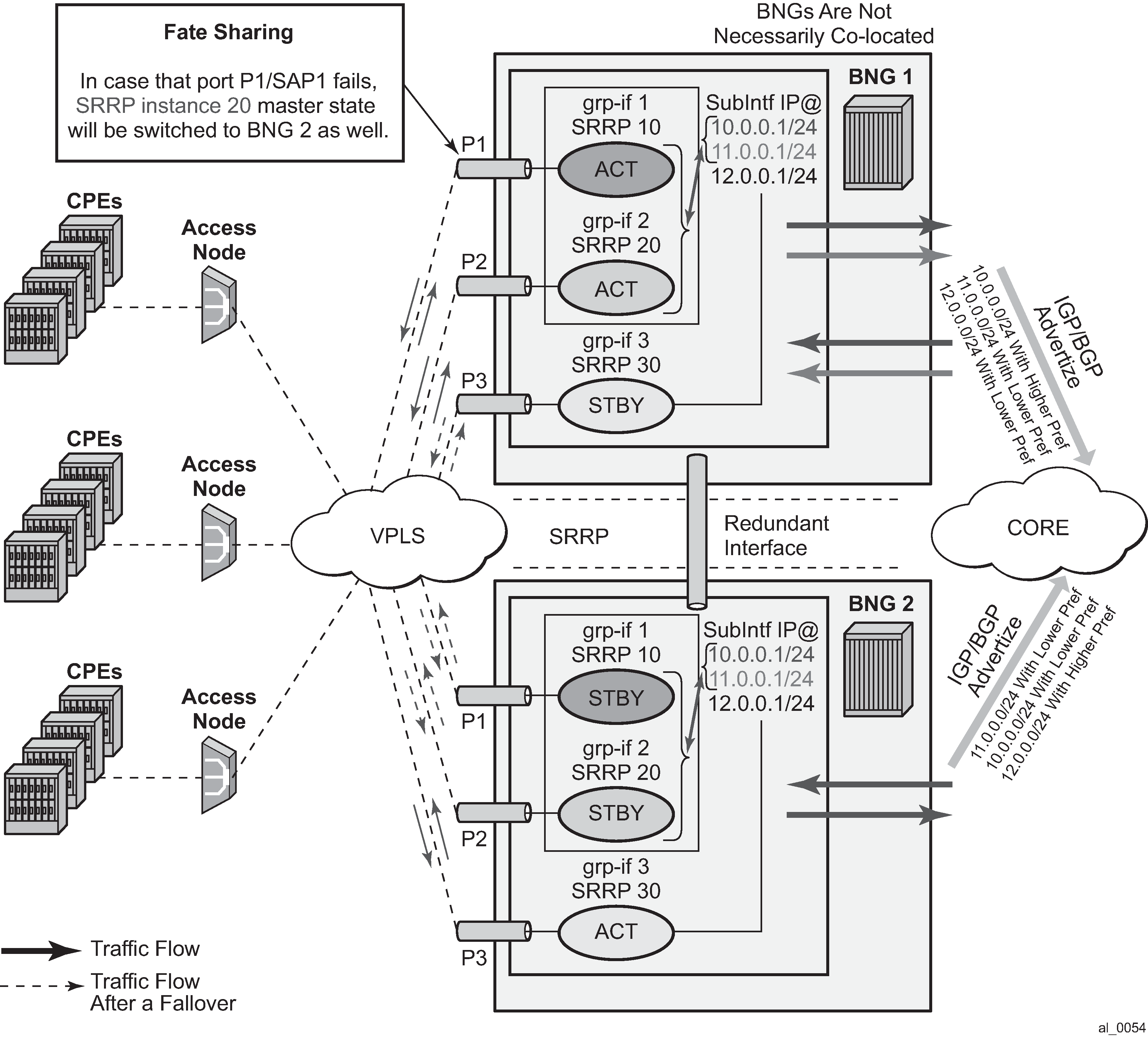
SRRP Fate Sharing is a concept in which a group of SRRP instances track a single operational-object composed of SRRP messaging SAPs. The SRRP instances behave as one (in the single failure case) with regards to SRRP state (init/master/backup). The group of SRRP instances that are sharing fate on a paired node are referred as a Fate Sharing Group (FSG).
