is selected (based on the hash result) but if all the primary next-hops are unreachable, the backup next-hop is used. The QPPB configuration model described in Associating an FC and Priority with a Route allows the forwarding-class and priority associated with the backup path to be different from the QoS characteristics of the equal-cost best paths. The forwarding class and priority of a packet forwarded on the backup path is based on the fc and priority of the backup route.
2.1.1.7.6. QPPB and Policy-Based Routing
When an IPv4 or IPv6 packet with destination address arrives on an interface with both QPPB and policy-based-routing enabled:
- There is no QPPB classification if the IP filter action redirects the packet to a directly connected interface, even if the destination address is matched by a route with a forwarding-class and priority.
- QPPB classification is based on the forwarding-class and priority of the route matching IP address Y if the IP filter action redirects the packet to the indirect next-hop IP address Y, even if the destination address is matched by a route with a forwarding-class and priority.
2.1.1.8. QPPB and GRT Lookup
Source-address based QPPB is not supported on any SAP or spoke SDP interface of a VPRN configured with the grt-lookup command.
2.1.1.8.1. QPPB Interaction with SAP Ingress QoS Policy
When QPPB is enabled on a SAP IP interface, the forwarding class of a packet may change from fc1 (the original fc determined by the SAP ingress QoS policy) to fc2, the new fc determined by QPPB. In the ingress datapath, SAP ingress QoS policies are applied in the first P chip and route lookup/QPPB occurs in the second P chip. This has the following implications:
- Ingress remarking (based on profile state) is always based on the original fc (fc1) and sub-class (if defined).
- The profile state of a SAP ingress packet that matches a QPPB route depends on the configuration of fc2 only. If the de-1-out-profile flag is enabled in fc2, and fc2 is not mapped to a priority mode queue, the packet will be marked out of profile if its DE bit = 1. If the profile state of fc2 is explicitly configured (in or out) and fc2 is not mapped to a priority mode queue, the packet is assigned this profile state. In both cases, there is no consideration of whether fc1 was mapped to a priority mode queue.
- The priority of a SAP ingress packet that matches a QPPB route depends on several factors. If the de-1-out-profile flag is enabled in fc2 and the DE bit is set in the packet, priority will be low regardless of the QPPB priority or fc2 mapping to profile mode queue, priority mode queue, or policer. If fc2 is associated with a profile mode queue, the packet priority will be based on the explicitly configured profile state of fc2 (in profile = high, out profile = low, undefined = high), regardless of the QPPB priority or fc1 configuration. If fc2 is associated with a priority mode queue or policer, the packet priority will be based on QPPB (unless DE=1). If no priority information is associated with the route, the packet priority will be based on the configuration of fc1. If fc1 mapped to a priority mode queue, the priority is based on DSCP/IP prec/802.1p. If fc1 mapped to a profile mode queue, the priority is based on the profile state of fc1.
Table 3 summarizes these interactions.
Table 3: QPPB Interactions with SAP Ingress QoS
Original FC object mapping | New FC object mapping | Profile | Priority (drop preference) | DE=1 override | In/out of profile marking |
Profile mode queue | Profile mode queue | From new base FC unless overridden by DE=1 | From QPPB, unless packet is marked in or out of profile in which case follows profile. Default: high priority. | From new base FC | From original FC and sub-class |
Priority mode queue | Priority mode queue | Ignored | If DE=1 override then low otherwise from QPPB. If no DEI or QPPB overrides then from original dot1p/exp/DSCP mapping or policy default. | From new base FC | From original FC and sub-class |
Policer | Policer | From new base FC unless overridden by DE=1 | If DE=1 override then low otherwise from QPPB. If no DEI or QPPB overrides then from original dot1p/exp/DSCP mapping or policy default. | From new base FC | From original FC and sub-class |
Priority mode queue | Policer | From new base FC unless overridden by DE=1 | If DE=1 override then low otherwise from QPPB. If no DEI or QPPB overrides then from original dot1p/exp/DSCP mapping or policy default. | From new base FC | From original FC and sub-class |
Policer | Priority mode queue | Ignored | If DE=1 override then low otherwise from QPPB. If no DEI or QPPB overrides then from original dot1p/exp/DSCP mapping or policy default. | From new base FC | From original FC and sub-class |
Profile mode queue | Priority mode queue | Ignored | If DE=1 override then low otherwise from QPPB. If no DEI or QPPB overrides then follows original FC’s profile mode rules. | From new base FC | From original FC and sub-class |
Priority mode queue | Profile mode queue | From new base FC unless overridden by DE=1 | From QPPB, unless packet is marked in or out of profile in which case follows profile. Default: high priority. | From new base FC | From original FC and sub-class |
Profile mode queue | Policer | From new base FC unless overridden by DE=1 | If DE=1 override then low otherwise from QPPB. If no DEI or QPPB overrides then follows original FC’s profile mode rules. | From new base FC | From original FC and sub-class |
Policer | Profile mode queue | From new base FC unless overridden by DE=1 | From QPPB, unless packet is marked in or out of profile in which case follows profile. Default: high priority. | From new base FC | From original FC and sub-class |
2.1.2. Router ID
The router ID, a 32-bit number, uniquely identifies the router within an autonomous system (AS) (see Autonomous Systems (AS)). In protocols such as OSPF, routing information is exchanged between areas—groups of networks that share routing information. It can be set to be the same as the loopback address. The router ID is used by both OSPF and BGP routing protocols in the routing table manager instance.
There are several ways to obtain the router ID. On each router, the router ID can be obtained in the following ways.
- Define the value in the config>router router-id context. The value becomes the router ID.
- Configure the system interface with an IP address in the config>router>interface ip-int-name context. If the router ID is not manually configured in the config>router router-id context, the system interface acts as the router ID.
- If neither the system interface or router ID are implicitly specified, the router ID is inherited from the last four bytes of the MAC address.
- The router can be obtained from the protocol level; for example, BGP.
2.1.3. Autonomous Systems (AS)
Networks can be grouped into areas. An area is a collection of network segments within an AS that have been administratively assigned to the same group. An area’s topology is concealed from the rest of the AS, which results in a significant reduction in routing traffic.
Routing in the AS takes place on two levels, depending on whether the source and destination of a packet reside in the same area (intra-area routing) or different areas (inter-area routing). In intra-area routing, the packet is routed solely on information obtained within the area; no routing information obtained from outside the area can be used. This protects intra-area routing from the injection of bad routing information.
Routers that belong to more than one area are called area border routers. All routers in an AS do not have an identical topological database. An area border router has a separate topological database for each area it is connected to. Two routers, which are not area border routers, belonging to the same area, have identical area topological databases.
Autonomous systems share routing information, such as routes to each destination and information about the route or AS path, with other ASs using BGP. Routing tables contain lists of next hops, reachable addresses, and associated path cost metrics to each router. BGP uses the information and path attributes to compile a network topology.
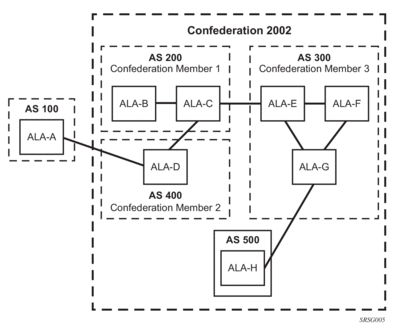
2.1.4. Confederations
Configuring confederations is optional and should only be implemented to reduce the IBGP mesh inside an AS. An AS can be logically divided into smaller groupings called sub-confederations and then assigned a confederation ID (similar to an autonomous system number). Each sub-confederation has fully meshed IBGP and connections to other ASs outside of the confederation.
The sub-confederations have EBGP-type peers to other sub-confederations within the confederation. They exchange routing information as if they were using IBGP. Parameter values such as next hop, metric, and local preference settings are preserved. The confederation appears and behaves like a single AS.
Confederations have the following characteristics:
- A large AS can be sub-divided into sub-confederations.
- Routing within each sub-confederation is accomplished via IBGP.
- EBGP is used to communicate between sub-confederations.
- BGP speakers within a sub-confederation must be fully meshed.
- Each sub-confederation (member) of the confederation has a different AS number. The AS numbers used are typically in the private AS range of 64512 to 65535.
To migrate from a non-confederation configuration to a confederation configuration requires a major topology change and configuration modifications on each participating router. Setting BGP policies to select an optimal path through a confederation requires other BGP modifications.
There are no default confederations. Router confederations must be explicitly created. Figure 2 shows an example of a confederation configuration.
Figure 2: Confederation Configuration
2.1.5. Proxy ARP
Proxy ARP is the technique in which a router answers ARP requests intended for another node. The router appears to be present on the same network as the “real” node that is the target of the ARP and takes responsibility for routing packets to the “real” destination. Proxy ARP can help nodes on a subnet reach remote subnets without configuring routing or a default gateway.
Typical routers only support proxy ARP for directly attached networks; the router is targeted to support proxy ARP for all known networks in the routing instance where the virtual interface proxy ARP is configured.
To support DSLAM and other edge-like environments, proxy ARP supports policies that allow the provider to configure prefix lists that determine for which target networks proxy ARP will be attempted and prefix lists that determine for which source hosts proxy ARP will be attempted.
Also, the proxy ARP implementation will support the ability to respond for other hosts within the local subnet domain. This is needed in environments such as DSL where multiple hosts are in the same subnet but can not reach each other directly.
Static ARP is used when a Nokia router needs to know about a device on an interface that cannot or does not respond to ARP requests. The configuration can state that, if it has a packet with a specific IP address, to send it to the corresponding ARP address. Use proxy ARP so the router responds to ARP requests on behalf of another device.
2.1.6. Exporting an Inactive BGP Route from a VPRN
The export-inactive-bgp command under config>service>vprn provides an IP VPN configuration option that allows the best BGP route learned by a VPRN to be exported as a VPN-IP route even when that BGP route is inactive due to the presence of a more preferred BGP-VPN route from another PE. This “best-external” type of route advertisement is useful in active/standby multi-homing scenarios because it can ensure that all PEs have knowledge of the backup path provided by the standby PE.
2.1.7. DHCP Relay
Refer to the 7450 ESS, 7750 SR, and VSR Triple Play Service Delivery Architecture Guide for information about DHCP relay and support, as well as configuration examples.
2.1.8. Internet Protocol Versions
The -TiMOS implements IP routing functionality, providing support for IP version 4 (IPv4) and IP version 6 (IPv6). IP version 6 (RFC 1883, Internet Protocol, Version 6 (IPv6)) is a version of the Internet Protocol designed as a successor to IP version 4 (IPv4) (RFC-791, Internet Protocol). The changes from IPv4 to IPv6 affect the following categories:
- Expanded addressing capabilities — IPv6 increases the IP address size from 32 bits (IPv4) to 128 bits, to support more levels of addressing hierarchy, a much greater number of addressable nodes, and simpler auto-configuration of addresses. The scalability of multicast routing is improved by adding a scope field to multicast addresses. Also, a type of address called an anycast address is defined that is used to send a packet to any one of a group of nodes.
- Header format simplification — Some IPv4 header fields have been dropped or made optional to reduce the common-case processing cost of packet handling and to limit the bandwidth cost of the IPv6 header.
- Improved support for extensions and options — Changes in the way IP header options are encoded allows for more efficient forwarding, less stringent limits on the length of options, and greater flexibility for introducing options in the future.
- Flow labeling capability — The capability to enable the labeling of packets belonging to traffic flows for which the sender requests special handling, such as non-default quality of service or “real-time” service was added in IPv6.
- Authentication and privacy capabilities — Extensions to support authentication, data integrity, and (optional) data confidentiality are specified for IPv6.
Figure 3: IPv6 Header Format
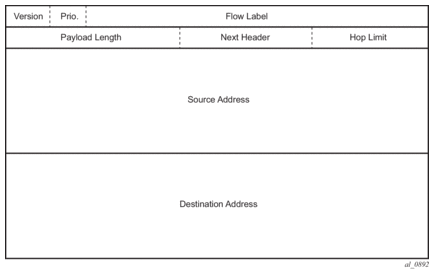
Table 4: IPv6 Header Field Descriptions
Field | Description |
Version | 4-bit Internet Protocol version number = 6. |
Prio. | 4-bit priority value. |
Flow Label | 24-bit flow label. |
Payload Length | 16-bit unsigned integer. The length of payload, for example, the rest of the packet following the IPv6 header, in octets. If the value is zero, the payload length is carried in a jumbo payload hop-by-hop option. |
Next Header | 8-bit selector. Identifies the type of header immediately following the IPv6 header. This field uses the same values as the IPv4 protocol field. |
Hop Limit | 8-bit unsigned integer. Decremented by 1 by each node that forwards the packet. The packet is discarded if the hop limit is decremented to zero. |
Source Address | 128-bit address of the originator of the packet. |
Destination Address | 128-bit address of the intended recipient of the packet (possibly not the ultimate recipient if a routing header is present). |
2.1.8.1. IPv6 Address Format
IPv6 uses a 128-bit address, as opposed to the IPv4 32-bit address. Unlike IPv4 addresses, which use the dotted-decimal format, with each octet assigned a decimal value from 0 to 255, IPv6 addresses use the colon-hexadecimal format X:X:X:X:X:X:X:X, where each X is a 16-bit section of the 128-bit address. For example:
2001:0db8:0000:0000:0000:0000:0000:0000
Leading zeros must be omitted from each block in the address. A series of zeros can be replaced with a double colon. For example:
2001:db8::
The double colon can only be used once in an address.
