Figure: NSP Ecosystem Redundancy illustrates the NSP ecosystem and the provision of redundancy across two separate sites. This is referred to as Disaster Recovery (DR) and is also sometimes referred to as geo-redundancy.
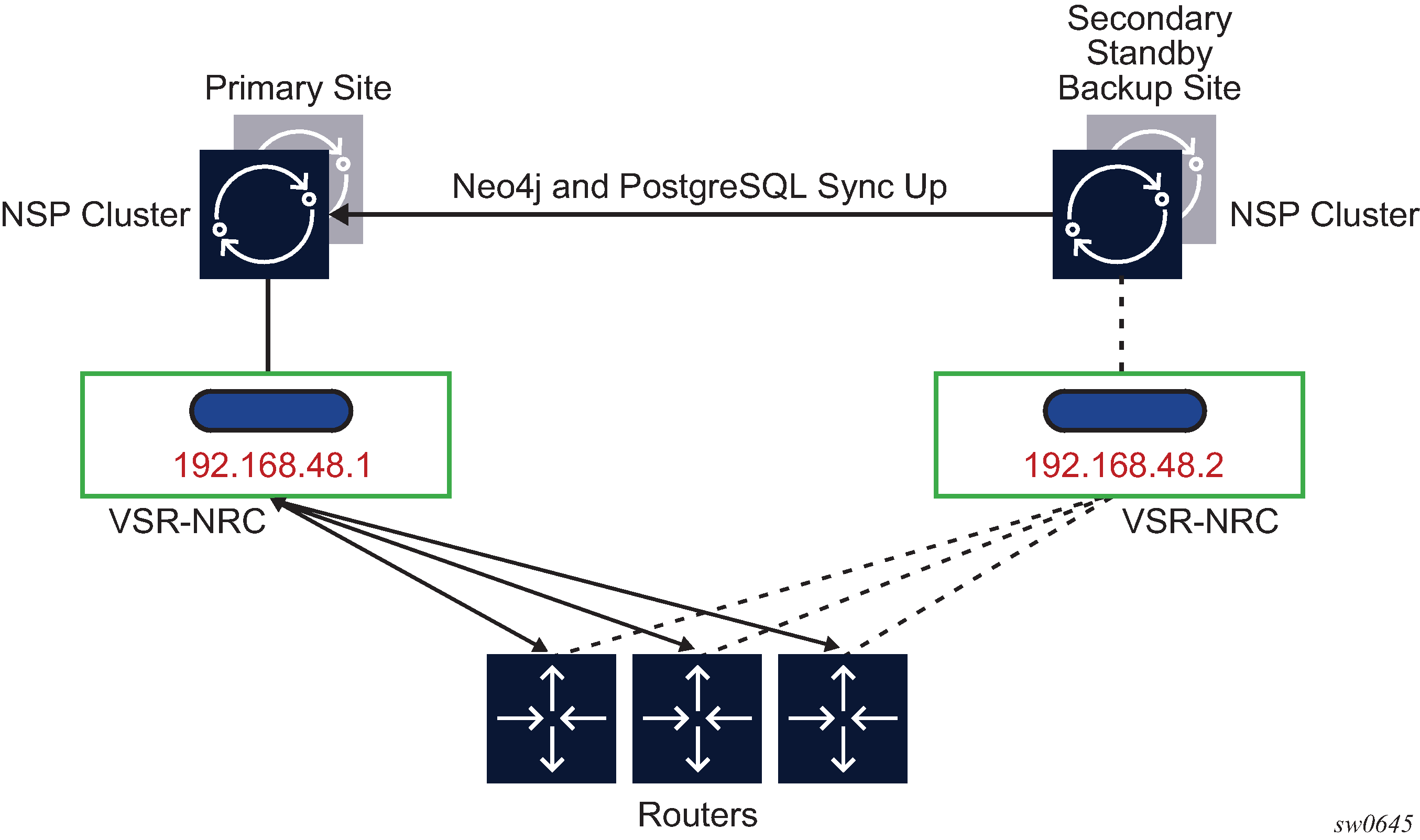
NSP ecosystem redundancy consists of two mechanisms that can be deployed separately or together:
High-Availability (HA) at a single site
the NSP, where the applications reside, is protected by a cluster of three Virtual Machines (VMs)
the VSR-NRC module, which implements PCEP, OpenFlow, and BGP-LS/IGP, does not support HA and is deployed with a single VM that contains the combined CPM and IOM codes
DR, which consists of a primary site and a secondary standby backup site. Each site consists of an NSP cluster and a VSR-NRC VM complex. A heartbeat protocol runs between the NSP clusters at the primary site and the standby backup site.
The VSR-NRC can be deployed as a standalone configuration; however, the NSP must be deployed in a cluster at each site. This configuration is also referred to as a 3+3 deployment.
Each parent NSP cluster establishes a reliable TCP session with a virtual IP to the local VSR-NRC. The TCP session runs an internal protocol, also known as cproto. This configuration is done prior to system startup and cannot be changed with an active NSP; the NSP must be shut down for any changes.