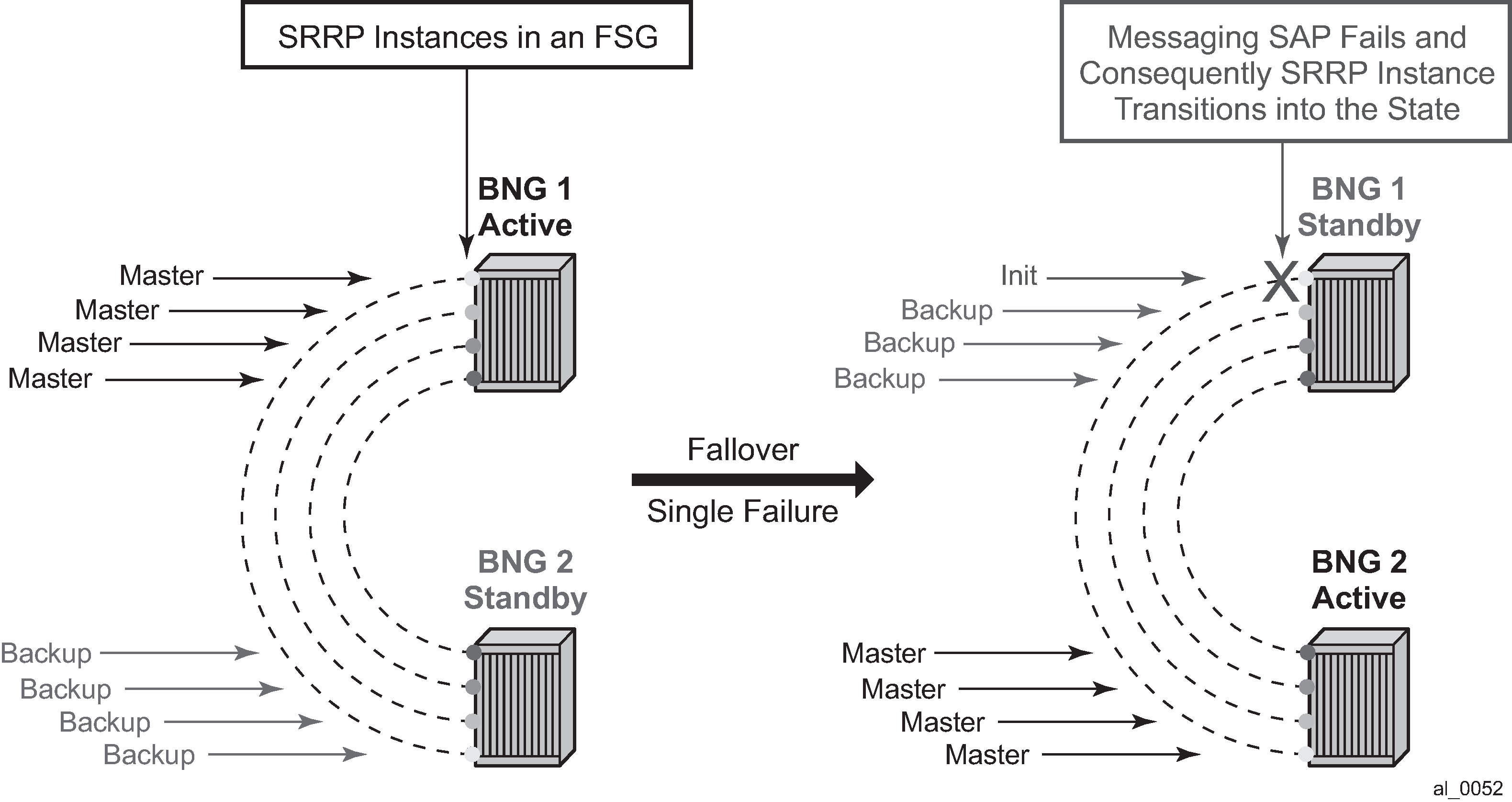
Transition of a single messaging SAP within the FSG into a DOWN state forces the SRRP instance on top of it into the INIT state. Consequently, all other SRRP instances within the same FSG transitions into a Backup state. In other words, SRRP instances within the FSG all share the same fate as the failed SRRP instance as shown in Figure: FSG — single network failure. SRRP Fate Sharing provides optimal protection in the context of a single failure in the network.