The IPv6 prefix is the part of the IPv6 address that represents the network identifier, which appears at the beginning of the address. The IPv6 prefix length, which begins with a forward slash (/), shows how many bits of the address make up the network identifier. For example, the address 2001:db8:8086:6502::1/64 means that the first 64 bits of the address represent the network identifier; the remaining 64 bits represent the node identifier.
| Note: IPv6 addresses and prefixes are displayed according to RFC 5952, A Recommendation for IPv6 Address Text Representation. |
2.1.8.2. IPv6 Applications
Examples of the IPv6 applications supported by the SR OS include:
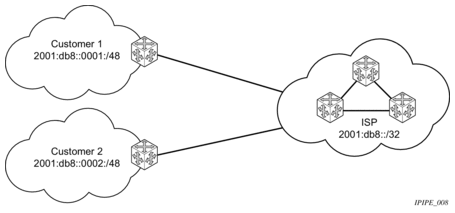
- IPv6 services to enterprise customers and home users — Figure 6 shows IPv6 services to enterprise and home broadband users.
Figure 6: IPv6 Services to Enterprise Customers and Home Users
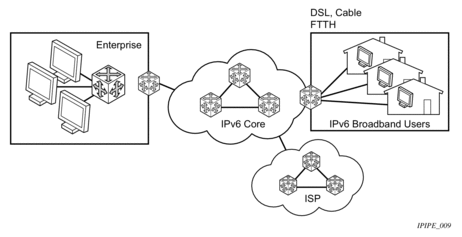
- IPv6 over IPv4 relay services — IPv6 over IPv4 tunnels are one of many IPv6 transition methods to support IPv6 in an environment where not only IPv4 exists but native IPv6 networks depend on IPv4 for greater IPv6 connectivity. Nokia routers support dynamic IPv6 over IPv4 tunneling. The IPv4 source and destination address are taken from configuration, the source address is the IPv4 system address and the IPv4 destination is the next hop from the configured IPv6 over IPv4 tunnel.IPv6 over IPv4 is an automatic tunnel method that gives a prefix to the attached IPv6 network. Figure 7 shows IPv6 over IPv4 tunneling to transition from IPv4 to IPv6.
Figure 7: IPv6 over IPv4 Tunnels
2.1.8.3. DNS
The DNS client is extended to use IPv6 as transport and to handle the IPv6 address in the DNS AAAA resource record from an IPv4 or IPv6 DNS server. An assigned name can be used instead of an IPv6 address because IPv6 addresses are more difficult to remember than IPv4 addresses.
2.1.8.4. Secure Neighbor Discovery (SeND)
Secure Neighbor Discovery (SeND) in conjunction with Cryptographically Generated Addresses (CGAs) allows operators to secure IPv6 neighbor discovery between nodes on a common Layer 2 network segment.
When SeND is enabled on an interface, CGAs must be enabled and static GUA/LLA IPv6 addressing is not supported. In this case, the router will generate a CGA from the configured prefix (GUA, LLA) and use that address for all communication. The router will validate NS/ND messages from other nodes on the network segment, and only install them in the neighbor cache if they pass validation.
A number of potential use-cases for SeND exist in order to secure the network from deliberate or accidental tampering during neighbor discovery, SeND can prevent hijacking of in-use IPv6 addressing or man-in-the-middle attacks, but also to validate whether a node is permitted to participate in neighbor discovery, or validate which routers are permitted to act as default gateways.
SeND affects the following areas of neighbor discovery:
- Neighbor solicitation (solicited-node multicast address; target address)
- Neighbor advertisement (solicited; unsolicited)
- Router solicitation
- Router advertisement
- Redirect messages
Figure 8: Neighbor Discovery with and without SeND
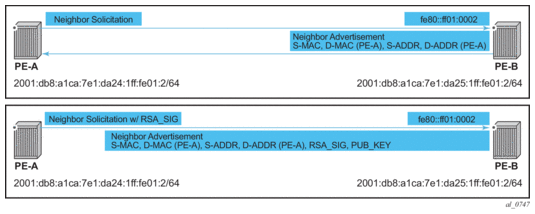
When SeND is enabled on a node, basic neighbor discovery messaging is changed as shown in Figure 8. In the example, PE-A needs to find the MAC address of PE-B.
- PE-A sends an NS message to the solicited node multicast address for PE-B's address with the CGA option, RSA signature option, timestamp option, and nonce option.
- PE-B processes the NS message and, because it is configured for SeND operation, processes the NS. PE-B will validate the source address of the packet to ensure it is a valid CGA, then validate the cryptographic signature embedded in the NS message.
- PE-B generates an NA message, which is sent back to PE-A with the solicited bit, router bit set. The source address is that of PE-B, while the destination address is that of PE-A from the NS message. The timestamp is generated from PE-B, while the nonce is copied from PE-A's NS message.
- PE-A receives the NA and completes similar checks as PE-B did.
If all steps process correctly, both nodes will install each other’s addresses into their neighbor cache database.
2.1.8.5. SeND Persistent CGAs
Persistent CGAs is a feature of SeND.
Previously, all generated CGAs on SeND-enabled interfaces remained unchanged after a CPM switchover, but after a reboot from a saved configuration file, all CGAs were regenerated.
To keep the same CGAs after a reboot from a saved configuration file:
- Save the RSA key pair used for SeND.
- Save the modifiers used during the CGA generation.
To make the CGAs persistent:
- Import an online or offline generated RSA key pair for SeND.
- Ensure that the CompactFlash (CF) files containing an RSA key pair that is used for SeND, are synchronized to the standby CPM by making use of the HA infrastructure used for certificates.
- Ensure that the configuration file is saved when one or more CGAs are generated.
2.1.8.5.1. Persistent RSA Key Pair
The RSA key pair is stored in a file on the CF.
Generate an RSA Key Pair
To generate an RSA key pair, use the admin certificate gen-keypair command:
admin certificate gen-keypair local-url [type rsa] size 1024
For example:
This generates a der formatted file.
Import an online/offline generated RSA key pair
To import a generated RSA key pair, use the admin certificate secure-nd-import command:
admin certificate secure-nd-import local-url format {der | pem | pkcs12} [password <password>] [key-rollover]
For example:
- Because SeND only uses RSA key pairs, the command is refused if the imported key type is not RSA.
- Because SeND only supports key size 1024, the command is refused if the imported key size is not 1024.
- The password has to be specified when an offline generated file in pkcs12 format has to be imported.
- key-rollover keyword: see the RSA key pair rollover mechanism section that follows.
- This command creates the file cfx:\system-pki\secureNdKey (fixed directory and file name) and saves the imported key in that file in encrypted der format (same as the admin certificate import command).
- The RSA key pair is uploaded in the memory of SeND.
RSA key pair rollover mechanism
To trigger a key rollover, use the admin certificate secure-nd-import command described in the previous section Import an online/offline generated RSA key pair.
For example:
- If CGAs exist that are generated based on an auto-generated or previously imported RSA key pair and the key-rollover keyword is not specified, the secure-nd-import command is refused.
- If a secure-nd-import with key-rollover is requested while a previous key rollover is still being handled, the new command is refused.
- If the secure-nd-import command is accepted, the imported RSA key pair is written to the file cfx:\system-pki\secureNdKey and loaded to SeND. Existing CGAs if any will be regenerated.
- While handling a key rollover, SeND keeps track of which interface uses which RSA key pair. Temporarily, SeND can have two RSA key pairs in use. At all times, only the latest RSA key pair is stored in the file cfx:\system-pki\secureNdKey. When the rollover is finished, the RSA key pair that is no longer referred to, is deleted from SeND’s memory.
Auto-generation of RSA key pair
The first time an interface becomes SeND enabled, SeND needs an RSA key pair to generate or check a modifier and to generate a CGA.
If the operator did not import an RSA key pair for SeND, an auto-generated RSA key pair will be used as a fallback.
The auto-generated RSA key pair is synchronized to the standby CPM, but will not be written to the CF. Therefore, all CGAs generated via an auto-generated RSA key pair are not persistent. A warning will be raised whenever a non-persistent CGA is generated.
The admin certificate secure-nd-import command without the key-rollover keyword will be refused if CGAs exist that made use of the auto-generated RSA key pair. Specifying the key-rollover keyword will result in regeneration of the CGAs.
See the section Making non-persistent CGAs persistent for more information about the procedure to make non-persistent CGAs persistent.
HA
For the synchronization of the RSA key pair file in cfx:\system-pki\ used by SeND, the following commands for manual and automatic certificate synchronization are used:
- manual: admin redundancy synchronize cert
- automatic: configure redundancy cert-sync
SeND also synchronizes the RSA key pair to the standby CPM.
2.1.8.5.2. Persistent CGA Modifier
The modifier used during the CGA generation will be saved in the configuration file. The CGA itself is not stored.
Based on the stored modifier and RSA key pair, the same CGA can be regenerated.
The modifier is needed to be sent out in ND messages.
By storing the modifier in the configuration file, the operator can also configure an offline generated modifier (possibly with a security parameter > 1).
Example 1: Configure a SeND interface without modifiers:
=> A modifier is generated based on the actual RSA key pair (that is, imported or auto-generated). The modifier is used to generate a link-local CGA.
=> The modifier is saved in the interface configuration file:
=> A modifier is generated based on the actual RSA key pair. The modifier is used to generate the global CGA.
=> The modifier is stored in the interface configuration file.
Example 2: Configure a SeND interface with modifiers:
=> The offline generated modifier is used to generate the link-local CGA:
=> A modifier is generated based on the actual RSA key pair. The modifier is used to generate the global CGA.
=> The modifier is stored in the interface configuration file:
=> The same offline generated modifier as the preceding link-local address is used for the generation of a global address:
=> Another offline generated modifier (*) is used for the generation of a global address.
=> For an offline generated modifier, a check is performed to see if it is generated with the actual RSA key pair and the security parameter applicable for the interface. If this check fails, the command is refused, unless the command is triggered in the context of an exec of a config file. In that case, the modifier is replaced by a new one that is generated based on the actual RSA key pair.
2.1.8.5.3. Making non-persistent CGAs persistent
CGAs can be non-persistent because:
- The operator forgot to configure an RSA key pair for SeND, so hence the CGAs were generated based on an auto-generated RSA key pair.
- The operator forgot to synchronize an RSA key pair file to the stand-by CPM and a switch-over happens.
- The CGAs were generated by a software version not having persistent CGAs (such as, ISSU).
- The system was booted from a configuration file generated by a software version not having persistent CGAs.
Key rollover
You can import a new RSA key pair for SeND with the key-rollover keyword. This will result in the regeneration of all CGAs on all interfaces.
Exporting the SeND RSA key pair
Another method that does not result in the regeneration of the CGAs is to export the RSA key pair that is currently in use by SeND to the system-pki directory via an admin command:
admin certificate secure-nd-export
This command will write the RSA key pair to the file cfx:\system-pki\secureNdKey in encrypted der format.
2.1.8.5.4. Booting from a saved configuration file
Configuration saved by a software version with persistent CGAs
The file cfx:\system-pki\secureNdKey should exist. This file will be automatically uploaded by SeND during initialization.
The configuration file should contain a modifier for each address on a SeND enabled interface.
Modifiers in the configuration file are checked against the current RSA key pair. If the check fails, a new modifier and CGA is generated and a warning is raised that a new CGA is generated.
If a modifier is missing from the configuration file for an IPv6 /64 prefix on a SeND enabled interface, a new modifier and CGA will be generated based on the active RSA key pair.
Configuration saved by a software version having non-persistent CGAs
The file cfx:\system-pki\secureNdKey does not exist nor does the configuration file contain a modifier for any of the IPv6 /64 prefixes on secure-nd enabled interfaces.
New CGAs have to be generated (from the CLI context). Follow one of the procedures described in section Making non-persistent CGAs persistent to make the non-persistent CGA's persistent.
2.1.8.6. IPv6 Provider Edge Router over MPLS (6PE)
6PE allows IPv6 domains to communicate with each other over an IPv4 MPLS core network. Because forwarding is based on MPLS labels, backbone infrastructure upgrades and core router re-configuration is not required in this architecture. 6PE is a cost-effective solution for IPv6 deployment.
Figure 9: Example of a 6PE Topology within One AS
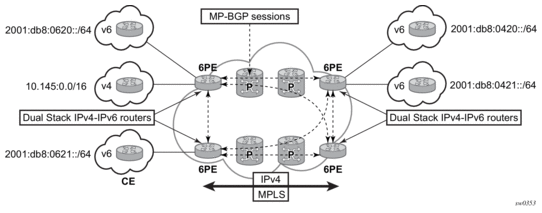
2.1.8.6.1. 6PE Control Plane Support
The 6PE MP-BGP routers support:
- IPv4 and IPv6 dual-stack
- MP-BGP to exchange IPv6 reachability information:
- The 6PE routers exchange IPv6 reachability information using MP-BGP (AFI 2, SAFI 4).
- An IPv4 address of the 6PE router is encoded as an IPv4-mapped IPv6 address in the BGP next-hop field. This is usually the IPv4 system address.
- The 6PE router binds MPLS labels to the IPv6 prefixes it advertises. SR OS routers advertise the IPv6 explicit null (value 2) in advertised 6PE routes but accept any arbitrary label from peers.
- The most preferred tunnel to the BGP next-hop allowed by the 6PE resolution filter (config>router>bgp>next-hop-resolution>labeled-routes>transport-tunnel>family label-ipv6>resolution-filter) is used to tunnel the traffic to the remote 6PE router.
2.1.8.6.2. 6PE Data Plane Support
The ingress 6PE router can push two or more MPLS labels to send the packets to the egress 6PE router. The top labels are associated with resolving the transport tunnels. The bottom label is advertised in MP-BGP by the remote 6PE router. Typically, the IPv6 explicit null (value 2) label is used, but any arbitrary value can be received when the remote 6PE router is not an SR OS router.
The egress 6PE router pops the top transport labels. When the IPv6 explicit null label is exposed, the egress 6PE router knows that an IPv6 packet is encapsulated. It pops the IPv6 explicit null label and performs an IPv6 route lookup to find the next hop for the IPv6 packet.
2.1.9. Static Route Resolution Using Tunnels
The user can forward packets of a static route to an indirect next-hop over a tunnel programmed in TTM by configuring the following static route tunnel binding command:
If tunnel-next-hop context is configured and resolution is set to disabled, the binding to tunnel is removed and resolution resumes in RTM to IP next-hops.
If resolution is set to any, any supported tunnel type in static route context will be selected following TTM preference.
The following tunnel types are supported in a static route context: LDP, RSVP-TE, Segment Routing (SR) Shortest Path, and Segment Routing Traffic Engineering (SR-TE):
- LDPThe ldp value instructs the code to search for an LDP LSP with a FEC prefix corresponding to the address of the indirect next-hop. Both LDP IPv4 FEC and LDP IPv6 FEC can be used as the tunnel next-hop. However, only an indirect next-hop of the same family (IPv4 or IPv6) as the prefix of the route can use an LDP FEC as the tunnel next-hop. In other words, an IPv4 (IPv6) prefix can only be resolved to an LDP IPv4 (IPv6) FEC.
- RSVP-TEThe rsvp-te value instructs the code to search for the set of lowest metric RSVP-TE LSPs to the address of the indirect next-hop. The LSP metric is provided by MPLS in the tunnel table. The static route treats a set of RSVP-TE LSPs with the same lowest metric as an ECMP set.The user has the option of configuring a list of RSVP-TE LSP names to be used exclusively instead of searching in the tunnel table. In that case, all LSPs must have the same LSP metric in order for the static route to use them as an ECMP set. Otherwise, only the LSPs with the lowest common metric value are selected.A P2P auto-lsp that is instantiated via an LSP template can be selected in TTM when resolution is set to any. However, it is not recommended to configure an auto-lsp name explicitly under the rsvp-te node as the auto-generated name can change if the node reboots, which will blackhole the traffic of the static route.
- SR Shortest PathWhen the sr-isis or sr-ospf value is enabled, an SR tunnel to the indirect next-hop is selected in the TTM from the lowest preference ISIS or OSPF instance, and if many instances have the same lowest preference, it is selected from the lowest numbered IS-IS or OSPF instance. Both SR-ISIS IPv4 and SR-ISIS IPv6 tunnels can be used as tunnel next-hops. However, only an indirect next-hop of the same family (IPv4 or IPv6) as the prefix of the route can use an SR-ISIS tunnel as a tunnel next-hop. In other words, an IPv4 (IPv6) prefix can only be resolved to a SR-ISIS IPv4 (IPv6).
- SR-TEThe sr-te value instructs the code to search for the set of lowest metric SR-TE LSPs to the address of the indirect next-hop. The LSP metric is provided by MPLS in the tunnel table. The static route treats a set of SR-TE LSPs with the same lowest metric as an ECMP set.The user has the option of configuring a list of SR-TE LSP names to be used exclusively instead of searching in the tunnel table. In that case, all LSPs must have the same LSP metric in order for the static route to use them as an ECMP set. Otherwise, only the LSPs with the lowest common metric value are selected.
If one or more explicit tunnel types are specified using the resolution-filter option, only these tunnel types will be selected again following the TTM preference.
The user must set resolution to filter to activate the list of tunnel-types configured under resolution-filter.
If disallow-igp is enabled, the static route will not be activated using IP next-hops in RTM if no tunnel next-hops are found in TTM.
2.1.9.1. Static Route ECMP Support
The following is the ECMP behavior of a static route:
- ECMP is supported when resolving in RTM multiple static routes of the same prefix with multiple user-entered indirect IP next-hops. The system picks as many direct next-hops as available in RTM beginning from the first indirect next-hop and up to the value of the ecmp option in the system.
- ECMP is also supported when resolving in TTM a static route to a single indirect next-hop using a LDP tunnel when LDP has multiple direct next-hops.
- ECMP is supported when resolving in TTM a static route to a single indirect next-hop using a RSVP-TE tunnel type when there is more than one RSVP LSP with the same lowest metric to the indirect next-hop.
- ECMP is supported when resolving in TTM a static route to a single indirect next-hop using a list of user-configured RSVP-TE LSP names when these LSPs have the same metric to the indirect next-hop.
- ECMP is supported when resolving in TTM multiple static routes of the same prefix with multiple user-entered indirect next-hops, each binding to a tunnel type. The system picks as many tunnel next-hops as available in TTM beginning from the first indirect next-hop and up to the value of the ecmp option in the system. The spraying of flow packets is performed over the entire set of resolved next-hops that correspond to the selected indirect next-hops.
- ECMP is supported when resolving concurrently in RTM and TTM multiple static routes of the same prefix with multiple user-entered indirect tunnel next-hops. There is no support for mixing IP and tunnel next-hops for the same prefix using different indirect next-hops. Tunnel next-hops are preferred over IP next-hops.
2.2. Weighted Load Balancing over MPLS LSP
The weighted load-balanced, or weighted-ecmp, feature sprays packets of IGP, BGP, and static route prefixes, resolved to a set of ECMP tunnel next hops, proportionally to the weights configured for each MPLS LSP in the ECMP set.
Weighted load balancing is supported in the following forwarding contexts:
- IGP prefix resolved to IGP shortcuts in RTM (igp-shortcut or advertise-tunnel-link enabled in the IGP instance)
- BGP prefix with the BGP next hop resolved to IGP shortcuts in RTM (rsvp-shortcut enabled in the IGP instance)
- static route prefix resolved to an indirect next hop, which is resolved to a set of equal-metric MPLS LSPs in TTM. The user can allow automatic selection or specify the names of the equal-metric MPLS LSPs in TTM to be used in the ECMP set.
- static route prefix resolved to an indirect next hop, which is resolved to IGP shortcuts in RTM
- BGP prefix with a BGP next hop resolved to a static route, which resolves to a set of tunnel next hops toward an indirect next hop in RTM or TTM
- BGP prefix resolving to another BGP prefix, whose next hop is resolved to a set of ECMP tunnel next hops with a static route in RTM or TTM or to IGP shortcuts in RTM
- BGP labeled IPv6 packets (6PE) over RSVP LSPs resolving in TTM
This feature does not modify the route calculation: the same set of ECMP next hops is computed for a prefix. The feature also does not change the hash routine; only the spraying of the flows over the tunnel next hops is modified to reflect the normalized weight of each tunnel next hop.
Static route implementation supports ECMP over a set of equal-cost MPLS LSPs. The user can allow automatic selection or specify the names of the equal-metric MPLS LSPs in TTM to be used in the ECMP set. For more information, see Static Route Resolution Using Tunnels.
2.2.1. Weighted Load Balancing IGP, BGP, and Static Route Prefix Packets over IGP Shortcut
2.2.1.1. Feature Configuration
The user must have the IGP shortcut or forwarding adjacency feature enabled in one or more IGP instances:
config>router>ospf(isis)>igp-shortcut
config>router>ospf(isis)>advertise-tunnel-link
The user can also disable specific MPLS LSPs from being used in IGP shortcut or forwarding adjacency by configuring the following:
config>router>mpls>lsp>no igp-shortcut
The user enables the weighted load balancing feature using the following router level command:
config>router>weighted-ecmp
When this command is enabled, packets of IGP, BGP, and static route prefixes resolved to a set of ECMP tunnel next-hops are sprayed proportionally to the weights configured for each MPLS LSP in the ECMP set.
The user can configure a weight for each LSP using the following command:
config>router>mpls>lsp>load-balancing-weight <32-bit-integer>
For an auto-LSP signaled via an LSP template, the weight is configured using the following command:
config>router>mpls>lsp-template>load-balancing-weight <32-bit-integer>
There is no default weight value for an LSP. If any LSP in the ECMP set of a prefix does not have a weight configured, the regular ECMP spraying for the prefix will be performed. The user-entered weight is normalized to the closest integer value that represents the number of entries in the ingress prefix hash table assigned to the LSP for the purpose of spraying packets of all prefixes resolved to this LSP. The higher the normalized weight, the more entries will be assigned to the LSP, the more packets will be sent to this LSP.
2.2.1.2. Feature Behavior
This section describes the behavior of the weighted load-balancing feature for IGP, BGP, and static route prefixes resolved in RTM to IGP shortcuts.
When an IGP, BGP, or a static route prefix is resolved in RTM to a set of ECMP tunnel next-hops of type RSVP-TE, and the router level weighted-ecmp option is enabled, the ingress hash table for the next-hop selection is populated with a number of tunnel next-hop entries for each LSP equal to the normalized LSP weight value. All prefixes resolving to the same set of ECMP tunnel next-hops use the same table.
This feature performs the following:
- MPLS populates the user-configured LSP weight in TTM. When the global command weighted-ecmp is enabled, and any LSP in the ECMP set of a prefix does not have a weight configured, the regular ECMP spraying for the prefix will be performed.
- IGP computes the normalized weight for each prefix tunnel next-hop. The minimum value of the normalized weight is 1 and the maximum is 64. IGP updates the route in RTM with the set of tunnel next-hops and normalized weights. RTM downloads the information to IOM for inclusion in the FIB.
- The normalized weights of route tunnel next-hops are updated in the following cases:
- When the main SPF is run following a trigger, for example, network failure, and updates a route with a modified set of tunnel next-hops. This will trigger a route re-download to the IOM and all users of RTM are notified.
- The user adds or changes the weight of one or more LSPs. In this case, RTM will perform a route download to IOM, but other users of RTM are not notified because the route resolution did not change.
- The weighted load balancing feature is only applied to a prefix when all the tunnel next-hops in the ECMP set have the same endpoint. If an IGP prefix resolves in RTM to a set of ECMP tunnel next-hops that do not terminate on the same endpoint, the regular ECMP spraying is performed. If BGP performs BGP ECMP to a set of BGP ECMP next-hops for a prefix (weighted-bgp-ecmp-prd), regular ECMP spraying is performed toward a BGP next-hop if the subset of its tunnel next-hops does not terminate on the same endpoint.
- Regular ECMP spraying is also applied if a prefix is resolved in RTM to an ECMP set that consists of a mix of IP and tunnel next-hops.
- This feature is not supported in the following contexts:
- Packets of BGP prefix with the BGP next-hop resolved in TTM to RSVP LSP (BGP shortcut).
- CPM generated packets, including OAM packets, which are looked-up in RTM and which are forwarded over tunnel next-hops. These will be forwarded using either regular ECMP or by selecting one next-hop from the set.
2.2.1.3. ECMP Considerations
The weight assigned to an LSP affects only the forwarding decision, not the routing decision. It does not change the selection of the set of ECMP tunnel next-hops of a prefix when more next-hops exist than the value of the router ecmp option. This selection continues to follow the algorithm used in the IGP shortcut feature.
After the set of tunnel next-hops is selected, the LSP weight is used to modulate the amount of packets forwarded over each next-hop.