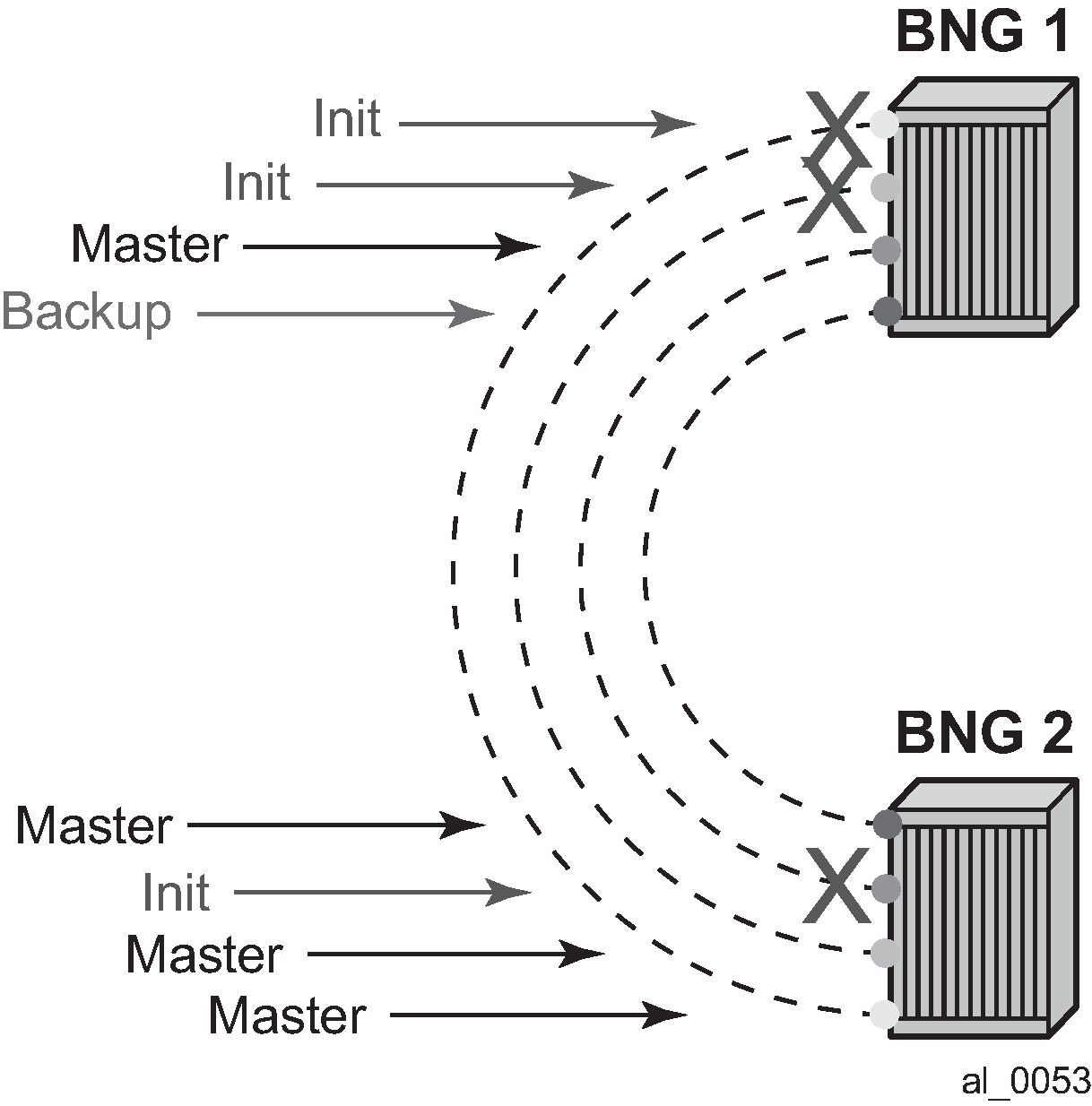
In the event of multiple network failures, the concept of the FSG breaks as there is a possibility that a ‛FSG’ contains SRRP instances that are in any of the three possible SRRP states: master, backup, or init. This Fate Sharing feature may not provide optimal protection when there are multiple network failures distributed over both redundant nodes.
The whereabouts of the failure in the network path that SRRP is designed to monitor are not always clearly reflected through SRRP states. For example, if the network failure is somewhere in the aggregation network beyond the direct reach of our BNG, SRRP instances on both BNG nodes can reach the SRRP master state. This is a faulty condition and the reason why solely monitoring of the SRRP states is not enough to protect against failures. On the other hand, the SRRP messaging SAP states are more indicative of the network failure because they can be tied into Eth-OAM.