2.2.1.4. Weighted Load Balancing Static Route Packets over MPLS LSP
2.2.1.4.1. Feature Configuration
The configuration of the resolution of a static route prefix to set of MPLS LSPs is described in Static Route Resolution Using Tunnels which also provides the selection rules among multiple LSP types: RSVP-TE, SR-TE, LDP, SR-ISIS, and SR-OSPF. A static route of a prefix can only be resolved to a set of tunnel next-hops of the same type though, for each indirect next-hop.
To perform ECMP over a set of configured MPLS LSPs, the user must enter two or more LSP names to be used as tunnel next-hops. If automatic selection is performed, ECMP is performed if two or more MPLS LSPs are in TTM to the indirect next-hop of the static route. However, all LSPs must have the same LSP metric; otherwise, only the tunnel next-hops with the same lowest metric will be activated for the static route.
The user can force the metric of an LSP to a constant value using the following command:
If the user enters, for the same static route, more LSP names with the same LSP metric than the value of the router level ecmp option, only the first configured LSPs equal to the ecmp value will be selected. The remaining tunnel next-hops for the route will not be activated. When automatic MPLS LSP selection is performed in TTM, the lowest tunnel ID is used as a tie-breaker among the same lowest metric LSPs.
To perform weighted load-balancing over the set of MPLS LSPs, either when the LSP names are provided or when auto-selection in TTM is performed, the user must also enable the weighted ECMP globally like for static, IGP, and BGP prefixes resolving to IGP shortcuts:
2.2.1.4.2. Feature Behavior
The behavior of this feature in terms of RTM and IOM is exactly the same as in the case of BGP, IGP, and static route prefixes resolving to IGP shortcuts. See Feature Behavior for more information. In this case, the static route module computes the normalized weight for each prefix tunnel next-hop of the static route indirect next-hop. The minimum value of the normalized weight is 1 and the maximum is 64. The static route module updates the route in RTM with the set of tunnel next-hops and normalized weights. RTM downloads the information to IOM for inclusion in the FIB.
If any LSP in the ECMP set of a prefix static route does not have a weight configured, the regular ECMP spraying for the prefix will be performed.
ECMP is also supported when resolving in TTM the same static route with multiple user-entered indirect next-hops, each binding to the same or different tunnel types. The system picks as many tunnel next-hops as available in RTM, beginning from the first indirect next-hop and up to the value of the ecmp option in the system. In this case, the weighted load-balancing will be applied directly using the weights of the selected set of tunnel next-hops. If any LSP in the ECMP set of a prefix static route does not have a weight configured, or if any of the indirect next-hops binds to an LDP LSP, the regular ECMP spraying for the prefix will be performed.
If the same prefix is resolved via both a static route and an IGP shortcut route, the RTM default protocol preference will install the static route only. Therefore, the set of ECMP tunnel next-hops and the weighted load balancing behavior will be determined by the static route configuration and not by the IGP shortcut configuration.
2.2.2. Weighted Load Balancing for 6PE
ECMP-like spraying for BGP labeled IPv6 packets (6PE) is controlled using the config>router>ecmp max-ecmp-routes command, where max-ecmp-routes represents the maximum number of RSVP tunnels in the set representing equal-cost paths to the BGP next hop.
Weighted ECMP behavior, where the load-balancing weight of the RSVP tunnel is considered in the packet spraying behavior, is configured using the config>router>bgp>next-hop-resolution>weighted-ecmp command. Weighted ECMP is disabled by default.
2.3. Class-Based Forwarding of IPv4/IPv6 Prefix Over IGP IPv4 Shortcut
This feature enables class-based forwarding (CBF) over IGP shortcuts. When the class-forwarding command is enabled, the following types of packets are forwarded based on their forwarding class:
- packets of BGP prefixes
- packets that are CPM-originated for the IPv4, IPv6, or both IPv4 and IPv6 families that have been enabled over IGP shortcuts using the igp-shortcut CLI context in one or more IGP instances
The SR OS CBF implementation supports spraying of packets over a maximum of four forwarding sets of ECMP LSPs. The user must define a class-forwarding policy object in MPLS to configure the mapping of FCs to the forwarding sets. Then, the user assigns the CBF policy name and set ID to each MPLS LSP that is used in IGP shortcuts.
When a BGP IPv4 or IPv6 prefix is resolved, the FC of the packet, is used to look up the forwarding set ID. Then, a modulo operation is performed on the tunnel next-hops of this set ID only, to spray packets of this FC. The data path concurrently implements, CBF and ECMP within the tunnels of each set ID.
CPM-originated packets on the router, including control plane and OAM packets, are forwarded over a single LSP from the set of LSPs that the packet's FC is mapped to, as per the CBF configuration.
2.3.1. Feature Configuration
The user enables CBF over IGP shortcuts using the following command:
A:Reno 194# configure>router$ class-forwarding
All FCs are mapped to set 1 as soon as the policy is created. The user can make changes to the mapping of FCs as required. An FC, which is not added to the class-forwarding policy, is thus always mapped to set 1. At most, an FC can be mapped to a single forwarding set. One or more FCs can map to the same set. The user can indicate the initial default set by including the default-set option.
The default forwarding set is used to forward packets of any FC in cases where all LSPs of the forwarding set the FC maps to become operationally down. The router uses the user-configured default set as the initial default set. Otherwise, the router elects the lowest numbered set as the default forwarding set in a class-forwarding policy. When the last LSP in a default forwarding set goes into an operationally down state, the router designates the next lowest-numbered set as the new default forwarding set.
A mapping to a class-forwarding policy and set is added to the existing CBF configuration of an RSVP-TE LSP and to the LSP template of an RSVP-TE auto-LSP. The following commands perform this function.
A:Reno 194# config>router>mpls>lsp>class-forwarding$ forwarding-set policy policy-name set set-id <1..4>
A:Reno 194# config>router>mpls>lsp-template>class-forwarding$ forwarding-set policy policy-name set set-id <1..4>
An MPLS LSP can map only to a single class-forwarding policy and forwarding set. Multiple LSPs can map to the same policy and set. If they form an ECMP set, from the IGP shortcut perspective, packets of the FCs mapped to this set will be sprayed over these LSPs based on a modulo operation of the output of the hash routine on the packet's headers and the number of LSPs in the set.
2.3.2. Feature Behavior
When a BGP IPv4 or IPv6 prefix is resolved to a BGP next-hop, consisting of up to 64 resolved next-hops (LSPs and IP links), the default behavior of the data path is to spray the packets over the entire ECMP set using a modulo operation of the number of resolved next-hops in the ECMP set and the output of the hash on the packet header fields.
Both the CBF feature in LDP-over-RSVP and this CBF feature over IGP IPv4 shortcuts make use of the CBF class-forwarding policy. IGP always passes the CBF information populated by MPLS for each LSP used as a tunnel next-hop by an IGP prefix. The new CBF information is checked for consistency. If more than a single class-forwarding policy exists in the tunnel next-hops of a IGP prefix, IGP removes the new CBF information from all the corresponding tunnels and the behavior will be as if there were no CBF info.
When the CBF feature is enabled (class-forwarding option, enabled under config>router context), each application (BGP, CPM, or LDP), when looking up a prefix in RTM, will find up to 64 IP and tunnel next-hops. This lookup is split into three subsets:
- Subset 1 — tunnel next-hops with older CBF information (FCs mapped to this LSP, default LSP (true/false), CBF Policy ID=0, Set ID=any valid value). This information is usable by LDP only. Other applications treat this like non-CBF information.
- Subset 2 — tunnel next-hops with new CBF information (FCs mapped to this LSP, default LSP (true/false), CBF Policy ID>0, Set ID>0). This information is usable by both LDP and other applications.
- Subset 3 — tunnel-next-hops with no CBF information and IP next-hops. Usable by all applications, except that LDP will use tunnel next-hops only.
The BGP application performs a lookup in RTM for a prefix matching each BGP next-hop of a prefix. The BGP application selects tunnels belonging to the class-forwarding sets in Subset 2 and for each BGP next-hop of a prefix. The remaining tunnels, with no CBF configuration or with the older CBF information and the IP next-hops, are still programmed to IOM. However, BGP and the data path will use them only when all the class-forwarding sets are not available as explained below.
The SR OS implements a hierarchical ECMP architecture for BGP prefixes in the data path. The first level is the ECMP at the BGP next-hop level. The second level is ECMP at the resolved next-hop (IP or tunnel next-hop) level. The CBF feature is independently applied to the set of resolved tunnel next-hops of each BGP next-hop of a prefix. The user must make sure that the sets of LSPs that are used as IGP shortcuts to reach each of the BGP next-hops have the appropriate FC mappings.
The following procedures are enforced in the CBF feature.
- The tunnels in the full next-hop ECMP set, with set size greater or equal to 1 and less than or equal to 64, can use MPLS LSPs that terminate on multiple endpoints (BGP next-hop itself or otherwise) to reach the next-hop of a BGP prefix. The existing ECMP tunnel and IP next-hop selection behavior, when resolving a prefix over IGP shortcuts, continues to be used.
- If no LSP among the full ECMP set of a BGP next-hop has a class-forwarding policy configuration assigned, then the set is considered inconsistent from a CBF perspective. No CBF-related information is programmed in IOM and regular ECMP spraying over the full set occurs.
- If only a single class-forwarding policy is referenced by one or more LSPs in the full ECMP set of a BGP next-hop, the full set is considered consistent from a CBF perspective and the class-forwarding policy is used to spray packets of each FC over the LSPs within each forwarding set. As a result of this processing, only the LSPs that have been selected for forwarding traffic are programmed in IOM with CBF information. The remaining LSPs and IP next-hops of the BGP next-hop, are also programmed in IOM but without any CBF information associated and, therefore, will not be used for CBF.
- If multiple class-forwarding policies are referenced by LSPs in the full ECMP set of a BGP next-hop, the set is considered inconsistent from a CBF perspective. No CBF related information is programmed in IOM and regular ECMP spraying over the full set occurs.
The following describes the fallback behavior in data path of the CBF feature.
- An FC, for which all LSPs in the forwarding set are operationally down, has its packets forwarded over the default forwarding set. The default forwarding set is either the initial default forwarding set configured by the user or the lowest numbered set in the class-forwarding policy that has one or more LSPs in the operationally UP state. If the initial or subsequently elected default forwarding set has all its LSPs operationally down, the next lower numbered forwarding set, which has at least one LSP in the operationally up state, is elected as the default forwarding set.
- If all LSPs of all forwarding sets become operationally down, the router resumes regular ECMP spraying on the remaining LSPs and IP next-hops in the full ECMP set.
- Whenever the first LSP in a forwarding set becomes operationally UP, the router triggers the re-election of the default set and will select this set as the new default set, if it is the initial default set, otherwise, it will select lowest numbered set.
2.3.3. Feature Limitations
The following are the limitations of the CBF feature.
- CBF applies to packets of IPv4 and IPv6 BGP prefixes only. CBF does not apply to IGP prefixes and static route prefixes resolved over IGP IPv4 shortcuts. The latter are forwarded using regular ECMP over the entire set of up to 64 tunnel next-hops.
- CPM originated packets on the router, including control plane and OAM packets, are forwarded over a single LSP from the set of LSPs the packet's FC is mapped to, as per the CBF configuration. CPM, however, only maintains a maximum of 64 next-hops for a given destination prefix. Therefore, if there are multiple BGP next-hops for a prefix, CPM selects 64 tunnel next-hops by cycling over the BGP next-hops in ascending order. Then, the first LSP in the first set ID that the FC of the packet maps to is selected to forward the packet.Furthermore, the CBF information consistency check, the CBF default set determination, and the CBF set failover procedures are applied to this set of 64 tunnel next-hops.The user can configure the SGT-QoS feature to change the DSCP and FC of CPM-originated packets of a specific control plane protocol to select an LSP from a different set ID. This configuration allows, for instance, the forwarding of BGP Keep-Alive packets over an LSP of the same set ID as that of the data plane packets of the BGP prefixes destined to the same BGP next-hop.
- Weighted ECMP, at the transport tunnel level of BGP prefixes over IGP shortcuts, and the CBF feature on a per-BGP next-hop basis are mutually exclusive. Specifically, if the user enables both weighted ECMP (configure>router>weighted-ecmp) and CBF (configure>router> class-forwarding), weighted ECMP applies as long as all the LSPs used as tunnel next-hops to reach the BGP next-hop of a prefix have a user-configured weight. Otherwise, the CBF feature applies as per the procedures described in Feature Behavior.
2.3.4. Data Path Support
When a packet of a BGP IPv4 or IPv6 prefix is received, the data path uses the FC that the packet was classified into to look up the forwarding set ID. The data path then performs a modulo operation on the tunnel next-hops of this set ID, to select the one next-hop for forwarding the packet. Therefore, packets matching an FC are only sprayed over the ECMP tunnel-next-hops of the set ID this FC maps to.
Both the BGP or CPM application and IOM use the same algorithm for failover and default class-forwarding set determination, as described in Feature Behavior and illustrated in Example Configuration and Default CBF Set Election.
If MPLS deletes an LSP from a specified set ID, the IOM handles failover within the same set ID. The IOM reprograms the data path to spray packets of the impacted FCs over the remaining tunnel next-hops of the set ID.
Similarly, the IOM handles failover between class-forwarding sets when MPLS deletes the last LSP in a set ID. The IOM reprograms the data path to spray packets of the impacted FCs over the tunnel next-hops of the failover set ID. In both cases, the failover does not make use of the uniform failover procedure; however, if an LSP activated its FRR backup path, it remains in the set ID and continues to forward traffic of the mapped FCs.
Finally, BGP updates the set IDs, used to reach a BGP next-hop, any time IGP updates the information in the RTM.
2.3.5. Example Configuration and Default CBF Set Election
Assume the following user configuration.
- The FC mapping to the sets and the default forwarding set election are illustrated in Figure 10.
- All sets and RSVP-TE LSPs outside of the three class-forwarding sets are up initially.
- Set 1 is elected as the default class-forwarding set (because the user did not configure an initial default set).
- If All LSPs in Set 1 go operationally down, Set 2 is elected as the default class-forwarding set.
- If Set 2 subsequently goes down, Set 3 is elected as the default class-forwarding set.
- If Set 3 subsequently goes down, then packets of BGP prefixes will be ECMP sprayed over the remaining non-CBF RSVP-TE LSPs.
- If Set 2 comes back up, then Set 2 is elected as the default class-forwarding set.
Figure 10: Default Forwarding Set Election

2.4. Bidirectional Forwarding Detection
Bidirectional Forwarding Detection (BFD) is an efficient, short-duration detection of failures in the path between two systems. If a system stops receiving BFD messages for a long enough period (based on configuration), it is assumed that a failure along the path has occurred and the associated protocol or service is notified of the failure.
BFD can provide a mechanism used for failure detection over any media, at any protocol layer, with a wide range of detection times and overhead, to avoid a proliferation of different methods.
SR OS supports asynchronous and on-demand modes of BFD in which BFD messages are sent to test the path between systems.
If multiple protocols are running between the same two BFD endpoints, only a single BFD session is established, and all associated protocols will share the single BFD session.
As well as the typical asynchronous mode, there is also an echo function defined within RFC 5880, Bidirectional Forwarding Detection, that allows either of the two systems to send a sequence of BFD echo packets to the other system, which loops them back within that system’s forwarding plane. If a number of these echo packets are lost, the BFD session is declared down.
2.4.1. BFD Control Packet
The base BFD specification does not specify the encapsulation type to be used for sending BFD control packets. Instead, use the appropriate encapsulation type for the medium and network. The encapsulation for BFD over IPv4 and IPv6 networks is specified in draft-ietf-bfd-v4v6-1hop-04.txt, BFD for IPv4 and IPv6 (Single Hop). This specification requires that BFD control packets be sent over UDP with a destination port number of 3784 and the source port number must be within the range 49152 to 65535.
Also, the TTL of all transmitted BFD packets must have an IP TTL of 255. All BFD packets received must have an IP TTL of 255 if authentication is not enabled. If authentication is enabled, the IP TTL should be 255, but can still be processed if it is not (assuming the packet passes the enabled authentication mechanism).
If multiple BFD sessions exist between two nodes, the BFD discriminator is used to de-multiplex the BFD control packet to the appropriate BFD session.
2.4.2. Control Packet Format
The BFD control packet has two sections: a mandatory section and an optional authentication section.
Figure 11: Mandatory Frame Format

Table 5: BFD Control Packet Field Descriptions
Field | Description |
Vers | The version number of the protocol. The initial protocol version is 0. |
Diag | A diagnostic code specifying the local system’s reason for the last transition of the session from Up to some other state. Possible values are: 0-No diagnostic 1-Control detection time expired 2-Echo function failed 3-Neighbor signaled session down 4-Forwarding plane reset 5-Path down 6-Concatenated path down 7-Administratively down |
D Bit | The demand mode bit. (Not supported) |
P Bit | The poll bit. If set, the transmitting system is requesting verification of connectivity, or of a parameter change. |
F Bit | The final bit. If set, the transmitting system is responding to a received BFD control packet that had the poll (P) bit set. |
Rsvd | Reserved bits. These bits must be zero on transmit and ignored on receipt. |
Length | Length of the BFD control packet, in bytes. |
My Discriminator | A unique, non-zero discriminator value generated by the transmitting system, used to demultiplex multiple BFD sessions between the same pair of systems. |
Your Discriminator | The discriminator received from the corresponding remote system. This field reflects back the received value of my discriminator, or is zero if that value is unknown. |
Desired Min TX Interval | This is the minimum interval, in microseconds, that the local system would like to use when transmitting BFD control packets. |
Required Min RX Interval | This is the minimum interval, in microseconds, between received BFD control packets that this system is capable of supporting. |
Required Min Echo RX Interval | This is the minimum interval, in microseconds, between received BFD echo packets that this system is capable of supporting. If this value is zero, the transmitting system does not support the receipt of BFD echo packets. |
2.4.3. BFD for RSVP-TE
BFD will notify RSVP-TE if the BFD session goes down, in addition to notifying other configured BFD enabled protocols (for example, OSPF, IS-IS, and PIM). This notification will then be used by RSVP-TE to begin the reconvergence process. This greatly accelerates the overall RSVP-TE response to network failures.
All encapsulation types supporting IPv4 and IPv6 are supported because all BFD packets are carried in IPv4 and IPv6 packets; this includes Frame Relay and ATM.
BFD is supported on the following interfaces:
- Ethernet (Null, Dot1Q & QinQ)
- Spoke SDPs
- LAG interfaces
The following interfaces are supported only on the 7750 SR and 7450 ESS:
- VSM interfaces
- POS interfaces (including APS)
- Channelized interfaces (PPP, HDLC, FR, and ATM) on ASAP (priority 1) and channelized MDAs (priority 2) including link bundles and IMA
2.4.4. Echo Support
Echo support for BFD calls for the support of the echo function within BFD. By supporting BFD echo, the router loops back received BFD echo messages to the original sender based on the destination IP address in the packet.
The echo function is useful when the local router does not have sufficient CPU power to handle a periodic polling rate at a high frequency. Therefore, it relies on the echo sender to send a high rate of BFD echo messages through the receiver node, which is only processed by the receiver’s forwarding path. This allows the echo sender to send BFD echo packets at any rate.
SR OS does not support the sending of echo requests, only the response to echo requests.
2.4.5. BFD Support for BGP
This feature allows BGP peers to be associated with the BFD session. If the BFD session fails, BGP peering will also be torn down.
2.4.6. Centralized BFD
The following applications of centralized BFD require BFD to run on the SF/CPM.
2.4.6.1. IES Over Spoke SDP
One application for a central BFD implementation is so BFD can be supported over spoke SDPs used to inter-connect IES or VPRN interfaces. When there are spoke SDPs for inter-connections over an MPLS network between two routers, BFD is used to speed up failure detections between nodes so re-convergence of unicast and multicast routing information can begin as quickly as possible.
The MPLS LSP associated with the spoke SDP can enter or egress from multiple interfaces on the router. BFD for these types of interfaces cannot exist on the IOMXCM by itself.
Figure 12: BFD for IES/VPRN over Spoke SDP
2.4.6.2. BFD Over LAG and VSM Interfaces
A second application for a central BFD implementation is so BFD can be supported over LAG or VSM interface. This is useful where BFD is not used for link failure detection, but for node failure detection. In this application, the BFD session can run between the IP interfaces associated with the LAG or VSM interface, but there is only one session between the two nodes. There is no requirement for the message flow to across a certain link, or VSM, to get to the remote node.
Figure 13: BFD Over LAG and VSM Interfaces

2.4.6.3. LSP BFD and VCCV BFD
BFD is supported over MPLS-TP, RSVP, and LDP LSPs, as well as over pseudowires that support Layer 2 services such as Epipe VPLS spoke-SDPs and mesh-SDPs using centralized BFD. See the 7450 ESS, 7750 SR, 7950 XRS, and VSR MPLS Guide and 7450 ESS, 7750 SR, 7950 XRS, and VSR Layer 2 Services and EVPN Guide: VLL, VPLS, PBB, and EVPN for more information.
2.4.7. Aggregate Next Hop
This feature adds the ability to configure an indirect next-hop for aggregate routes. The indirect next-hop specifies where packets will be forwarded if they match the aggregate route, but is not a more-specific route in the IP forwarding table.
2.4.8. Invalidate Next-Hop Based on ARP/Neighbor Cache State
This feature invalidates next-hop entries for static routes when the next-hop is no longer reachable on directly connected interfaces. This invalidation is based on ARP and Neighbor Cache state information.
When a next-hop is detected as no longer reachable due to ARP/Neighbor Cache expiry, the route’s next-hop is set as unreachable to prevent the SR from sending continuous ARPs/Neighbor Solicitations triggered by traffic destined for the static route prefix. When the next-hop is detected as reachable via ARP or Neighbor Advertisements, the state of the next-hop is set back to valid.
2.4.8.1. Invalidate Next-Hop Based on IPV4 ARP
This feature invalidates a static route based on the reachability of the next-hop in the ARP cache when the validate-next-hop command is enabled within the static-route-entry>next-hop context for an IPv4 static route.
In this case, when the ARP entry for the next-hop is INVALID or not populated, the static route must remain invalid/inactive. When an ARP entry for the next-hop is populated based on a gratuitous ARP received or periodic traffic destined for it and the usual ARP who-has procedure, the static route becomes valid/active and is installed.
2.4.8.2. Invalidate Next-Hop Based on Neighbor Cache State
This feature invalidates a static route based on the reachability of the next-hop in the neighbor cache when the validate-next-hop command is enabled within the static-route-entry>next-hop context for an IPv6 static route.
In this case, when the Neighbor Cache entry for next-hop is INVALID or not populated, the static route must remain invalid/inactive. When an NC entry for next-hop is populated based on a neighbor advertisement received, or periodic traffic destined for it and the usual NS/NA procedure, the static route becomes valid/active and is installed.
2.4.9. LDP Shortcut for IGP Route Resolution
This feature enables you to forward user IP packets and specified control IP packets using LDP shortcuts over all network interfaces in the system that participate in the IS-IS and OSPF routing protocols. The default is to disable the LDP shortcut across all interfaces in the system.
config>router>ldp-shortcut [ipv4] [ipv6]
2.4.9.1. IGP Route Resolution
When LDP shortcut is enabled, LDP populates the RTM with next-hop entries corresponding to all prefixes for which it activated an LDP FEC. For an activated prefix, two route entries are populated in RTM. One corresponds to the LDP shortcut next-hop and has an owner of LDP. The other one is the regular IP next-hop. The LDP shortcut next-hop always has preference over the regular IP next-hop for forwarding user packets and specified control packets over a specific outgoing interface to the route next-hop.
The prior activation of the FEC by LDP is done by performing an exact match with an IGP route prefix in RTM. It can also be done by performing a longest prefix match with an IGP route in RTM if the aggregate-prefix-match option is enabled globally in LDP ldp-interarea-prd.
The LDP next-hop entry is not exported to the LDP control plane or to any other control plane protocols except OSPF, IS-IS, and an OAM control plane specified in Handling of Control Packets.
This feature is not restricted to /32 IPv4 prefixes or /128 IPv6 FEC prefixes. However, only /32 IPv4 and /128 IPv6 FEC prefixes will be populated in the tunnel table for use as a tunnel by services.
All user and specified control packets for which the longest prefix match in RTM yields the FEC prefix will be forwarded over the LDP LSP. The following is an example of the resolution process.
Assume that the egress LER advertised a FEC for some /24 prefix using the fec-originate command. At the ingress LER, LDP resolves the FEC by checking in RTM that an exact match exists for this prefix. After the LDP activates the FEC, it programs the NHLFE in the egress data path and the LDP tunnel information in the ingress data path tunnel table.
Next, LDP provides the shortcut route to RTM, which will associate it with the same /24 prefix. There will be two entries for this /24 prefix: the LDP shortcut next-hop and the regular IP next-hop. The latter was used by LDP to validate and activate the FEC. RTM then resolves all user prefixes that succeed a longest prefix match against the /24 route entry to use the LDP LSP.