After a single network failure is detected and as a result an SRRP instance transitions into a non-master state, the remaining SRRP instances in the FSG are forced into a backup state. This is achieved by changing the priority of each individual SRRP instance in the FSG.
When there are simultaneous multiple failures (multiple ports fail at the same time), it is possible that the SRRP instances within the FSG settle in any of the three possible SRRP states: Master, Backup, or Init. In such scenario, shunted traffic ensues.
In the premise of SRRP Fate Sharing, the network failure is reflected in the operational state of the messaging SAP over which SRRP runs. This is the case if the failure is localized to the BNG (somewhere on the directly connected link). In the case of non-localized failure (beyond the direct reach of the BNG node), Eth-OAM may be needed in to detect the remote end failure and consequently bring the SAP operationally into a DOWN state.
After the single network failure is detected, all instance within the FSG transitions into an SRRP non-Master state.
If there are no failures in the network, all SAPs are UP and SRRP instances within the FSG are in a homogeneous and deterministic state based on their configured priorities.
Failure Detection in a Fate Sharing Group
-
Dual homing over directly connected ports. No Eth-OAM is needed, AN is directly connected to the BNG.
Figure: Scenario 1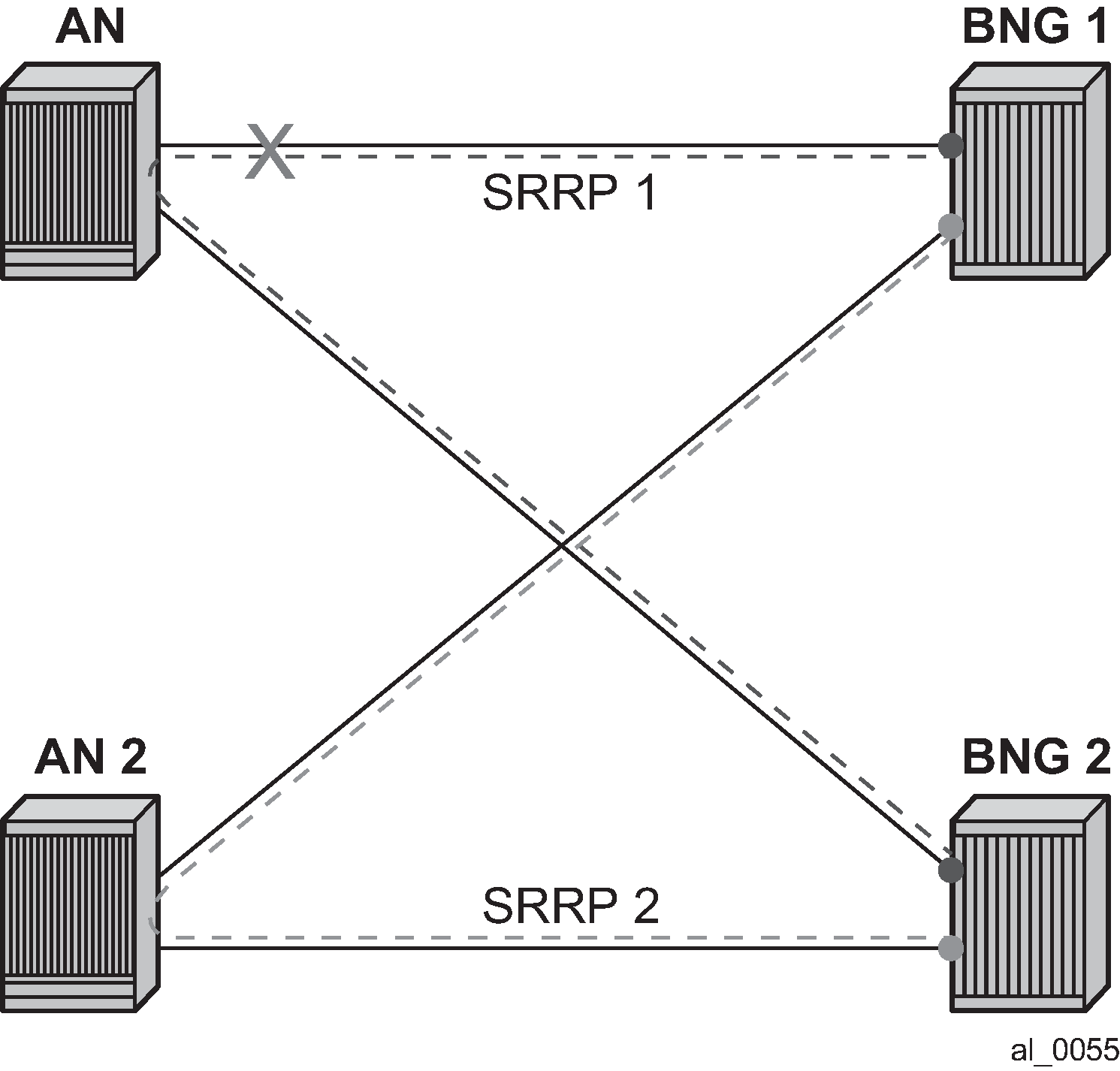
-
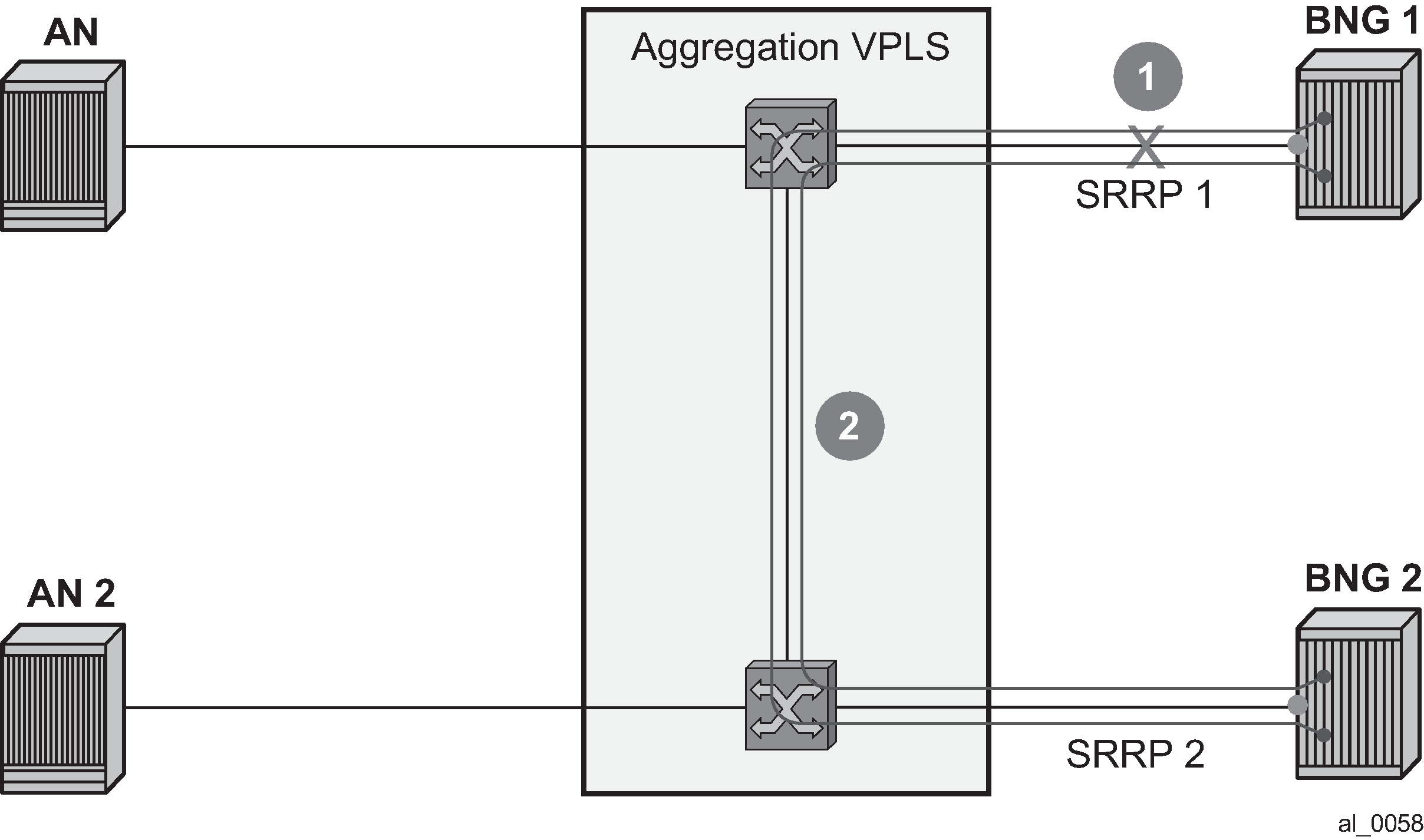
Dual homing with aggregation network - aggregation network has no redundancy between Layer 2 switches (STP). To determine whereabouts of failure at point 1 in Figure: Scenario 2, Eth-OAM is needed.