Now assume that the aggregate-prefix-match was enabled and that LDP found a /16 prefix in RTM to activate the FEC for the /24 FEC prefix. In this case, RTM adds a new, more-specific route entry of /24 and has the next-hop as the LDP LSP. However, RTM will still not have a specific /24 IP route entry. RTM then resolves all user prefixes that succeed a longest prefix match against the /24 route entry to use the LDP LSP. All other prefixes that succeed a longest prefix match against the /16 route entry will use the IP next-hop. LDP shortcut will also work when using RIP for routing.
2.4.9.2. LDP-IGP Synchronization
See the 7450 ESS, 7750 SR, 7950 XRS, and VSR MPLS Guide for information about LDP-IGP Synchronization.
2.4.9.3. LDP Shortcut Forwarding Plane
After the LDP activates an FEC for a prefix and programs RTM, it also programs the ingress tunnel table in IOM or on linecards with the LDP tunnel information.
When an IPv4 packet is received on an ingress network interface, a subscriber IES interface, or a regular IES interface, the lookup of the packet by the ingress IOM or linecard will result in the packet being sent labeled with the label stack corresponding to the NHLFE of the LDP LSP when the preferred RTM entry corresponds to an LDP shortcut.
If the preferred RTM entry corresponds to an IP next-hop, the IPv4 packet is forwarded unlabeled.
The switching from the LDP shortcut next-hop to the regular IP next-hop when the LDP FEC becomes unavailable depends on whether the next-hop is still available. If it is (for example, the LDP FEC was withdrawn due to LDP control plane issues) the switchover should be faster. If the next-hop determination requires IGP to re-converge, this will take longer. However, no target is set.
The switching from a regular IP next-hop to an LDP shortcut next-hop will usually occur only when both are available. However, the programming of the NHLFE by LDP and the programming of the LDP tunnel information in the ingress IOM or linecards tunnel table are asynchronous. If the tunnel table is configured first, it is possible that traffic will be black-holed for some time.
2.4.9.4. ECMP Considerations
When ECMP is enabled and multiple equal-cost next-hops exist for the IGP route, the ingress IOM or linecard will spray the packets for this route based on the hashing routine currently supported for IPv4 packets.
When the preferred RTM entry corresponds to an LDP shortcut route, spraying will be performed across the multiple next-hops for the LDP FEC. The FEC next-hops can either be direct link LDP neighbors or T-LDP neighbors reachable over RSVP LSPs, in the case of LDP-over-RSVP, but not both. This is as per ECMP for LDP.
When the preferred RTM entry corresponds to a regular IP route, spraying will be performed across regular IP next-hops for the prefix.
Spraying across regular IP next-hops and LDP-shortcut next-hops concurrently is not supported.
2.4.9.5. Handling of Control Packets
All control plane packets will not see the LDP shortcut route entry in RTM with the exception of the following control packets, which will be forwarded over an LDP shortcut when enabled:
- A locally generated or in transit ICMP ping and trace route of an IGP route. The transit message appears as a user packet to the ingress LER node.
- A locally generated response to a received ICMP ping or trace route message.
All other control plane packets that require an RTM lookup and knowledge of which destination is reachable over the LDP shortcut will continue to be forwarded over the IP next-hop route in RTM.
2.4.9.6. Handling of Multicast Packets
Multicast packets cannot be forwarded or received from an LDP LSP. This is because there is no support for the configuration of such an LSP as a tunnel interfaces in PIM. Only an RSVP P2MP LSP is currently allowed.
If a multicast packet is received over the physical interface, the uRPF check will not resolve to the LDP shortcut because the LDP shortcut route in RTM is not made available to multicast application.
2.4.9.7. Interaction with BGP Route Resolution to an LDP FEC
There is no interaction between an LDP shortcut for BGP next-hop resolution and the LDP shortcut for IGP route resolution. BGP will continue to resolve a BGP next-hop to an LDP shortcut if the user enabled the following option in BGP:
2.4.9.8. Interaction with Static Route Resolution to an LDP FEC
A static route will continue to be resolved by searching an LDP LSP whose FEC prefix matches the specified indirect next-hop for the route. In contrast, the LDP shortcut for IGP route resolution uses the LDP LSP as a route. The most specific route for a prefix will be selected and, if both a static and IGP routes exist, the RTM route type preference will be used to select one.
2.4.9.9. LDP Control Plane
For the LDP shortcut to be usable, SR OS must originate a <FEC, label> binding for each IGP route it learns of even if it did not receive a binding from the next-hop for that route. The router must assume that it is an egress LER for the FEC until the route disappears from the routing table or the next-hop advertises a binding for the FEC prefix. In the latter case, SR OS becomes a transit LSR for the FEC.
SR OS will originate a <FEC, label> binding for its system interface address only by default. The only way to originate a binding for local interfaces and routes that are not local to the system is by using the fec-originate capability.
You must use the fec-originate command to generate bindings for all non-local routes for which this node acts as an egress LER for the corresponding LDP FEC. Specifically, this feature must support the FEC origination of IGP learned routes and subscriber/host routes statically configured or dynamically learned over subscriber IES interfaces.
An LDP LSP used as a shortcut by IPv4 packets may also be tunneled using the LDP-over-RSVP feature.
2.5. Weighted Load-Balancing over Interface Next-hops
When the weighted-ecmp command is configured in the base router context (config>router) or a VPRN (config>service>vprn), any IPv4 or IPv6 static or IS-IS route associated with the routing instance can be programmed into the datapath to use weighted load-balancing across the interface next-hops of the route.
In order for weighted ECMP to be supported across the interface next-hops of an IS-IS route the following conditions must be met.
- All of the calculated ECMP next-hops must be interface next-hops.
- All of the calculated ECMP next-hops must be associated with the same neighbor IS-IS router.
- All of the calculated ECMP next-hop interfaces must have a non-zero load-balancing-weight value configured in the isis>interface context. By default, IS-IS interfaces have a zero weight (no load-balancing-weight); non-zero values must be configured explicitly. Values cannot be auto-derived.
In order for weighted ECMP to be supported across the interface next-hops of a static route the following conditions must be met.
- All of the configured ECMP next-hops must be direct next-hops (resolved to an interface). The ECMP next-hops are the next-hops with the lowest preference that also have the lowest metric.
- All of the configured ECMP next-hop interfaces must have a non-zero load-balancing-weight value configured in the static-route-entry>next-hop context. By default, static route next-hops have a zero weight (no load-balancing-weight); non-zero values must be configured explicitly. Values cannot be auto-derived. The ECMP next-hops are the next-hops with the lowest preference that also have the lowest metric.
The load-balancing-weight commands in both the IS-IS and static route configuration trees accept a value between 0 and 4294967295.
If an IPv4 or IPv6 BGP route has a BGP next-hop resolved by a static or IS-IS ECMP route and ibgp-multipath is configured under BGP, traffic forwarded to the BGP next-hop is sprayed according to the load-balancing-weights of the interface next-hops.
2.6. IP-over-GRE and MPLS-over-GRE Termination on a User-Configured Subnet
This feature enables the termination of MPLS-over-GRE and IP-over-GRE packets on destination IP addresses from a user-configured subnet. SR OS supports processing received GRE encapsulated packets concurrently when the destination address in the outer IPv4 header matches the system interface address (exact match) and when it matches an address on the user-configured GRE termination subnet (longest prefix match).
RFC 2890 specifies the following format for the GRE header:
All the fields of the GRE encapsulation in RFC 2890 are optional except for the base header (first 4 bytes). The C, K, and S flags are used to indicate if the header includes the optional fields of Checksum (plus Reserved field), Key, and Sequence Number. SROS can process packets received with the base 4-byte header or with the 8-byte header which includes the Key field. In other words, packets with the flags set to {C=0, K=0/1, S=0}. Any other GRE header setting will result in the packet being dropped.
When originating a GRE encapsulated packet, SR OS supports the following header formats:
- The 4-byte base header {C=0, K=0, S=0} in the IP-over-GRE feature using a Port Cross Connect (PXC) port (see GRE Tunnel Overview).
- The 4-byte base header {C=0, K=0, S=0} in the IP-over-GRE feature using the Multiservice Integrated Service Adapter.Refer to Section 4.1, IP Tunnel Overview, of the 7450 ESS, 7750 SR, and VSR Multiservice Integrated Service Adapter Guide.
- The 4-byte base header {C=0, K=0, S=0} in the MPLS-over-GRE tunnel and SDP.Refer to the 7450 ESS, 7750 SR, 7950 XRS, and VSR Layer 2 Services and EVPN Guide: VLL, VPLS, PBB, and EVPN, the 7450 ESS, 7750 SR, 7950 XRS, and VSR Layer 3 Services Guide: IES and VPRN, and the 7450 ESS, 7750 SR, 7950 XRS, and VSR Services Overview Guide.
- The 8-byte header which includes the Key field {C=0, K=1, S=0} in the filter-based GRE tunneling feature (See Configuring Filter-Based GRE Tunneling).
2.6.1. Feature Configuration
The user defines a subnet for the termination of GRE packets by applying the gre-termination command to a numbered network IP interface, including a loopback interface, using the config>router>interface>gre-termination command.
The following rules apply to termination of IP-over-GRE and MPLS-over-GRE on a user-defined subnet.
- The termination of MPLS-over-GRE on the system interface address can be performed concurrently and extends to terminating IP-over-GRE packets as well.
- A single GRE termination subnet is permitted per router. If the user attempts to configure another subnet on another interface, the command is rejected.
- The GRE termination subnet length can be of maximum size of /16.
- The subnet of the primary IPv4 address of the numbered loopback interface or the numbered network IP interface is used as the GRE termination subnet.
- When the GRE termination subnet is enabled on a numbered network IP interface, the packet can be received from the interface itself and any other network IP interface as long as the target IPv4 termination subnet is reachable.
- The feature can terminate packets with the base 4-byte header {C=0, K=0, S=0} or with the 8-byte header which includes the Key field {C=0, K=1, S=0}. Any other GRE header setting will result in the packet being dropped.
- For routers in the network to forward MPLS-over-GRE or IP-over-GRE packets to this router, the prefix of the GRE subnet must be advertised in IGP or BGP. This is performed by adding the interface to IGP or BGP. Alternatively, a static route is added to the other routers.
- The GRE termination subnet is not supported with the following interface types. If these interface types are configured, the configuration of the gre-termination option is rejected:
- unnumbered network IP interface
- IES interface
- VPRN interface
- CSC VPRN interface
- The configuration of the gre-termination option is also rejected when applied to the system interface, as the system interface supports the termination of MPLS-over-GRE packet on its /32 subnet with no explicit configuration.
- This feature introduces full support of LER and LSR roles for the packet after the GRE encapsulation is removed, regardless if the GRE termination was on the system interface address or the GRE termination subnet.
- In an LSR role, this feature will spray the decapsulated packets over LAG and ECMP links by attempting a hash on the SA/DA and Layer 4 ports of the inner IP header if the payload below the label stack is IPv4 or IPv6. Otherwise, a hash is performed on the SA/DA of the outer IPv4 header of the GRE encapsulation.
2.6.2. MPLS-over-GRE and IP-over-GRE Termination Function
When a GRE packet is received over any network IP interface, the router checks if destination address matches the system interface address (exact match) or the GRE termination subnet (Longest Prefix Match). The router then processes the packet according to the following criteria:
- If a match exists and the GRE Protocol Type field indicates an MPLS payload, continue processing the MPLS label stack as normal. This includes:
- Pop one or more labels and forward to CPM if a MPLS exception exists (TTL expiry, RA label, 127/8 destination address in underlying IP packet).
- Pop one or more labels and look up the packet in the FIB or in a local service context. The router operates as an egress LER.
- Pop one or more labels and swap a label out to the outgoing interface with NHLFE encapsulation pushed on the packet. The router operates as an LSR.
- When the incoming label is swapped to an implicit-null label, the user is able to remark the DSCP field of the exposed IPv4 or IPv6 packet on egress of the data path.
- If a match exists and the GRE Protocol Type field indicates an IPv4 or an IPv6 payload, continue processing in the pipeline as an IP packet and forward out based on FIB lookup.
- If a match exists and the GRE Protocol Type field indicates a Bridged Ethernet payload, drop the packet. To enable the feature to terminate the Bridged Ethernet payload, ensure that the termination subnet for that feature does not overlap with the GRE termination subnet of MPLS-over-GRE and IP-over-GRE termination.
- If a match exists and the GRE protocol Type field is set to any other payload value, drop the packet.
- If a match exists and the packet is not dropped, the application of ACL filter on the incoming interface matches against the inner (payload) header of the received GRE-encapsulated packet.
- If a match does not exist, continue processing in the pipeline as an IPv4 packet. In this case, the application of ACL filter on the incoming interface matches against the outer IPv4 header of the received GRE-encapsulated packet.
This feature supports GRE/IPv4 encapsulation when the payload is MPLS, IPv4, or IPv6.
All MPLS egress LER and LSR features associated with the processed label are supported.