Figure: Scenario 2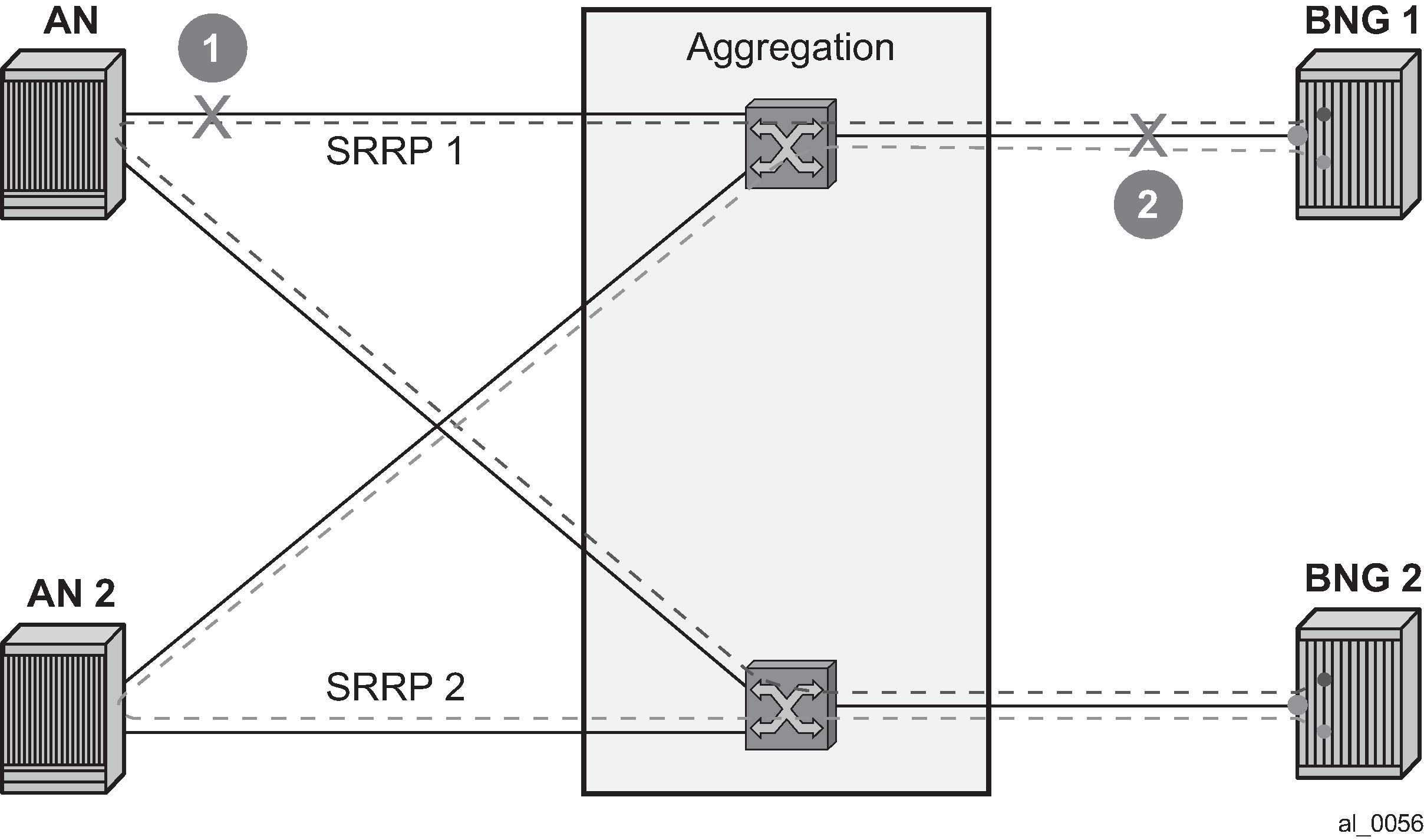
-
Dual homing with aggregation network - aggregation network with redundancy between Layer 2 switches (STP). No Eth-OAM is needed in this case for successful operation. However, the failure detection is based on the failure of the directly attached ports.