2.6.3. Outgoing Packet Ethertype Setting and TTL Handling in MPLS-over-GRE Termination
The router sets the Ethertype field value of the outgoing packet according to the following criteria.
- If the swapped label is not the Bottom-of-Stack label, Ethertype is set to MPLS value.
- If the swapped label is the Bottom-of-Stack label and the outgoing label is not implicit-null, Ethertype is set to MPLS value.
- If the swapped label is the Bottom-of-Stack label and the outgoing label is implicit-null, Ethertype is set to IPv4 or IPv6 value when the first nibble of the exposed IP packet is 4 or 6 respectively. If the first nibble value is neither 4 nor 6, the packet is dropped.
The router sets the TTL of the outgoing packet as per the behavior of a PHP LSR:
- The TTL of a forwarded IP packet is set to MIN (MPLS_TTL-1, IP_TTL), where MPLS_TTL refers to the TTL in the outermost label in the popped stack and IP_TTL refers to the TTL in the exposed IP header.
- The TTL of a forwarded MPLS packet is set to MIN(MPLS_TTL-1, INNER_MPLS_TTL), where MPLS_TTL refers to the TTL in the outermost label in the popped stack and INNER_MPLS_TTL refers to the TTL in the exposed label.
2.6.4. Ethertype Setting and TTL Handling in IP-over-GRE Termination
The router sets the Ethertype field value of the outgoing packet to IPv4 or IPv6 value when the GRE protocol field value in the incoming packet is IPv4 or IPv6 respectively.
The router checks and decrements the TTL field of the inner IPv4 or IPv6 header and ignores the TTL of the outer IPv4 header.
2.6.5. LER and LSR Hashing Support
When the router removes the GRE encapsulation, pops one or more labels including the Bottom-of-Stack (BoS) label, it acts as a LER. The exposed packet will be forwarded in the global routing table or in a service context. The LAG/ECMP hashing of the packet when forwarded follow the procedures of that specific forwarding context. Refer to LAG and ECMP Hashing in the 7450 ESS, 7750 SR, 7950 XRS, and VSR Interface Configuration Guide.
When the router removes the GRE encapsulation, pops one or more labels and then swaps a label, it acts as an LSR. The LSR hashing for packets of a MPLS-over-GRE SDP or tunnel terminating on the GRE subnet follows a new procedure which is enabled automatically and overrides the LSR hashing option enabled on the incoming network IP interface (lsr-load-balancing {lbl-only | lbl-ip | ip-only | eth-encap-ip | lbl-ip-l4-teid}). For more details, refer to LSR Hashing of MPLS-over-GRE Encapsulated Packet in section Changing Default Per Flow Hashing Inputs of the 7450 ESS, 7750 SR, 7950 XRS, and VSR Interface Configuration Guide.
2.7. GRE Tunnel Overview
This section describes the GRE tunneling feature supported through the use of a Port Cross Connect (PXC) port. In this application, the PXC port functions as a resource module for the system, providing the necessary resources for the GRE encapsulation function. The GRE encapsulation function described here is similar to the GRE tunnel functionality supported through the use of the MS-ISA. In this use case, the MS-ISA is not required.
Figure 14 shows an example of a GRE deployment supported inside a 7750 SR router using the PXC element.
Figure 14: Sample GRE Deployment Using a PXC Port
In Figure 14, the public network is typically an unsecured network, such as public Internet, over which packets belonging to the private network in the diagram cannot be transmitted natively. Inside the 7750 SR, a public service instance (IES or VPRN) connects to the public network, and a private service instance (typically a VPRN) connects to the private network.
For GRE tunnels using PXC ports, the public and private services must be two different services, and the PXC is the connection between the two services. Traffic from the public network may require authentication and encryption inside an IPSec tunnel to reach the private network. In this way, the authenticity, confidentiality, and integrity of private network access can be enforced. If authentication and confidentiality are not required, then access to the private network may be provided through GRE or IP-IP tunnels.
Traffic flows through PXC-based tunnels in the following ways:
- In the upstream direction (public to private), the encapsulated traffic is forwarded to a public tunnel interface if the destination address matches the local or gateway address of a GRE tunnel. As the traffic passes through the PXC port, the tunnel header is removed, the payload IP packet is delivered to the private service, and from there, the traffic is forwarded again based on the destination address of the payload IP packet.
- In the downstream direction (private to public), unencapsulated traffic belonging to the private service is forwarded into the tunnel by matching a route with the GRE tunnel as next-hop. The route can be configured statically, learned by running OSPF on the private tunnel interface or by running BGP over the tunnel. After clear traffic is forwarded to the PXC port, it is encapsulated in the GRE header and passed to the public service, and from there, the traffic is forwarded again based on the destination address of the GRE header.
2.7.1. Sample GRE Tunnel Configurations
Public interface example:
Private interface example:
2.8. Router Interface Encryption with NGE
NGE nodes support Layer 3 encryption on router interfaces for IPv4 traffic. NGE is not supported on dual-stack IPv4/IPv6 or IPv6-only interfaces. Refer to the 7450 ESS, 7750 SR, 7950 XRS, and VSR Services Overview Guide for more information about platforms that support NGE.
NGE is enabled on a router interface by configuring the group-encryption command on the router interface. The interface is considered part of the NGE domain, and any received packets that are NGE-encrypted are decrypted if the key group is configured on the node. To encrypt packets egressing the interface, the outbound key group must be configured on the interface. All IP packets, such as self-generated traffic or packets forwarded from router interfaces that are not inside the NGE domain, are encrypted when egressing the interface. There are some exceptions to this general behavior, as described in the sections below; for example, GRE-MPLS and MPLSoUDP packets are not encrypted when router interface encryption is enabled.
The outbound and inbound key groups configured on the router interface determine which keys are used to encrypt and decrypt traffic. Refer to the 7450 ESS, 7750 SR, 7950 XRS, and VSR Services Overview Guide for more information about configuring key groups.
To perform encryption, router interface encryption reuses the IPSec transport mode packet format as shown in Figure 15.
Figure 15: Router Interface Encryption Packet Format (IPSec Transport Mode)
The protocol field in the IP header of an NGE packet is always set to “ESP”. Within an NGE domain, the SPI that is included in the ESP header is always an SPI for the key group configured on the router interface. Other fields in the IP header, such as the source and destination addresses, are not altered by NGE router interface encryption. Packets are routed through the NGE domain and decrypted when the packet leaves the NGE domain.
The group keys used on an NGE-enabled router interface provide encryption of broadcast and multicast packets within the GRT. For example, OSPF uses a broadcast address to establish adjacencies, which can be encrypted by NGE without the need to establish point-to-point encryption tunnels. Similarly, multicast packets are also encrypted without point-to-point encryption tunnels.
2.8.1. NGE Domains
An NGE domain is a group of nodes and router interfaces forming a network that uses a single key group to create a security domain. NGE domains are created when router interface encryption is enabled on router interfaces that need to participate in the NGE domain. The NSP NFM-P assists operators in managing the nodes and interfaces that participate in the NGE domain. See the NSP NFM-P User Guide for more information.
Figure 16 shows various traffic types crossing an NGE domain.
Figure 16: NGE Domain Transit
In Figure 16, nodes A, B, C, and D have router interfaces configured with router interface encryption enabled. Traffic is encrypted when entering the NGE domain using the key group configured on the router interface and is decrypted when exiting the NGE domain. Traffic may traverse multiple hops before exiting the NGE domain, yet decryption only occurs on the final node when the traffic exits the NGE domain.
Various traffic types are supported and encrypted when entering the NGE domain, as illustrated by the following items on node A in Figure 16:
- item 1: self-generated packets — these packets, which include all types of control plane and management packets such as OSPF, BGP, LDP, SNMPv3, SSH, ICMP, RSVP-TE, and 1588, are encrypted
- item 2: user Layer 3 and VXLAN packets — any Layer 3 user packets that are routed into the NGE domain from an interface outside the NGE domain are encrypted. Any VXLAN packets that are routed into the NGE domain from this NGE node are encrypted.
- item 3: IPSec packets — IPSec packets are NGE-encrypted when entering the NGE domain to ensure that the IPSec packets’ security association information does not conflict with the NGE domain
GRE-MPLS- or MPLSoUDP-based service traffic consists of Layer 3 packets, and router interface NGE is not applied to these types of packets. Instead, service-level NGE is used for encryption to avoid double-encrypting these packets and impacting throughput and latencies. The two types of GRE-MPLS or MPLSoUDP packets that can enter the NGE domain are illustrated by items 4 and 5 in Figure 16.
- item 4: GRE-MPLS and MPLSoUDP packets (SDP or VPRN) with service-level NGE enabled — these encrypted packets use the key group that is configured on the service. The services key group may be different from the key group configured on the router interface where the GRE-MPLS or MPLSoUDP packet enters the NGE domain.
- item 5: GRE-MPLS and MPLSoUDP packets (SDP or VPRN) with NGE disabled — these packets are not encrypted and can traverse the NGE domain in clear text. If these packets require encryption, SDP or VPRN encryption must be enabled.
Creating an NGE domain from the NSP NFM-P requires the operator to determine the type of NGE domain being managed. This will indicate whether NGE gateway nodes are required to manage the NGE domain, and other operational considerations. The two types of NGE domains are:
2.8.1.1. Private IP/MPLS Network NGE Domain
One type of NGE domain is a private IP/MPLS network, as shown in Figure 17.
Figure 17: Private IP/MPLS Network NGE Domain
In a private IP/MPLS network NGE domain, all interfaces are owned by the operator and there is no intermediary service provider needed to interconnect nodes. Each interface is a point-to-point private link between private nodes. When a new node is added to this type of NGE domain (node D in Figure 17), the links that connect node D to the existing nodes in the NGE domain (nodes A, B, and C) must be enabled with NGE router interface encryption. Links from the new node to the existing nodes are enabled one at a time. The NSP NFM-P provides tools that simplify adding nodes to the NGE domain and enabling NGE on their associated interfaces. In this type of NGE domain, each interface is a direct link between two nodes and is not used to communicate with multiple nodes over a broadcast medium offered by an intermediary network. Also, there are no NGE gateway nodes required between the NSP NFM-P and new nodes entering the NGE domain.
2.8.1.2. Private Over Intermediary Network NGE Domain
The other type of NGE domain is a private IP/MPLS network that traverses an intermediary network NGE domain; the intermediary network is used to interconnect nodes in the NGE domain using a multipoint-to-multipoint service. The intermediary network is typically a service provider network that provides a private IP VPN service or a private VPLS service used to interconnect a private network that does not mimic point-to-point links as described in the Private IP/MPLS Network NGE Domain section.
This type of NGE domain is shown in Figure 18.
Figure 18: Private Over Intermediary Network NGE Domain
Private over intermediary network NGE domains have nodes with links that connect to a service provider network where a single link can communicate with multiple nodes over a Layer 3 service such as a VPRN. In Figure 18, node A has NGE enabled on its interface with the service provider and uses that single interface to communicate with nodes B and C, and eventually with node D when node D has been added to the NGE domain. This type of NGE domain requires the recognition of NGE gateway nodes that allow the NSP NFM-P to reach new nodes that enter the domain. Node C is designated as a gateway node.
When node D is added to the NGE domain, it must first have the NGE domain key group downloaded to it from the NSP NFM-P. The NSP NFM-P creates an NGE exception ACL on the gateway node, C, to allow communication with node D using SNMPv3 and SSH through the NGE domain. After the key group is downloaded, the NSP NFM-P enables router interface encryption on node D’s interface with the service provider and node D is now able to participate in the NGE domain. The NSP NFM-P automatically removes the IP exception ACL from node C when node D enters the NGE domain.
See Router Interface NGE Domain Concepts for more information.
2.8.2. Router Interface NGE Domain Concepts
An NGE domain is a group of nodes whose router interfaces in the base routing context (GRT) are enabled for router interface NGE. An interface without router interface NGE enabled is considered to be outside the NGE domain. NGE domains use only one key group when the domain is created; however, two key groups may be active at once if some links within the NGE domain are in transition from one key group to the other.
Figure 19 illustrates the NGE domain concept. Table 6 describes the three configuration scenarios inside the NGE domain.
Figure 19: Inside and Outside NGE Domains
Table 6: Inside and Outside NGE Domains — Configuration Scenarios
Key | Description |
1 | NGE enabled, no inbound/outbound key group Outbound packets are sent without encrypting. Inbound packets can be NGE-encrypted or clear text. |
2 | Outbound key group, no inbound key group Outbound packets are encrypted using the interface key group if not already encrypted. Inbound packets can be NGE-encrypted or clear text. |
3 | Inbound and outbound key group Outbound packets are encrypted using the interface key group if not already encrypted. Inbound packets must be encrypted using the interface key group keys. |
4 | Outside the NGE domain, the interface is not configured for NGE. Any ESP packets are IPSec packets. |
A router interface is considered to be inside the NGE domain when it has been configured with group-encryption on the interface. When group-encryption is configured on the interface, the router can receive unencrypted packets or NGE-encrypted packets from any configured key group on the router, but any other type of IPSec-formatted packet is not allowed. If an IPSec-formatted packet is received on an interface that has group-encryption enabled, it will not pass NGE authentication and will be dropped. Therefore, IPSec packets cannot exist within the NGE domain without first being converted to NGE packets. This conversion requirement delineates the boundary of the NGE domain and other IPSec services.
When NGE router interface encryption is enabled and only an outbound key group is configured, the interface can receive unencrypted packets or NGE-encrypted packets from any configured key group on the router. All outbound packets are encrypted using the outbound key group if the packet was not already encrypted further upstream in the network.
When NGE router interface encryption has been configured with both an inbound and outbound key group, only NGE packets encrypted with the key group security association can be sent and received over the interface.
When there is no NGE router interface encryption, the interface is considered outside the NGE domain where NGE is not applied.
Refer to the “NGE Packet Overhead and MTU Considerations” section in the 7450 ESS, 7750 SR, 7950 XRS, and VSR Services Overview Guide for MTU information related to enabling NGE on a router interface.
2.8.3. GRE-MPLS and MPLSoUDP Packets Inside the NGE Domain
NGE router interface encryption is never applied to GRE-MPLS or MPLSoUDP packets, for example:
- GRE with the GRE protocol ID set to MPLS Unicast (0x8847) or Multicast (0x8848)
- UDP packets with destination port = 6635)
GRE-MPLS and MPLSoUDP packets that enter the NGE domain or transit the NGE domain are forwarded as is.
Because these GRE-MPLS and MPLS-oUDP packets provide transport for MPLS-based services, they already use the NGE services-based encryption techniques for MPLS, such as SDP or VPRN-based encryption. To avoid double encryption, the packets are left in clear text when entering an NGE domain or crossing intermediate nodes in the NGE domain, and are forwarded as needed when exiting an NGE domain.
2.8.4. EVPN-VXLAN Tunnels and Services
NGE router interface encryption does not differentiate between EVPN-VXLAN tunnels and other L3 traffic, and therefore encrypts all EVPN-VXLAN traffic that egresses the node.
For received encrypted EVPN-VXLAN packets, if the VXLAN tunnel terminates on the node (that is, the destination IP is for a VTEP on this node), then the NGE packet is decrypted and the EVPN-VXLAN traffic is processed as if NGE encryption never took place.
2.8.5. Router Encryption Exceptions using ACLs
In some cases, Layer 3 packets may need to cross the NGE domain in clear text, such as when an NGE-enabled router needs to peer with a non-NGE-capable router to exchange routing information. This can be accomplished by using a router interface NGE exception filter applied on the router interface for the required direction, inbound or outbound.
Figure 20 shows the use of a router interface NGE exception filter.
Figure 20: Router Interface NGE Exception Filter Example
The inbound or outbound exception filter is used to allow specific packet flows through the NGE domain in clear text, where there is an explicit inbound and outbound key group configured on the interface. The behavior of the exception filter for each router interface configuration is as follows:
- NGE enabled, no inbound/outbound key group — in this scenario, the router does not encrypt outbound traffic, and so the outbound exception filter is not applied. The router can still receive inbound NGE packets, so the exception filter is applied to inbound packets. If the filter detects a match, clear text packets can be received and forwarded by the router.
- outbound key group, no inbound key group — the outbound exception filter is applied to outbound traffic, and packets that match the filter are not encrypted on egress. The router can receive inbound NGE packets without an inbound key group set and applies the exception filter to inbound packets. If the filter detects a match, clear text packets can be received and forwarded by the router.
- inbound and outbound key group — the inbound and outbound exception filters are applied, and any packets that match are passed in clear text.
2.8.6. IPSec Packets Crossing an NGE Domain
IPSec packets can cross the NGE domain because they are still considered Layer 3 packets. To avoid confusion between the security association used in an IPSec packet and the one used in a router interface NGE packet, the router will always apply NGE to any IPSec packet that traverses the NGE domain.
IPSec packets that originate from a router within the NGE domain are not allowed to enter the NGE domain. The only exception to this restriction is OSPFv3 packets.
Figure 21 shows how IPSec packets can transit an NGE domain.
Figure 21: IPSec Packets Transiting an NGE Domain

An IPSec packet enters the router from outside the NGE domain. When the router determines that the egress interface to route the packet is inside an NGE domain, it will select an NGE router interface with one of the following configurations.
- NGE enabled with no inbound or outbound key group configured — this link cannot forward the IPSec packet without adding the NGE ESP, but since nothing is configured for the outbound key group, the packet must be dropped.
- NGE enabled with outbound key group configured and no inbound key group configured — the packet originates outside the NGE domain, so the router adds an ESP header over the existing ESP and encrypts the payload using the NGE domain keys for the configured outbound key group.
- NGE enabled with both inbound and outbound key groups configured — the packet originates outside the NGE domain, so the router adds an ESP header over the existing ESP and encrypts the payload using the NGE domain keys for the configured outbound key group.
OSPFv3 IPSec support also uses IPSec transport mode packets. These packets originate from the CPM, which is considered outside the NGE domain; however, the above rules for encapsulating the packets with an NGE ESP apply and allow these packets to successfully transit the NGE domain.
2.8.7. Multicast Packets Traversing the NGE Domain
Multicast packets that traverse an NGE domain can be categorized into two main scenarios:
- Scenario 1 — multicast packets that ingress the router on an interface that is outside the NGE domain. These packets can egress a variety of interfaces that are either inside or outside the NGE domain.
- Scenario 2 — multicast packets that ingress the router on an interface that is inside the NGE domain. These packets can egress a variety of interfaces that are either inside or outside the NGE domain. This scenario has two cases:
- Scenario 2a — the ingress multicast packet is not yet NGE-encrypted
- Scenario 2b — the ingress multicast packet is NGE-encrypted
Figure 22 shows these scenarios.
Figure 22: Processing Multicast Packets
Multicast packets received from outside the NGE domain (Scenario 1) are processed similarly to multicast packets received from inside the NGE domain (Scenarios 2a and 2b).
The processing rule is that multicast packets are always forwarded as clear text over the fabric. This means that for Scenario 2b, when a multicast packet is received on an encryption-capable interface and is NGE-encrypted, the packet is always decrypted first so that it can be processed in the same way as packets in Scenarios 1 and 2a.
On egress, the following scenarios apply:
- egressing an interface outside the NGE domain — packets are processed in the same way as any multicast packets forwarded out a non-NGE interface
- egressing an NGE router interface and no inbound or outbound key group is configured — the router forwards these packets out from the egress interface without encrypting them since there is no outbound key group configured. This behavior also applies to unicast packets in the same scenario.
- egressing an NGE router interface with the outbound key group configured — the router encrypts the multicast packet using the SPI keys of the outgoing SA configured in the key group. This behavior also applies to unicast packets in the same scenario.
2.8.8. Assigning Key Groups to Router Interfaces
Assigning key groups to router interfaces involves the following three steps:
- Enable NGE with the group-encryption command.
- Configure the outbound key group.
- Configure the inbound key group.
Step 1 is required so that the router can initialize and differentiate the interface for NGE traffic before accepting or sending NGE packets. This assigns the interface to an NGE domain.
Assigning key groups to a router interface in steps 2 and 3 is similar to assigning key groups to SDPs or VPRN-based services. An outbound key group cannot be configured for a router interface without first enabling group-encryption.
When group-encryption is enabled and no inbound key group is configured, the router will accept NGE Layer 3 packets that were encrypted using keys from any security association configured in any key group on the system. If the packet specifies a security association that is not configured in any key group on the node, the packet is dropped.
The outbound key group references the key group to use when traffic egresses the router on the router interface. The inbound key group is used to make sure ingress traffic is using the correct key group on the router interface. If ingress traffic is not using the correct key group, the router counts these packets as errors.
2.8.9. NGE and BFD Support
When NGE is enabled on a router interface, BFD packets that originate from the network processor on the adapter card or from the system are encrypted in the same way as BFD packets that are generated by the CPM.
2.8.10. NGE and ACL Interactions
When NGE is enabled on a router interface, the ACL function is applied as follows:
- on ingress — Normal ACLs are applied to traffic received on the interface that could be either NGE-encrypted or clear text. For NGE-encrypted packets, this implies that only the source, destination, and IP options are available to filter on ingress, as the protocol is ESP and the packet is encrypted. If an IP exception ACL is also configured on the interface, the IP exception ACL is applied first to allow any clear text packets to ingress as needed. After the IP exception ACL is applied and if another filter or ACL is configured on the interface, the other filter will process the remaining packet stream (NGE-encrypted and IP exception ACL packets), and other ACL functions such as PBR or Layer 4 information filtering could be applied to any clear text packets that passed the exception ACL.
- on egress — ACLs are applied to packets before they are NGE-encrypted as per normal operation without NGE enabled.
2.8.11. Router Interface NGE and ICMP Interactions Over the NGE Domain
Typically, ICMP works as expected over an NGE domain when all routers participating in the NGE domain are NGE-capable; this includes running an NGE domain over a private IP/MPLS network. When an ICMP message is required, the NGE packet is decrypted first and the original packet is restored to create a detailed ICMP message using the original packet’s header information.
When the NGE domain crosses a Layer 3 service provider, or crosses over routers that are not NGE-aware, it is not possible to create a detailed ICMP message using the original packet’s information, as the NGE packet protocol is always set to ESP. Furthermore, the NGE router that receives these ICMP messages will drop them because the messages are not NGE-encrypted.
The combination of dropping ICMP messages at the NGE border node and the missing unencrypted packet details in the ICMP information can cause problems with diagnosing network issues.
To help with diagnosing network issues, additional statistics are available on the interface to show whether ICMP messages are being returned from a foreign node. The following statistics are included in the group encryption NGE statistics for an interface:
- Group Enc Rx ICMP DestUnRch Pkts
- Group Enc Rx ICMP TimeExc Pkts
- Group Enc Rx ICMP Other Pkts
These statistics are used when clear text ICMP messages are received on an NGE router interface. The Invalid ESP statistics are not used in this situation even though the packet does not have a correct NGE ESP header. If there is no ingress exception ACL configured on the interface to allow the ICMP messages to be forwarded, the messages are counted and dropped.
If more information is required for these ICMP messages, such as source or destination address information, a second ICMP filter can be configured on the interface to allow logging of the ICMP messages. If the original packet information is also required, an egress exception ACL can be configured with the respective source or destination address information, or other criteria, to allow the original packet to enter the NGE domain in clear text and determine which flows are causing the ICMP failures.
2.8.12. 1588v2 Encryption With NGE
If a router interface is enabled for encryption and Layer 3 1588v2 packets are sent, they will be encrypted using NGE. This means that if port timestamping is enabled on a router interface with NGE, the port timestamp is applied to the Layer 3 1588v2 packet using software-based timestamping instead of hardware-based timestamping, and consequently, timing accuracy may degrade. The exact level of timing or synchronization degradation is dependent on many factors, and testing is recommended to measure any impact.
If there is a need to support Layer 3 1588v2 with better accuracy for frequency or better time using port timestamping, an NGE exception ACL is required to keep the Layer 3 1588v2 packets in clear text. The exception ACL must enable UDP packets with destination port 319 to be sent in clear text.
2.9. Process Overview
The following items are components to configure basic router parameters:
- Interface — A logical IP routing interface. When created, attributes like an IP address, port, link aggregation group, or the system can be associated with the IP interface.
- Address — The address associates the device’s system name with the IP system address. An IP address must be assigned to each IP interface.
- System interface — This creates an association between the logical IP interface and the system (loopback) address. The system interface address is the circuitless address (loopback) and is used by default as the router ID for protocols such as OSPF and BGP.
- Router ID — (Optional) The router ID specifies the router's IP address.
- Autonomous system — (Optional) An autonomous system (AS) is a collection of networks that are subdivided into smaller, more manageable areas.
- Confederation — (Optional) Creates confederation-autonomous systems within an AS to reduce the number of IBGP sessions required within an AS.
2.10. Configuration Notes
The following information describes router configuration requirements:
- A system interface and associated IP address must be specified.
- Boot options file (BOF) parameters must be configured before configuring router parameters.
- Confederations can be configured before protocol connections (such as BGP) and peering parameters are configured.
- IPv6 interfaces and associated routing protocols may only be configured on the following systems:
- 7950 XRS systems
- 7750 SR chassis systems
- 7750 SR-a chassis systems
- 7750 SR-e chassis systems
- 7450 ESS systems running in mixed-mode with IPv6 functionality limited to those interfaces on slots with 7750 IOM3-XPs/IMMs (or later) line cards.
- 7750 SR-c4/12.