Figure: Scenario 3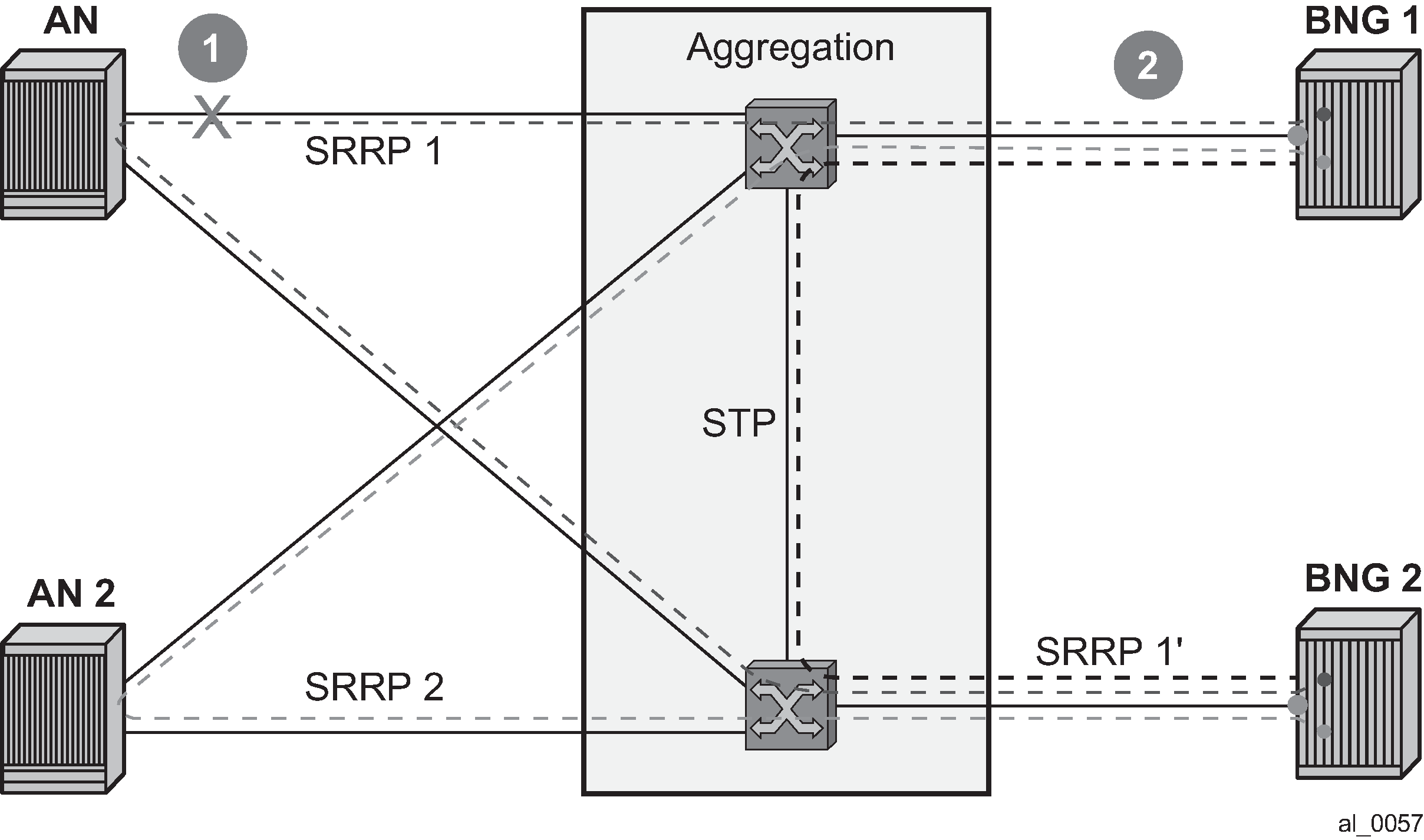
-
Single homing with aggregation network. In this case, SRRP can protect only against direct failures. Any remote failure leaves a part of the network isolated from the subscriber point of view.
Figure: Scenario 4